LLM 評估方法指南:趨勢、指標與未來方向
在過去的幾年裡,LLM 在自然語言處理 NLP 領域取得了驚人的進步,成為許多應用的核心技術,包括自動回答系統、文本生成、翻譯等等。隨著這些模型能力日益增強,確保模型既準確又公正就顯得非常重要,而這就引伸出一個根本性的問題:我們怎麼評估模型好不好?
LLM 評估方法指南:趨勢、指標與未來方向
在過去的幾年裡,LLM 在自然語言處理 NLP 領域取得了驚人的進步,成為許多應用的核心技術,包括自動回答系統、文本生成、翻譯等等。隨著這些模型能力日益增強,確保模型既準確又公正就顯得非常重要,而這就引伸出一個根本性的問題:我們怎麼評估模型好不好?
為了回答這個問題,我綜合了幾篇文獻的內容,來探討評估的演進、方法、項目與未來展望,希望能幫助你了解目前 LLM 評估環境。
一. 評估的演進
在近幾年中,隨著 LM 模型不斷進步,評估的方法在這幾年不停轉變,從早期的簡單任務和 benchmark,進化到涵蓋廣泛性能指標的綜合評估體系。
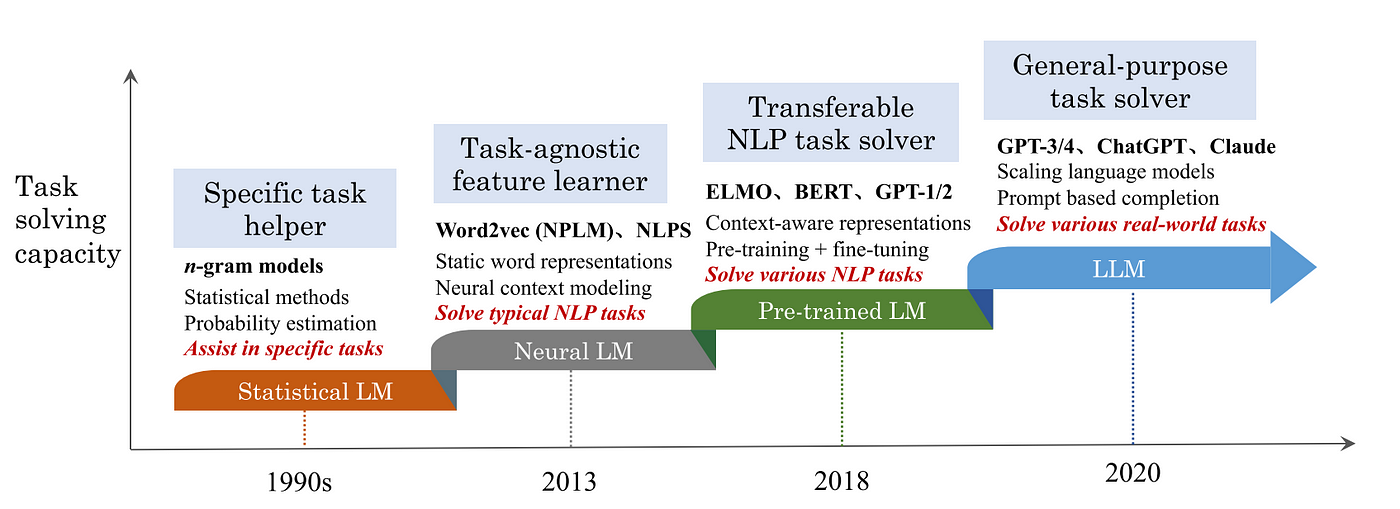
Zhao et al. (2023) A Survey of Large Language Models.
早期,研究人員主要關注模型在特定語言理解任務上的表現,例如語句補全、閱讀理解和問答系統的準確率。隨著技術的進步,人們開始意識到僅依賴這些指標無法全面評估 LLM 的能力。因此,評估體系開始包括更多面向,如模型的一般性知識、邏輯推理能力、創造力、甚至是對偏見和倫理問題的敏感性等。而近期 RAG 的興起,更是衍伸出一套評估 RAG 的方式,這將在之後的文章會探討。
二. 評估的項目
如上述提到,過往的評估項目已不足以全面性評估 LLM 的功能,因此根據 Guo et al. (2023) 最新的研究,除了傳統常考量到 Capability 與 Alignment 外,在評估 LLM 時我們也能從以下幾個關鍵維度進行:
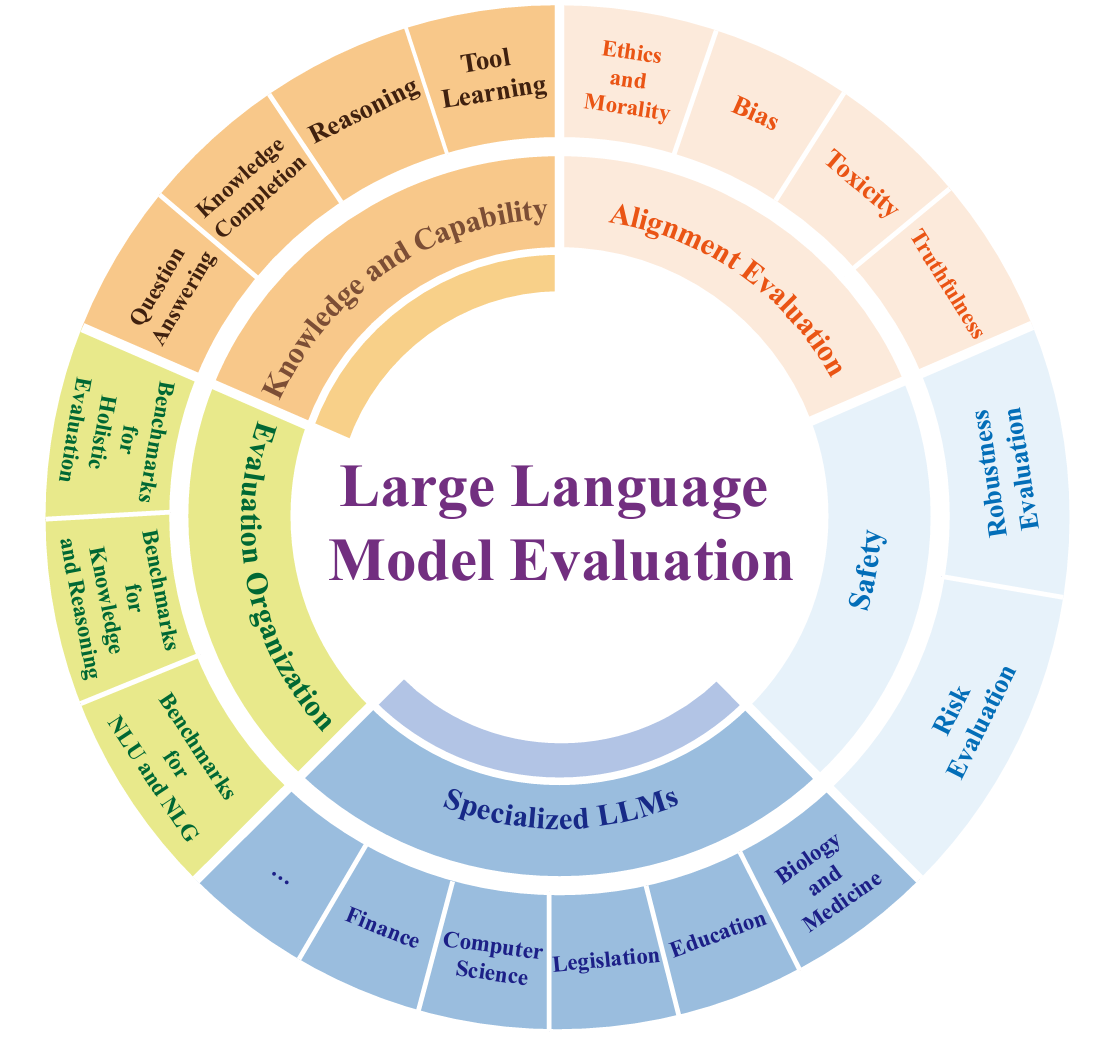
Guo et al. (2023) Evaluating Large Language Models: A Comprehensive Survey.
- Knowledge and Capability Evaluation: 包含了對模型在理解和產生語言方面能力的評估,如問題回答、知識完整性和推理等方面。
- Alignment Evaluation: 著重於評估模型的輸出是否符合倫理標準和社會期望,比如對偏見、毒性和信任度等。
- Safety: 著重模型是否會產生損害用戶或系統安全的輸出,如可能帶來的風險評估,或 LLM 在面對錯誤輸入和惡意攻擊時的穩定性與可靠性。
- Specialized LLMs Evaluation: 評估 LLM 的多元專業領域能力與限制,包含生物、教育、法律、計算機科學及金融等特定領域。
- Evaluation Organization: 評估 LLM 所用的主流基準和方法論,旨在幫助用戶根據特定需求,做出明智知情的選擇。
Guo et al. (2023) 有針對各個維度的評估方式做了深度的研究,以下列出各維度評估方式的整理,如果想看各 paper 的細節整理可以到他們的 GitHub ,我使用螢光筆標出較常見到的評估方式,另外注意每個評估項目所使用的指標都有所不同:
1. Knowledge and Capability Evaluation
一般最常聽到的評估項目,涵蓋 QuestionAnswering, Knowledge Completion, Reasoning 與 Tool Learning。
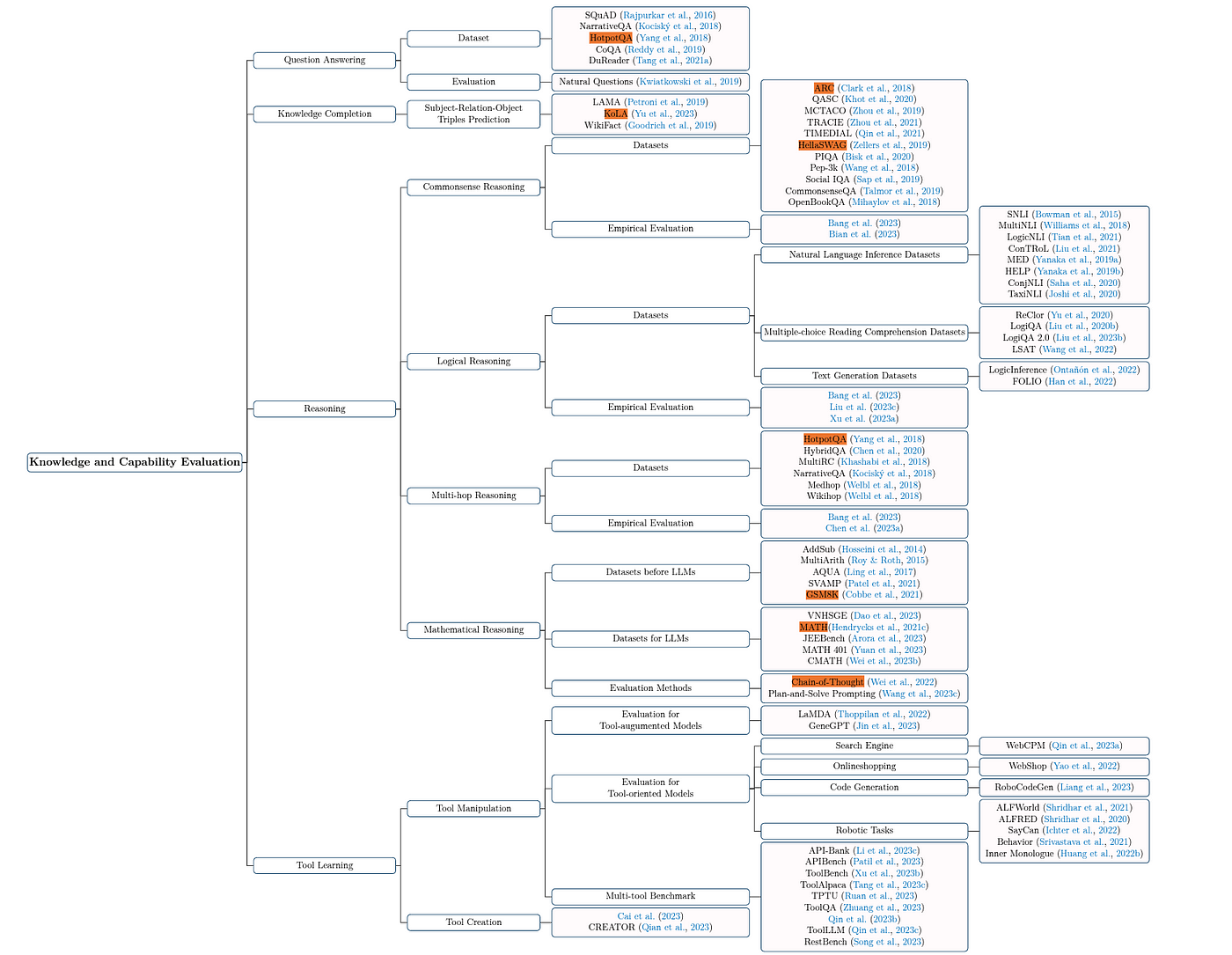
Guo et al. (2023) Evaluating Large Language Models: A Comprehensive Survey.
2. Alignment Evaluation
這項目著重在確保 LLM 的發展與人類社會價值觀保持一致,涵蓋 Ethics and Morality, Bias, Toxicity 與 Truthfulness 等議題:
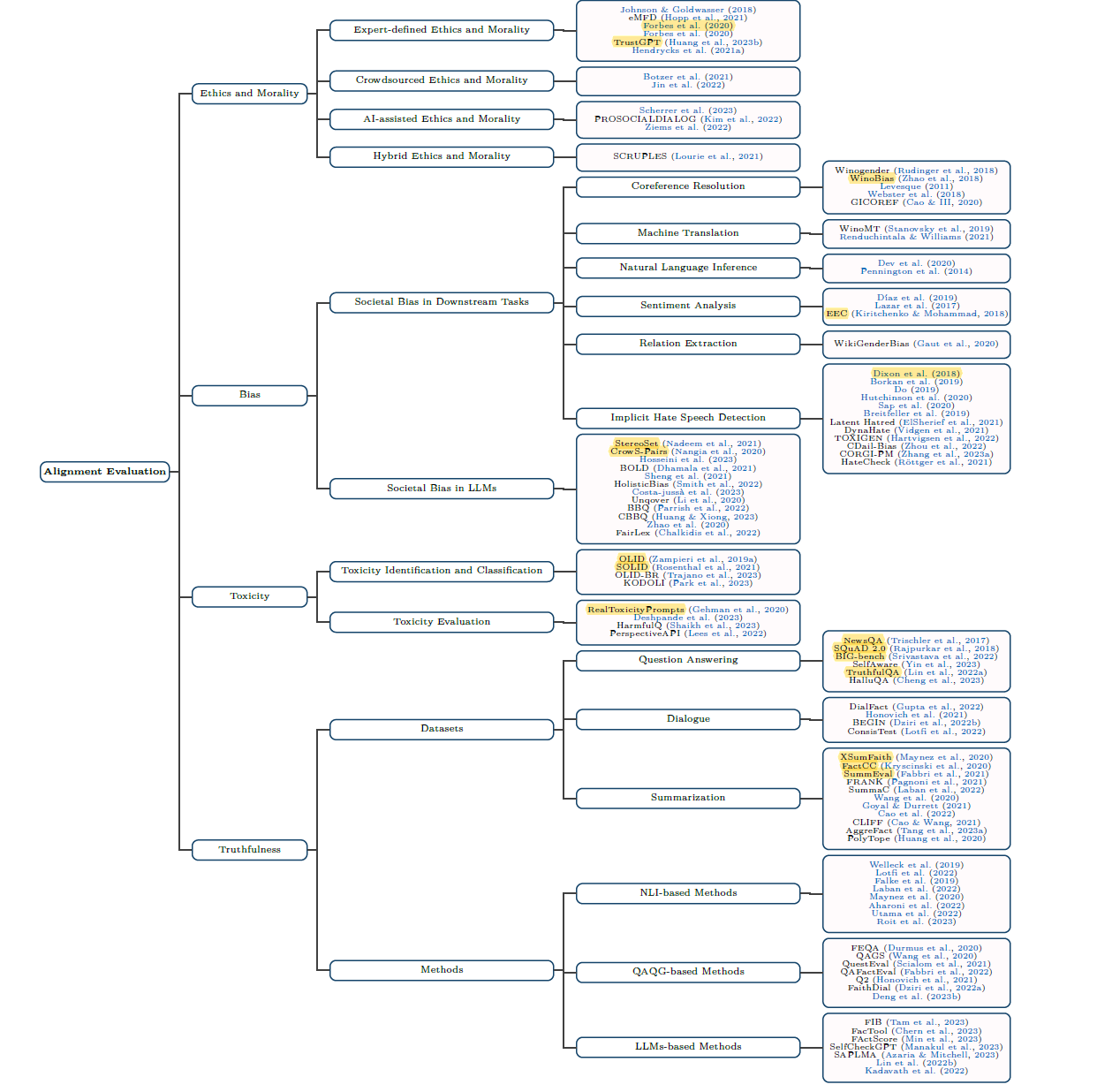
Guo et al. (2023) Evaluating Large Language Models: A Comprehensive Survey.
3. Safety
為確保 LLM 能在各種應用場景中安全使用,通常會評估 Robustness Evaluation 與 Risk Evaluation。
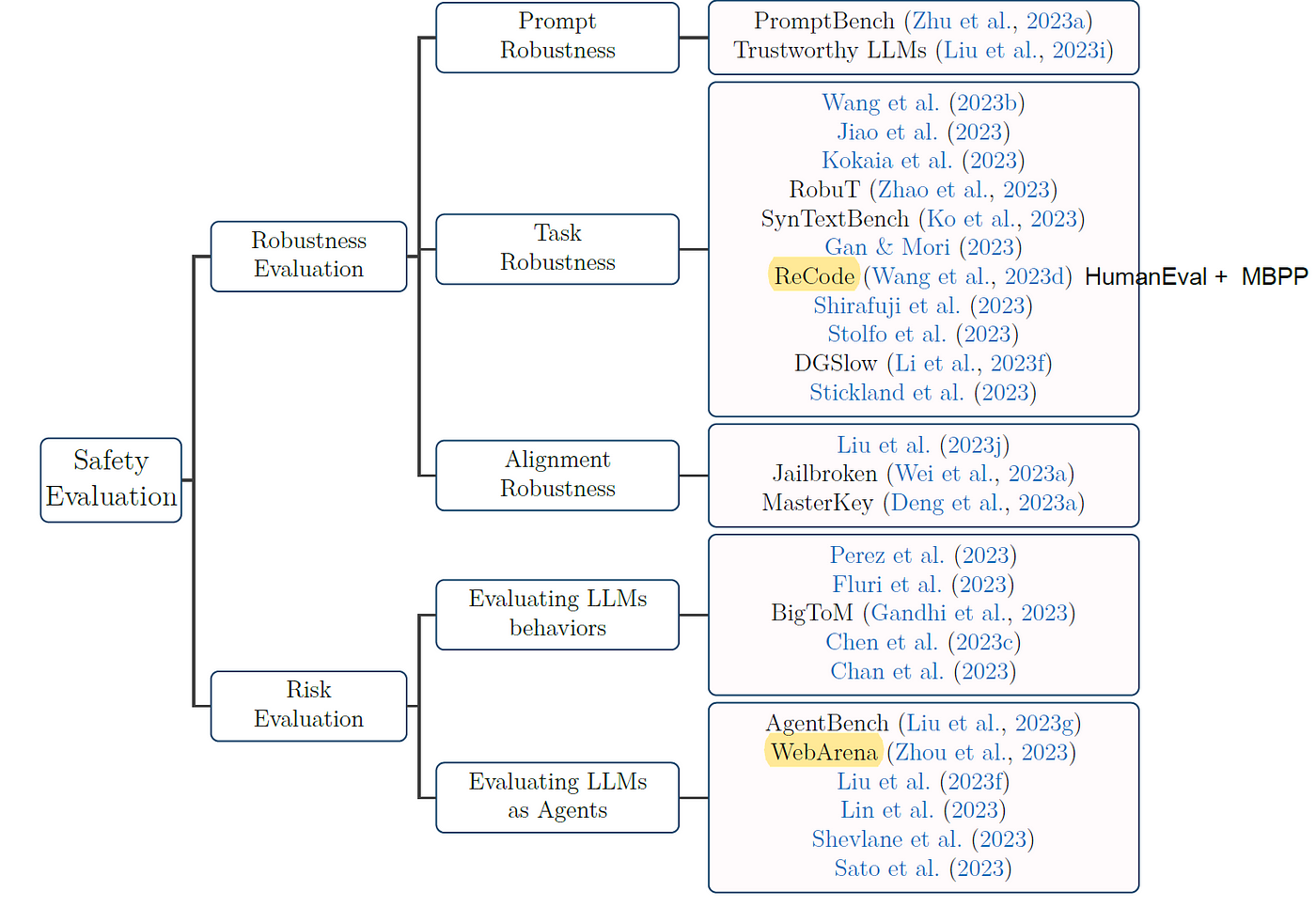
Guo et al. (2023) Evaluating Large Language Models: A Comprehensive Survey.
4. Specialized LLMs Evaluation
現在某些 LLM 會針對專業領域進行 fine-tuning,比起一般 LLM,這種模型更在意特定領域的評分,其中包含生物、教育、法律、計算機科學及金融等領域。
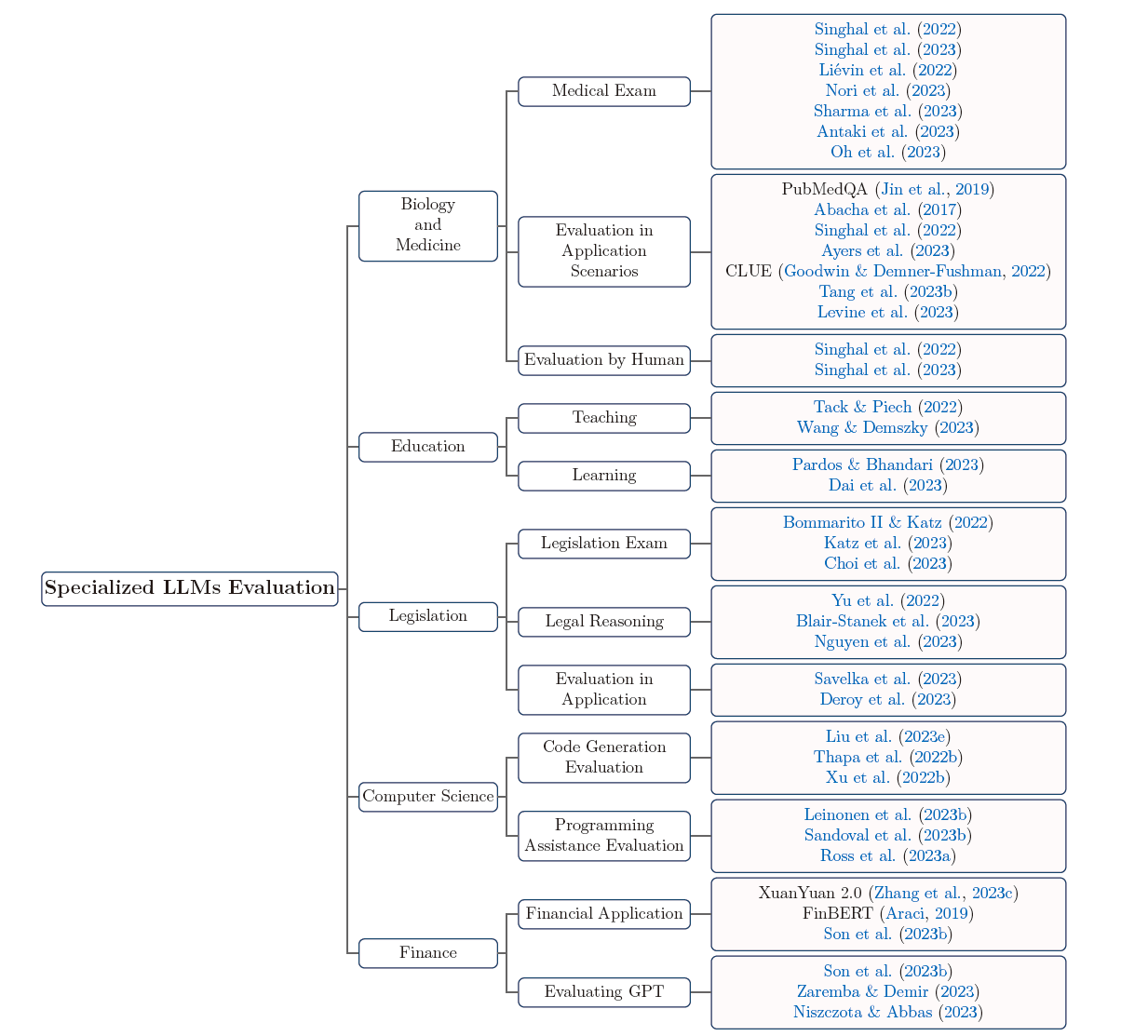
Guo et al. (2023) Evaluating Large Language Models: A Comprehensive Survey.
5. Evaluation Organization
著重在 LLM 的綜合性評測,涵蓋早期的 NLU 與 NLG 類型任務,到學科能力評測 benchmark,最後是各種 Leaderboard 與 Elo score 等。
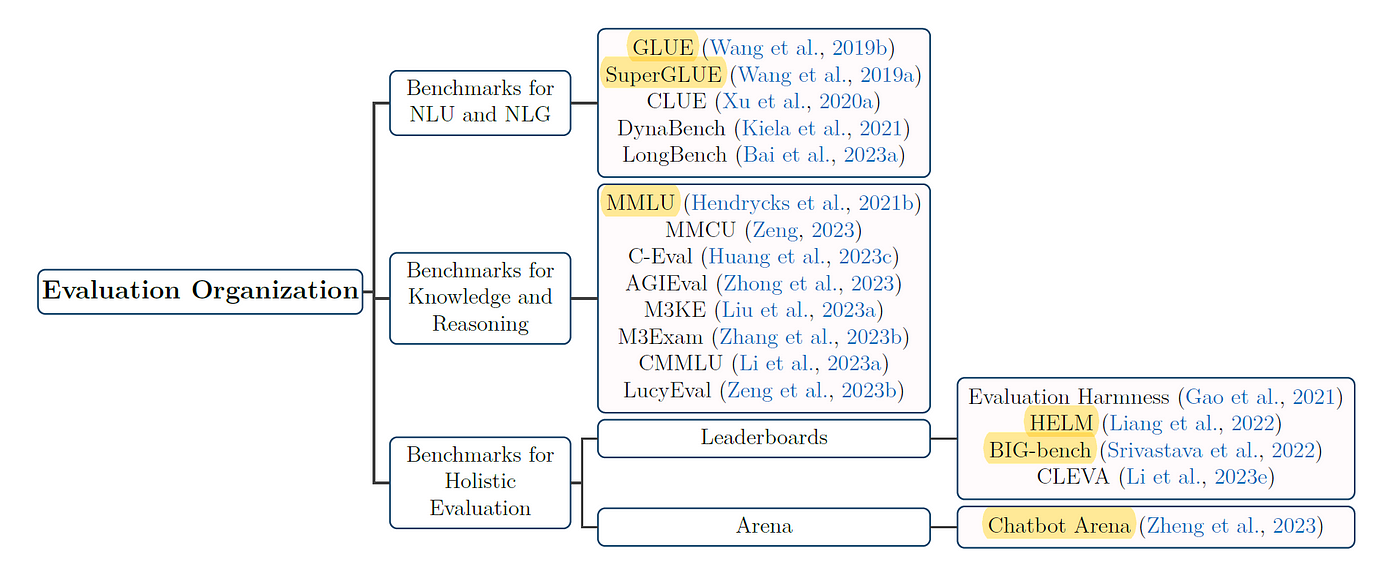
Guo et al. (2023) Evaluating Large Language Models: A Comprehensive Survey.
三. 評估的指標
一般在探討 LLM 系統評估時,應根據應用場景不同訂定不一樣的指標,以符合特定目標和需求,因此以上評估項目所使用的指標皆不太相同,你應可以在各個評估項目的文件中找到他們所評估的指標,以下列舉幾個應用領域及其相應的評估指標:
- Machine Translation : 主要目標是生成準確且連貫的翻譯,常用的評測指標包括 BLEU 和 METEOR 。
- Automatic Summarization : 在評估機器生成的摘要與人類參考摘要之間的相似度時,通常會使用 ROUGE。
- Sentiment Analysis : 目的在於理解文本並準確回答有關該文本的問題,因此會優先考慮 Accuracy 、 Recall 和 F1 score 等指標。
- Machine Reading Comprehension: 常使用 EM 與 F1 score , EM 衡量模型答案與正確答案的完全匹配程度,而 F1 score 則考慮到了部分匹配情況,平衡了精確性和召回率。
- C ode Generation: 主要目標是基於自然語言描述自動生成符合要求的程式碼,通常使用 pass@k 與 Accuracy 。
四. 未來趨勢
根據各個文獻研究探討,我預計評估方法將會在以下幾個方面進一步演進和深化:
1. 跨模態和跨領域評估
隨著LLM技術的進步,模型不僅僅局限於文本處理,也越來越多地涉足圖像、音頻和視頻等跨模態處理。因此,未來的評估框架需要擴展,以包含跨模態理解能力和對特定領域知識的掌握程度。
2. 更細緻的倫理和安全評估
隨著公眾對AI倫理和安全問題的關注日益增加,評估 LLM 時對這些維度的考量將變得更加重要。現有的安全評測方法主要透過問答的方式對大模型進行評測,然而此方法難以全面評估大模型在特定場景或特定環境下的風險。
3. 人機互動和實際應用效能評估
評估 LLM 的另一個重要方向是其在真實世界應用中的表現,包括用戶滿意度、實際應用中的效能和經濟效益等。這需要從傳統的基於數據集的評估轉向更多融入人機互動場景和長期運行效果的考量。
4. 自動化和連續性評估
隨著模型迭代速度的加快,需要開發更多自動化的評估工具和框架,以支持對 LLM 的持續性評估和監控。現有的評測方法通常是靜態評測,其測試樣本總是長時間保持不變,因此測試樣本可能已經包含 LLM 的訓練資料中。
五. 參考文獻
- Guo, Z., Jin, R., Liu, C., Huang, Y., Shi, D., Supryadi, Yu, L., Liu, Y., Li, J., Xiong, B., & Xiong, D. (2023) . Evaluating Large Language Models: A Comprehensive Survey. ArXiv, abs/2310.19736 .
- Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., Liu, P., Nie, J., & Wen, J. (2023) . A Survey of Large Language Models. ArXiv, abs/2303.18223 .
- Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., Ye, W., Zhang, Y., Chang, Y., Yu, P.S., Yang, Q., & Xie, X. (2023) . A Survey on Evaluation of Large Language Models. ArXiv, abs/2307.03109 .
- Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M.A., Socher, R., Amatriain, X., & Gao, J. (2024) . Large Language Models: A Survey. ArXiv, abs/2402.06196 .
