DeepSeek 本地部屬 | llama.cpp 與 ollama
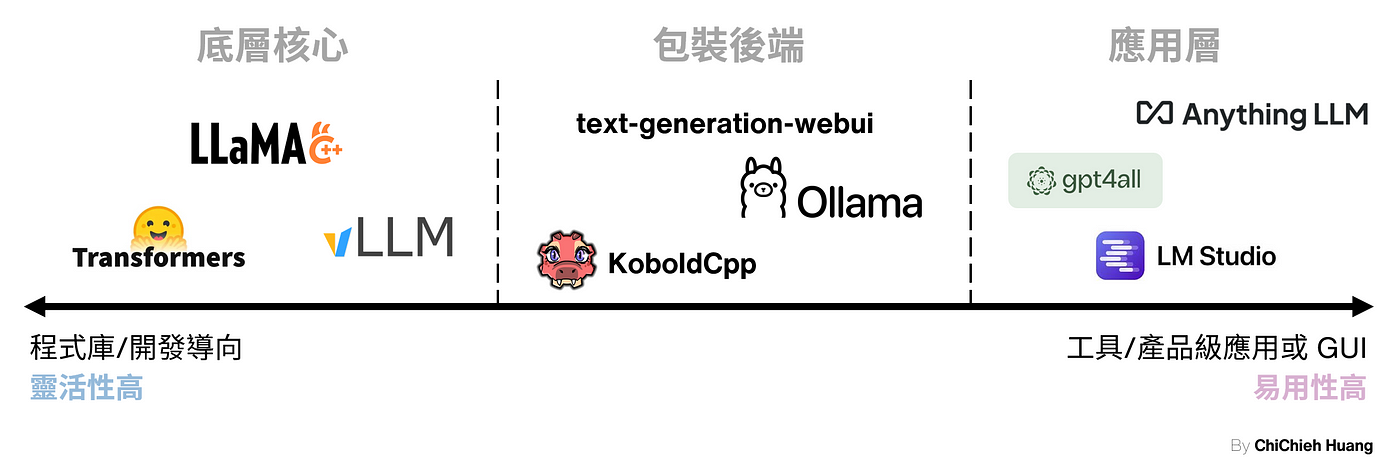
DeepSeek 近期在 LLM 領域的發展炙手可熱,吸引了全球關注。在這篇文章我們使用較具彈性 llama.cpp,以及易於安裝 Ollama,一步一步帶大家示範如何快速在本地部屬 DeepSeek-r1 模型。
DeepSeek 近期在 LLM 領域的發展炙手可熱,吸引了全球關注。在這篇文章我們使用較具彈性 llama.cpp,以及易於安裝 Ollama,一步一步帶大家示範如何快速在本地部屬 DeepSeek-r1 模型。
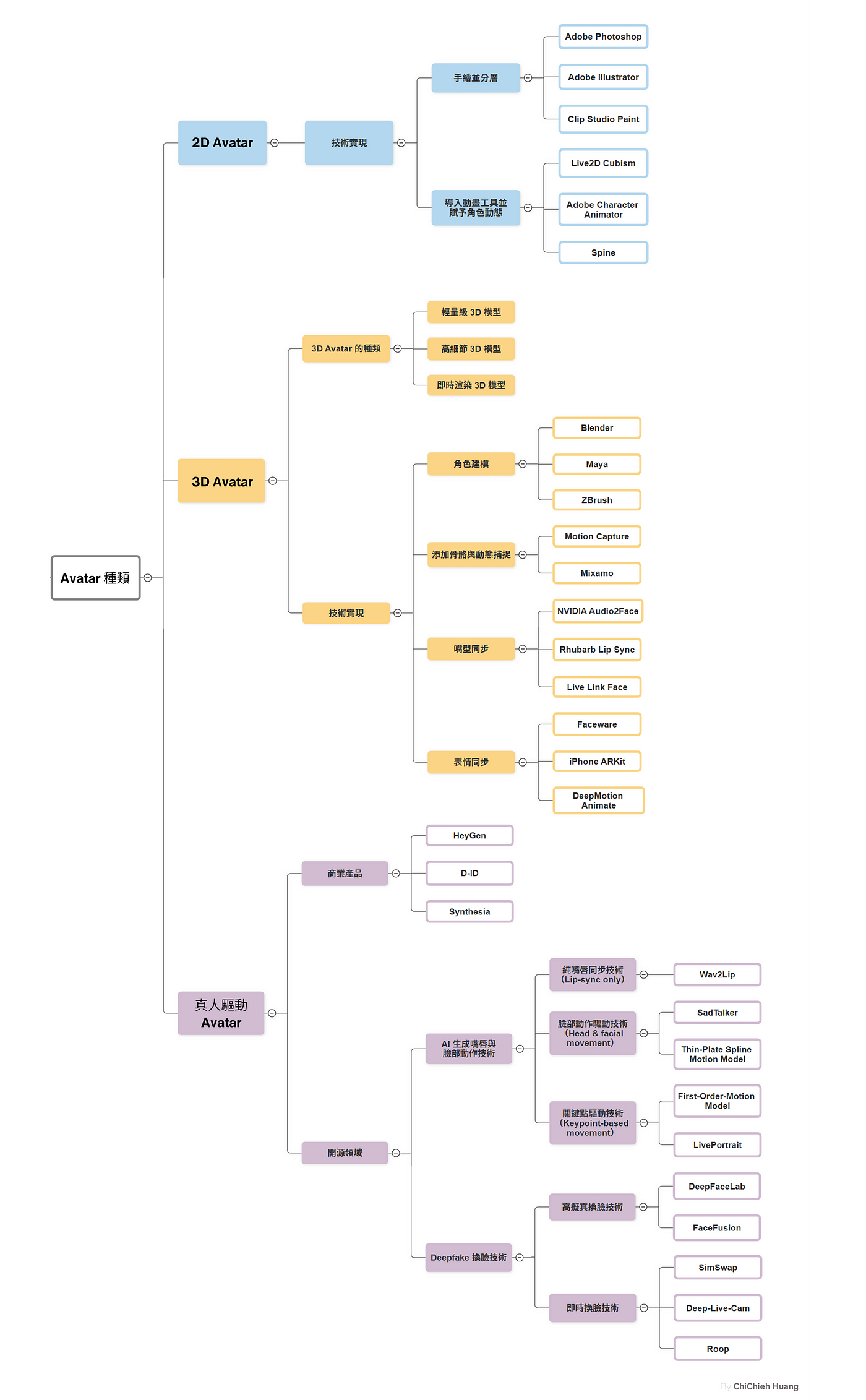
虛擬人偶(Avatar)早已是我們數位生活中的一部分,從遊戲角色到社交媒體的個性化形象,它們一直以多種形式出現在不同場合。然而,隨著 GenAI 的強勢崛起,AI 驅動的 Avatar(AI…

這篇文章便是希望帶大家一起操作,如何在 Microsoft GraphRAG 中使用llama.cpp 架設的地端 LLM 伺服器,主要會分成兩步驟: A. 啟動 llama.cpp 伺服器 B. Microsoft GraphRAG
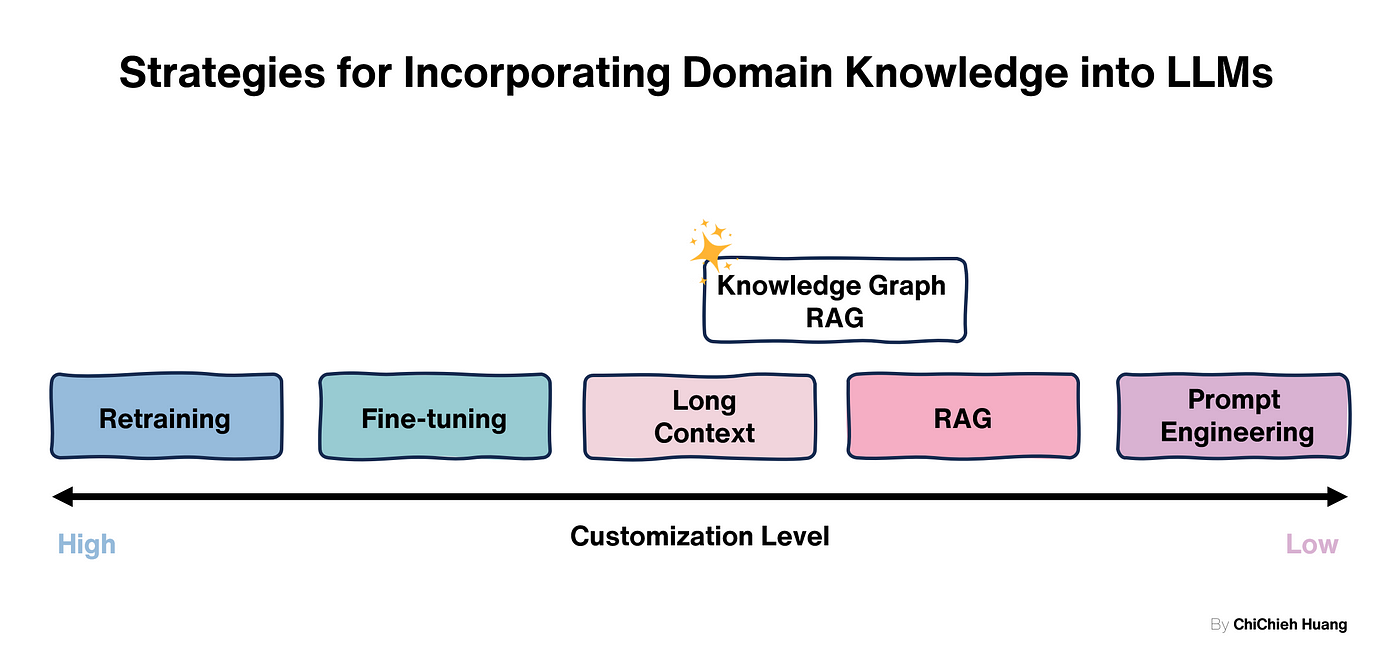
探索 Microsoft GraphRAG 結合 Knowledge Graph 與 RAG 的強大技術,提升模型答案品質。了解其實作與視覺化教學,掌握實作步驟與最佳方法,讓您的企業問答系統更精確高效。立即閱讀,快速上手 GraphRAG,掌握資料檢索和問答技術的最新發展。
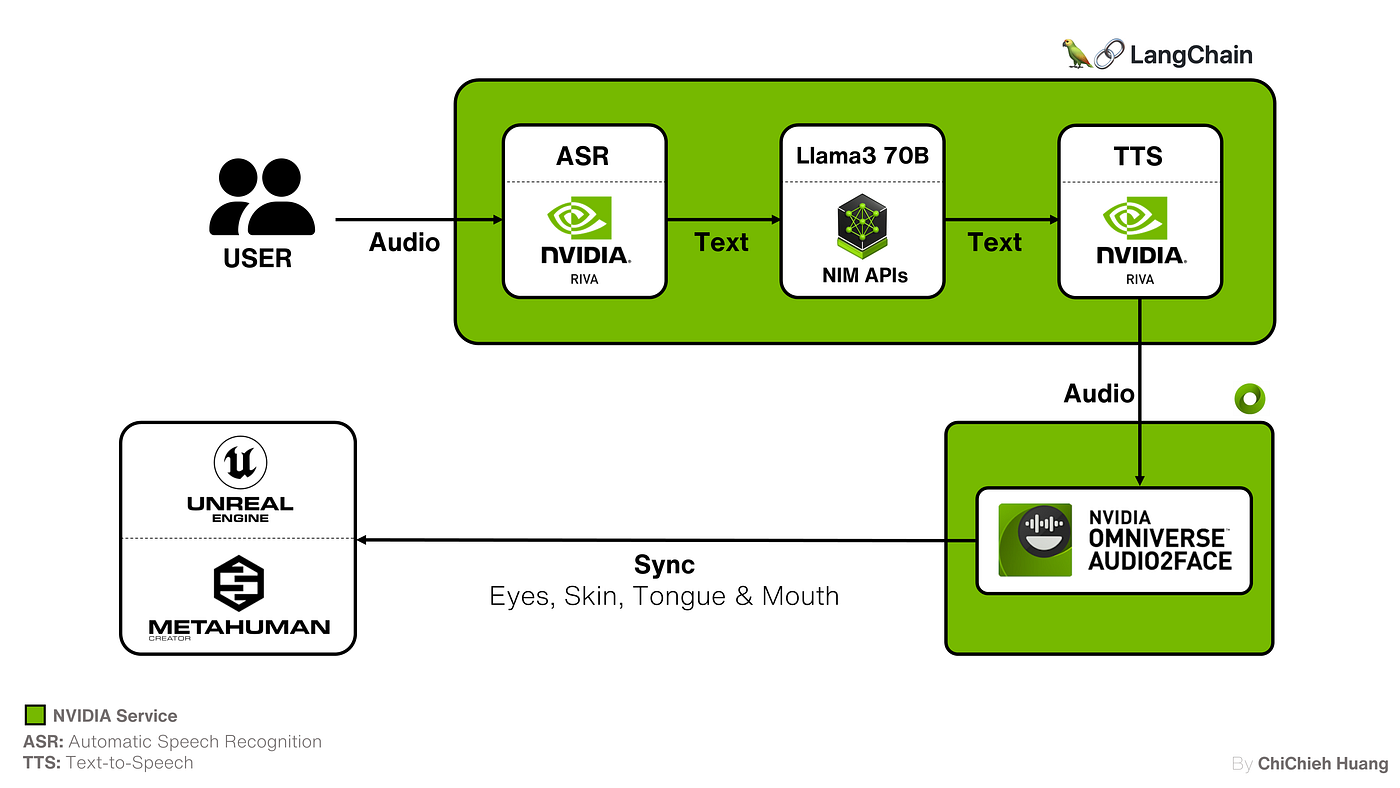
教學如何整合自動語音識別(ASR)、大型語言模型(LLM)、文字到語音(TTS)、LangChain 和音頻驅動的面部動畫(Audio2Face)與虛幻引擎的 Metahuman等技術,創建你的個人互動式 AI 虛擬助理。

在上一篇文章中,我們探討了評估大型語言模型評估時應考慮的各項指標和細節。而這篇文章中,我們將深入探討如何具體操作去評估 LLM。這篇我們使用的工具框架是 EleutherAI 的 lm-evaluation-harness,以下會帶你一起實機操作。
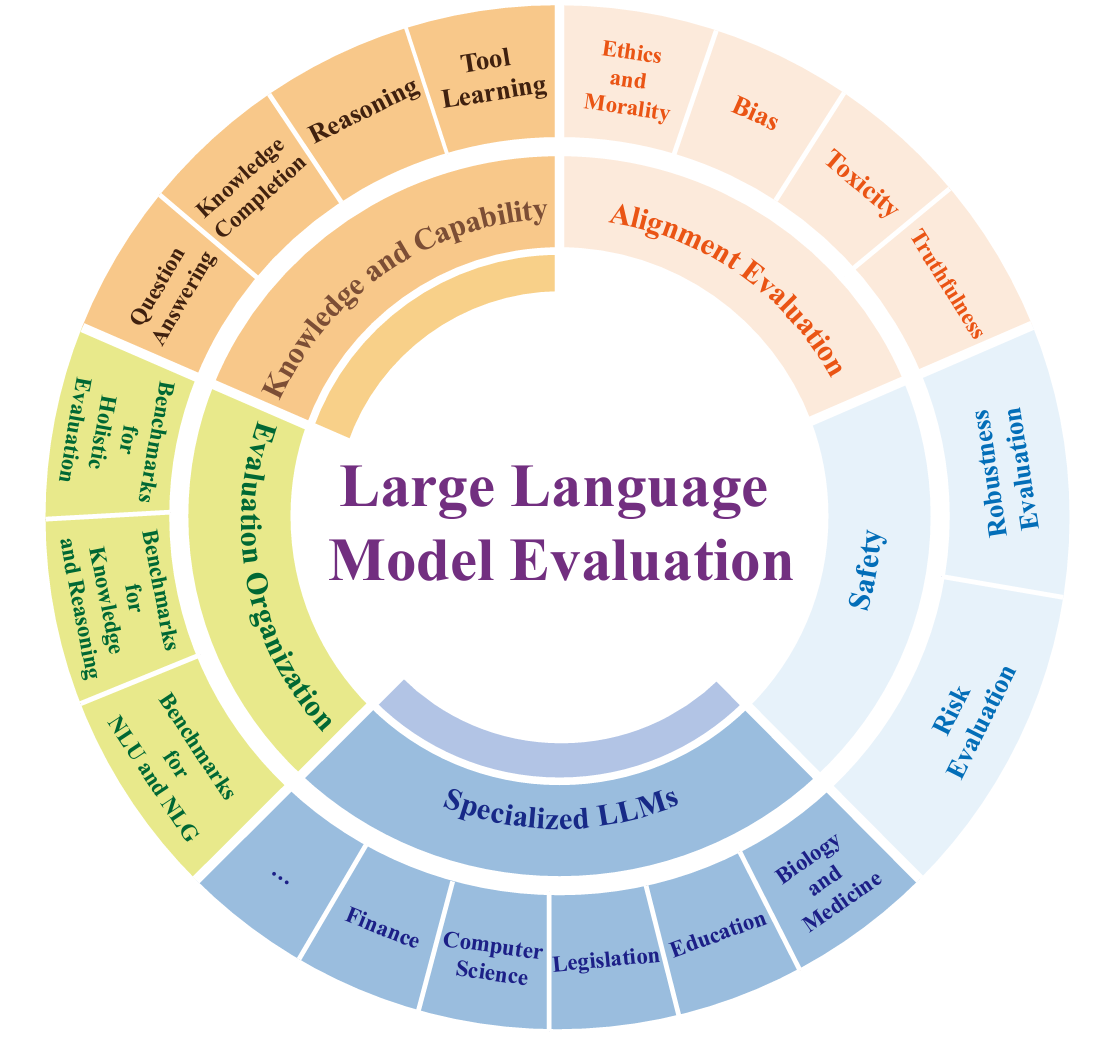
在過去的幾年裡,LLM 在自然語言處理 NLP 領域取得了驚人的進步,成為許多應用的核心技術,包括自動回答系統、文本生成、翻譯等等。隨著這些模型能力日益增強,確保模型既準確又公正就顯得非常重要,而這就引伸出一個根本性的問題:我們怎麼評估模型好不好?
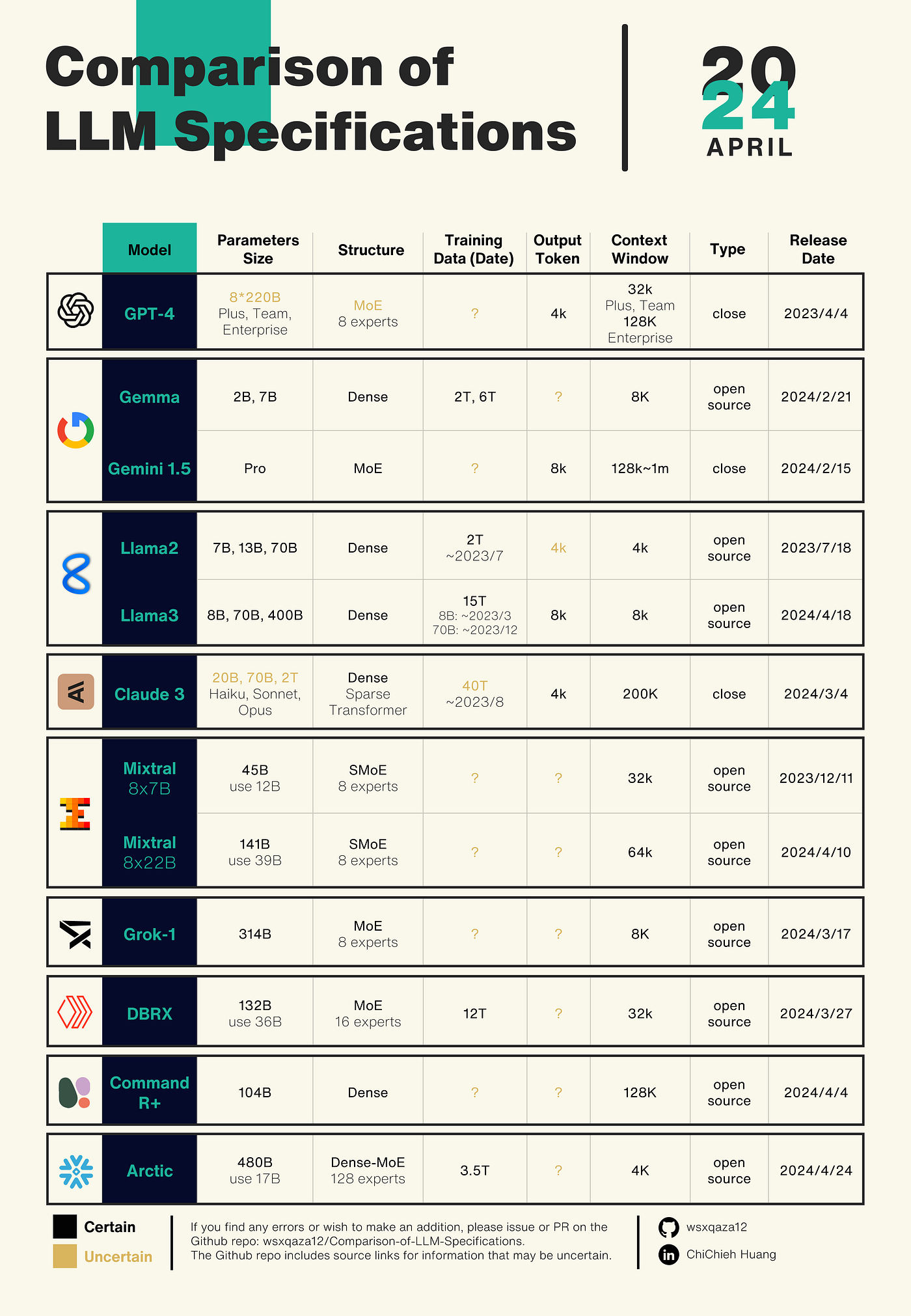
最近,Gemini 1.5 和 Claude 3 先後發布使的各種 LLM 的規格變得越來越複雜,因此我決定花時間來整理一份最新的規格比較表,其中包含 OpenAI、Google、Anthropic、Meta 以及 Mistral AI 的模型。
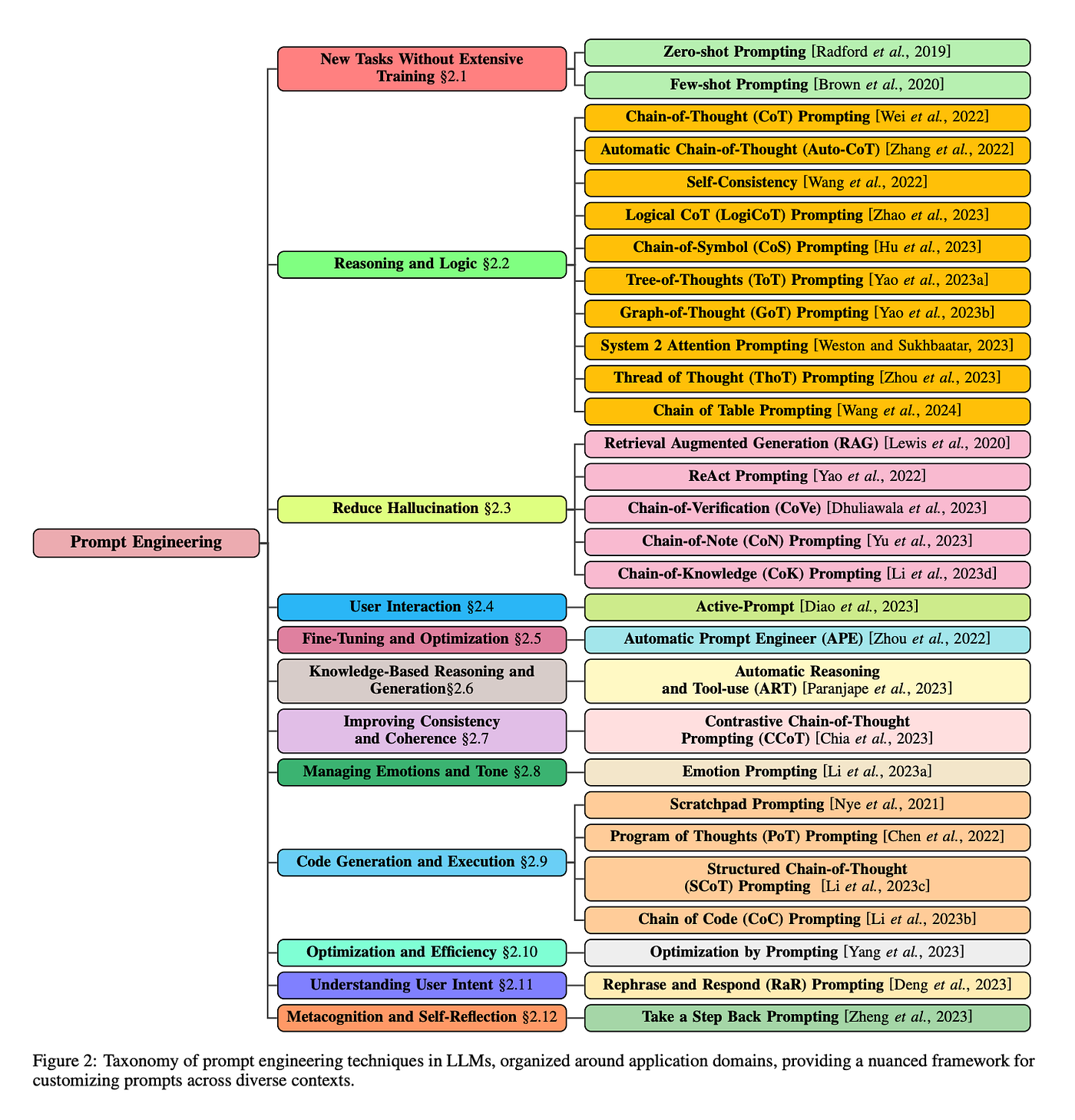
截止至今,關於 LLM 的優化與技巧層出不窮,幾乎每個月都有新的技術和方法論被提出,因此本篇主要是要介紹在各種不同情境下,LLM 的各種 Prompt Engineering (提示工程) 技巧,每篇都有附上論文連結與架構圖,方便你快速檢閱,希望能助幫你深入了解。
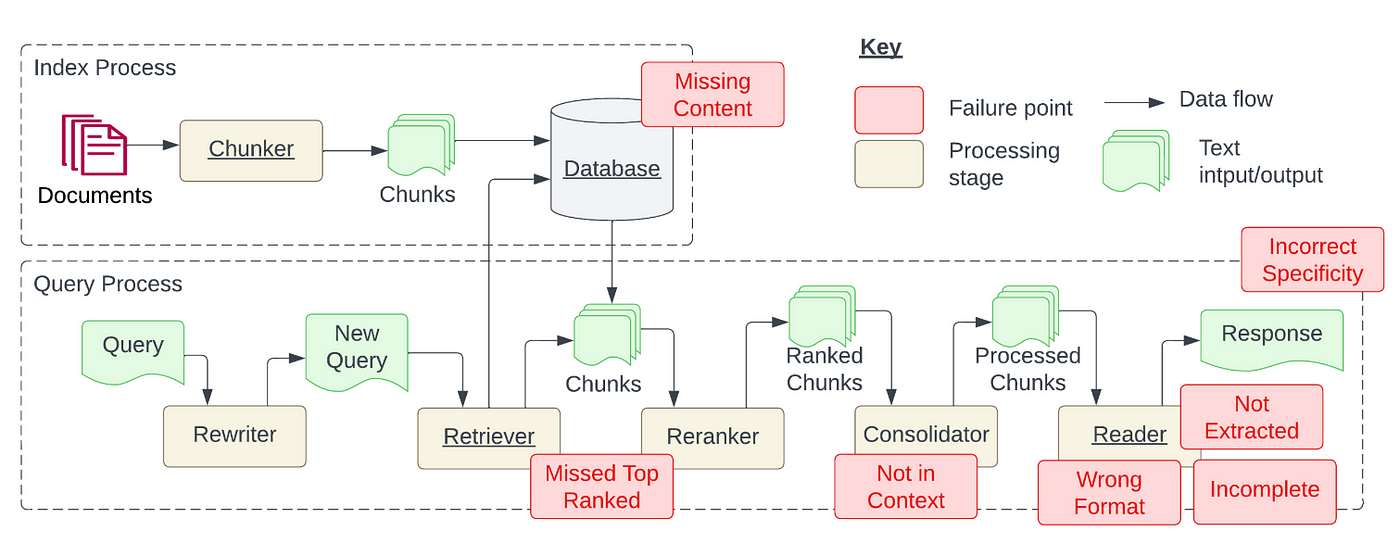
儘管 LLM + RAG 的能力已經令人驚嘆,但我們在使用 RAG 優化 LLM 的過程中,還是會遇到了許多挑戰與難題,包括但不限於檢索器返回不準確或不相關的資料,以及LLM基於錯誤或過時資訊生成答案的情況,因此本文旨在提出 RAG 常見的 7 大挑戰,與其各自的優化方案。