
記憶體不夠? 來看 LLM 的壓縮技術
本篇探討 LLM 的 4 種類型的壓縮技術:剪枝(Pruning)、知識蒸餾(Knowledge Distillation)、量化(Quantization)、低秩因子分解(Low-Rank Factorization)
本篇探討 LLM 的 4 種類型的壓縮技術:剪枝(Pruning)、知識蒸餾(Knowledge Distillation)、量化(Quantization)、低秩因子分解(Low-Rank Factorization)
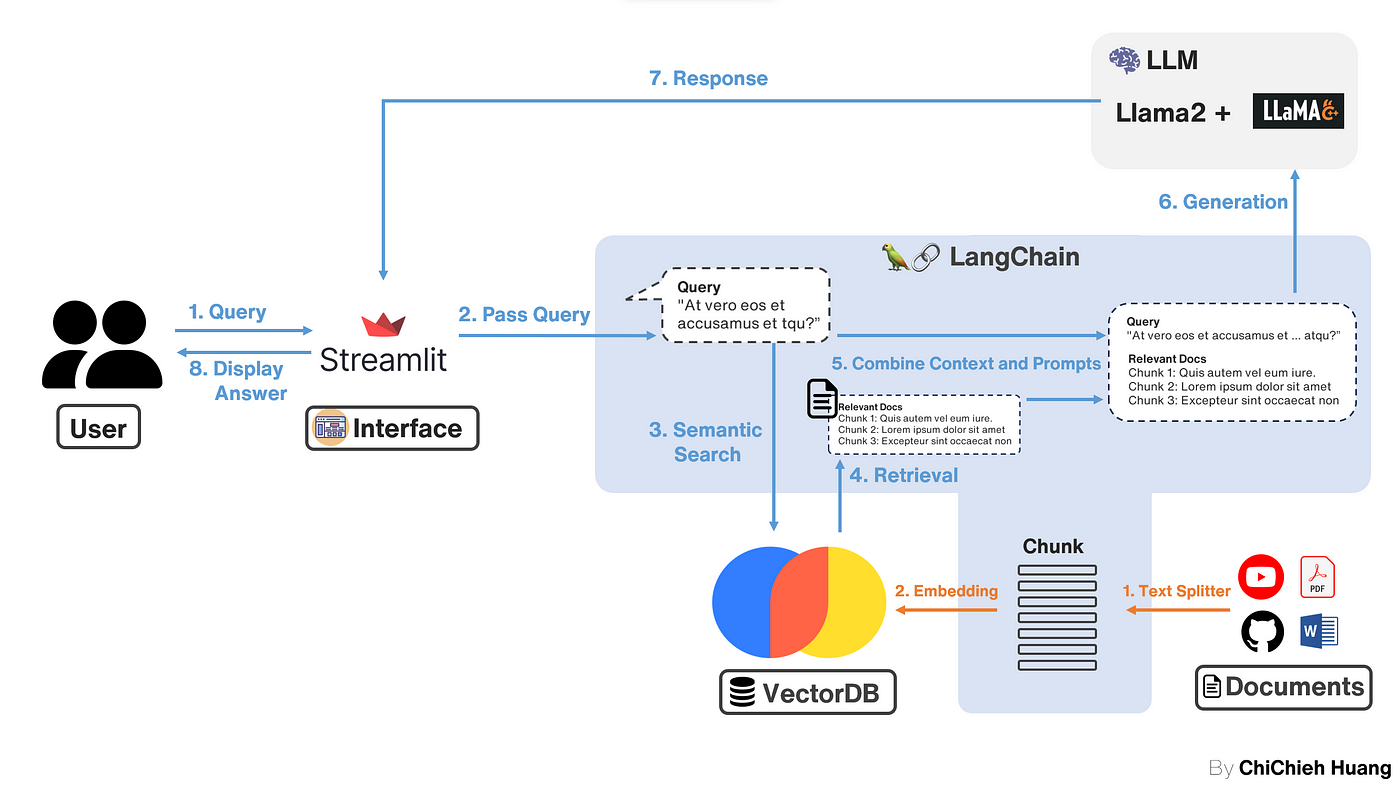
我們將重點放在如何使用 Streamlit 來建立一個視覺化的操作介面,以便 Demo 整個RAG(Retrieval-Augmented Generation)的工作流程。
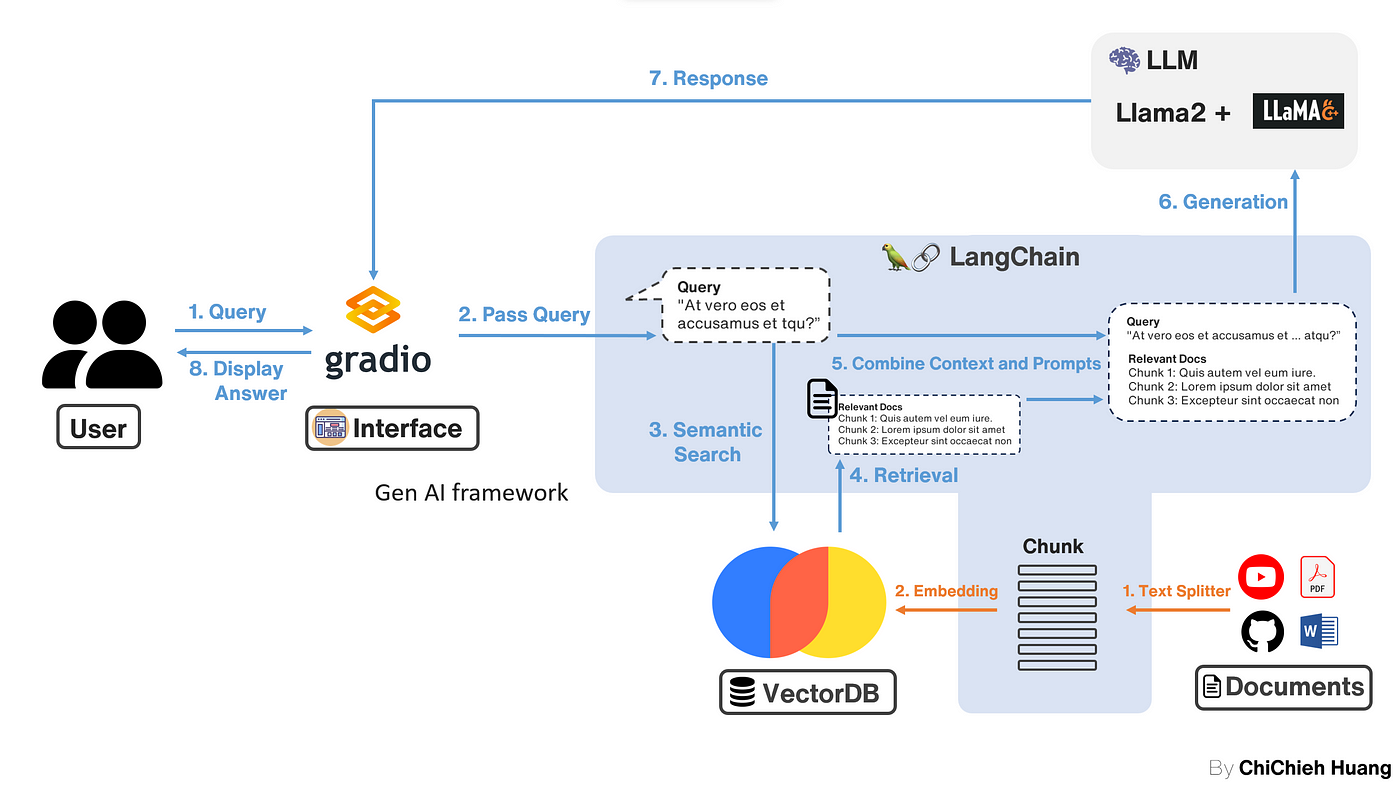
在這篇文章中,我們將帶你使用 LangChain + Llama2,一步一步架設自己的 RAG(Retrieval-Augmented Generation)的系統,讓你可以上傳自己的 PDF,並且詢問 LLM 關於 PDF 的訊息。
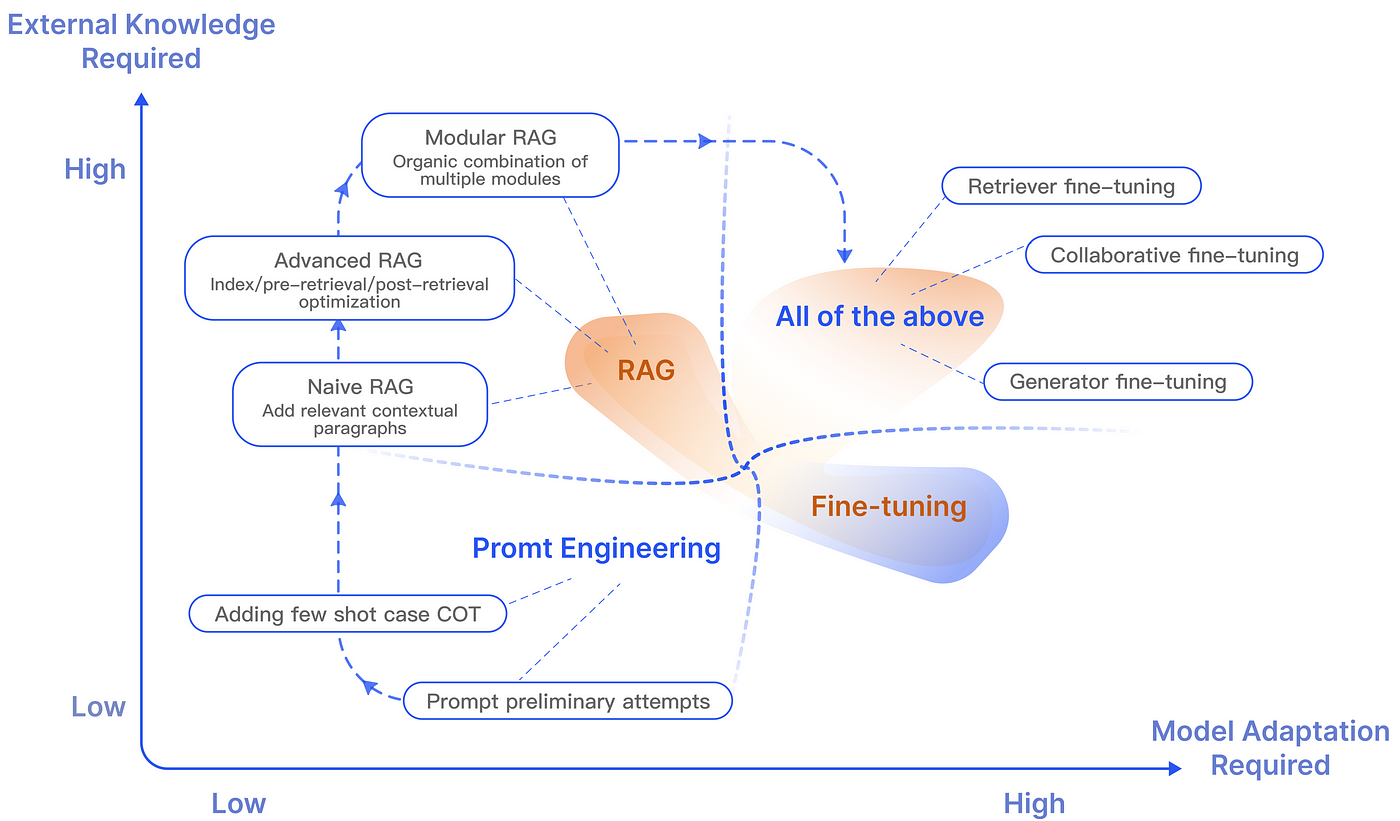
近期 RAG 的研究發展

使用 llama.cpp 建立屬於你的 LLM

Hugging Face | transformers | Apache-2.0 | LLM | 開源 | 教學

一步一步下載使用 Llama2 教學

OpenAI | ChatGPT-4 vs chatGPT-3.5

Pull Request (PR) | fork 一個專案到最後的提交 | 同步原始專案

Clustering Algorithms | 聚類演算法 | K-means | Affinity Propagation | GMM | DBSCAN | BIRCH