深入解析 RAG 評估框架:TruLens, RGAR, 與 RAGAs 的比較
隨著 RAG 日益發展,有許多 RAG 的變形架構出現,使其成為一個越來越複雜的系統,需要全面性的評估方可監控其效能,提供後續的商業價值。因此,本文旨在探討我們如何全面且廣泛性的評估 RAG 系統,以及 RAG 評估框架的未來方向。
深入解析 RAG 評估框架:TruLens, RGAR, 與 RAGAs 的比較
一. 前言
在之前的 文章 中,我們介紹了目前 LLM 評估的趨勢與 教學 ,而近期隨著 LLM + RAG 應用的日益廣泛,RAG 已成為許多企業在使用內部文件的同時,避免產生幻覺的一種方法。然而,即使是 RAG 也可能會產生幻覺,這通常是因為檢索器無法檢索到有效的資訊,甚至可能檢索到不相關的資訊所導致,因此,為了有效地發現並防止這種情況,如何有效地評估 RAG 的回答,就成為當前需要解決的重要問題之一。
除此之外,隨著 RAG 日益發展,有許多 RAG 的變形架構出現,使其成為一個越來越複雜的系統,需要全面性的評估方可監控其效能,提供後續的商業價值。因此,本文旨在探討我們如何全面且廣泛性的評估 RAG 系統,以及 RAG 評估的未來方向。
Zhao et al. (2024) . Retrieval-Augmented Generation for AI-Generated Content: A Survey.
二. RAG 評估的挑戰
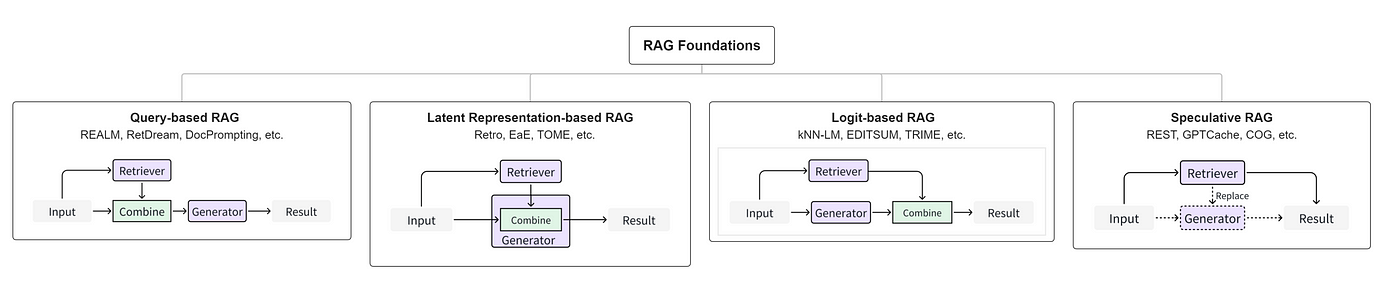
相對於較評估 LLM,RAG 評估的困難點在於 RAG 的 pipelines 由兩個關鍵技術組成:
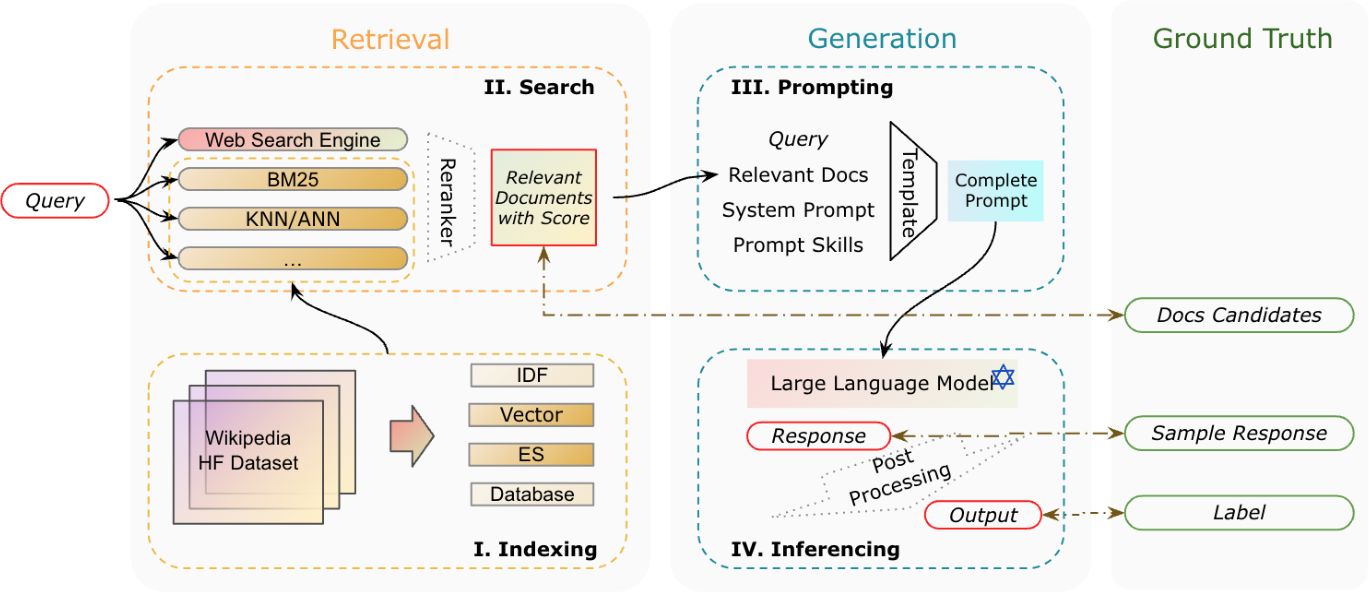
- 檢索(Retrieval): 從大量知識庫中檢索出相關的文件,包含 Indexing 與 Search 階段。
- 生成(Generation): 將檢索到的資訊轉成為自然流暢的文字,包含 Prompting 與 Inferencing 階段。
Yu et al. (2024) . Evaluation of Retrieval-Augmented Generation: A Survey.
因此在評估 RAG 時,我們必須考量到三個部分,Retrieval 與 Generation 以及整個 RAG 系統,如此才能有效地探討 RAG 系統中哪些方面需要改進。以下我們分別討論三個部分所面臨的挑戰:
1. Retrieval
檢索技術對於從外部知識源中獲取相關資訊至關重要,這些資訊也會影響到後續的 Generation。主要挑戰包括:
- 知識庫的動態和龐大性: 評估檢索需要有效測量 Precision、Recall 和Relevancy 的指標,面對龐大和動態的知識源,從結構化數據庫到整個網絡,這一挑戰尤其明顯。除此之外,資訊的 Relevancy 和 Precision 會隨時間變化,增加了評估的複雜性。
- 資訊來源的多樣性和質量: 資訊來源的多樣性,和檢索到誤導性或低質量資訊的潛在可能性,對於有效篩選和選擇最相關的資訊構成了重大挑戰。
- 評估方法改良: 傳統評估指標著重於較高的 TopK Recall,可能無法捕捉 RAG 系統檢索的資訊的實用性。評估應考慮有助於下一步 Generation 的信息質量和相關性。
2. Generation
Generation 通常由 LLM 完成,基於 Retrieval 的內容來生成回應,其所面臨的挑戰包括:
- Faithfulness 與 Accuracy: 評估生成內容對輸入數據的忠實度和準確性,包括評估回應的事實正確性、與原始查詢的相關性以及文本的一致性。創意內容生成或開放式問答等任務的主觀性增加了判斷高質量回應的變異性。
3. 整體RAG系統
除了個別考慮外,評估整個 RAG 系統需要考量到 Retrieval 和 Generation 之間的相互作用。挑戰包括:
- 整體性能: 系統利用檢索信息提高回應質量的能力需要測量,並考慮回應延遲、抗誤資訊的能力和處理模糊或複雜查詢的能力。
- 全面評估: 傳統的 end-to-end 評估方法缺乏對每個檢索文件貢獻的透明性,難以解釋系統行為並有效優化性能。
三. RAG 評估指標
由以上挑戰可知,為了全面評估RAG系統,我們需要使用多種指標來衡量各個方面的性能,目前有需多框架與工具提出各種不同的看法,以下帶大家一起看通用的準則。
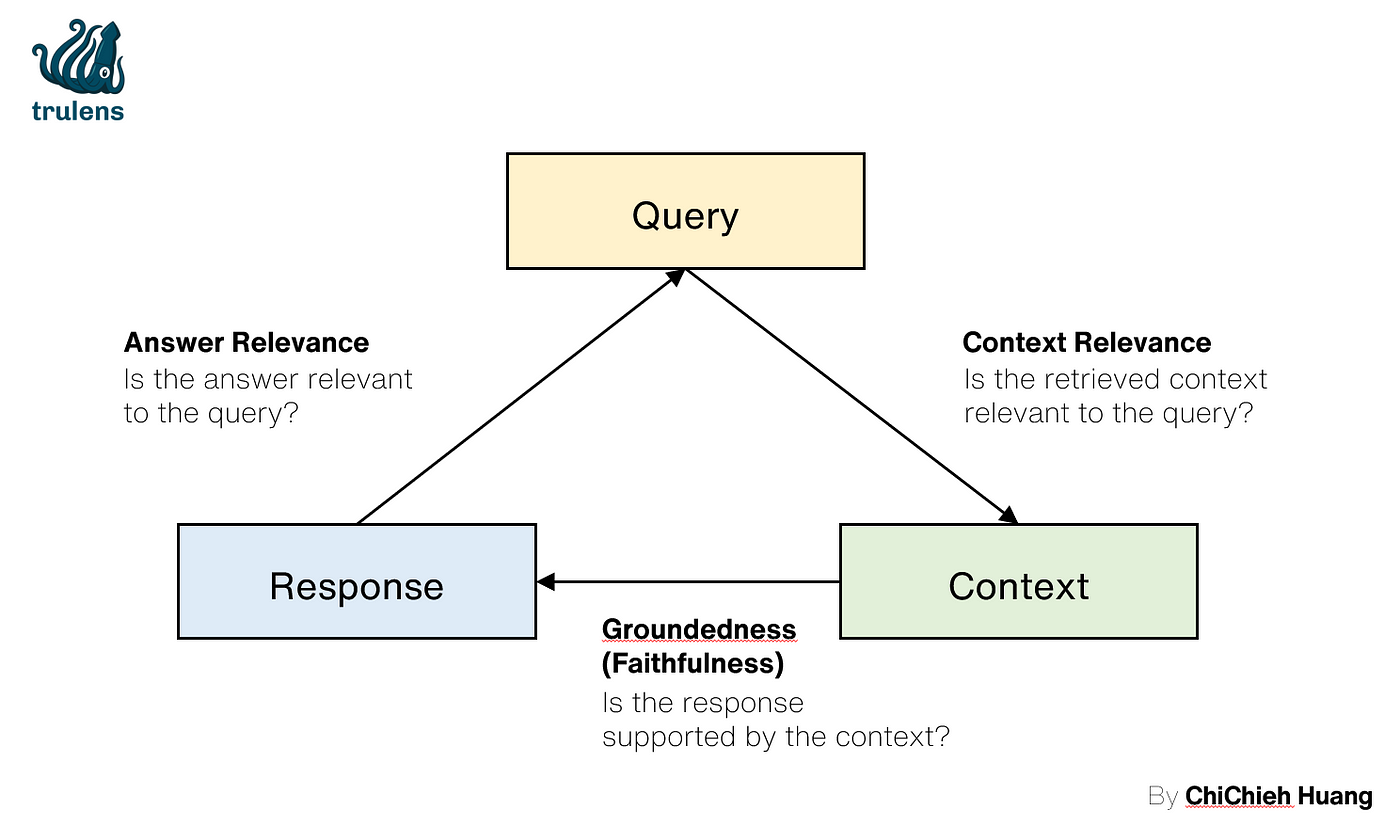
評估 RAG 系統中,大多數的框架都會提到以下的三角形準則,而 Trulens 便是採取這種架構在評估,以下參考 Trulens 的圖重新繪製一張方便大家理解:
Query: 表示使用者問的問題。Context: 為檢索到的上下文,大致對應到 RAG 的 Retrieval。Response: LLM 根據Context的最後回答,大致對應到 RAG 的 Generation。
RAG Triad — Referenced from Trulens
從這三角型中,可以直觀的看出 3 個應該評估的指標,以下分別介紹:
- Context Relevancy: 用於
Context與Query的相關性,範圍從 0 到 1,數值越高表示相關性越好。該指標計算的是上下文中與回答問題相關的句子數量佔總句子數量的比例。 - Groundedness: 有些框架稱其為 Faithfulness,用於評估
Response與Context的一致性,範圍為 0 到 1,數值越高表示一致性越高,主要用於檢測 LLM 幻覺。該指標通過識別Response中的聲明,並檢查這些聲明是否可以從Context中推斷出來,來計算 Groundedness 分數。 - Answer Relevancy: 評估
Response對Query的相關性。這個指標計算從生成答案反推得出的多個問題與原始問題之間的mean cosine similarity。高分表示Response直接且適當地回應了原始問題,而低分則表示答案不完整或包含冗餘資訊。
幾乎所有評估 RAG 的框架都會包含以上 3 種指標,但這 3 種指標僅考量到 Evaluable Outputs 之間的關係,並未考量到與 Ground Truths 之間的關係,也就是評估裡面並沒有 Ground Truths 來提供一個基準,然而這在 RAG 評估中,也是很重要的一環。
四. RAG 評估框架發展
有鑑於以上的框架並不能將 Ground Truths 引入,有一些新提出的框架在這個基礎上做發展,提出了該如何使用 Ground Truths,以及評估整體 RAG 系統的有效指標,以下帶大家看 2 個近期的框架:
1. RGAR
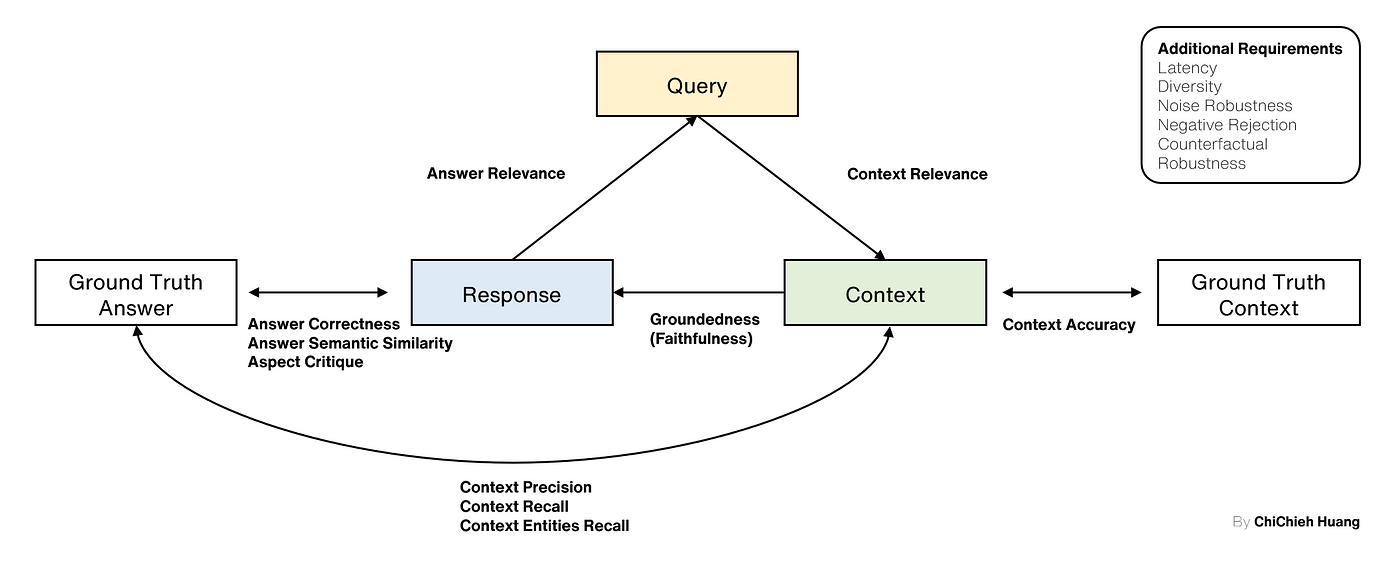
Yu et al. (2024) 提出 RGAR ( R etrieval, G eneration, and A dditional R equirement),旨在提供更好理解 RAG 基準的框架。該框架引入了 Ground Truths,包含 Doc Candidates 與 Sample Response ,因此該框架能涵蓋所有 Evaluable Outputs 和 Ground Truths 之間的配對,藉此達到系統地評估 RAG 系統。
它考慮 Target 、 Dataset 和 Metric 。 Target 模組決定評估方向, Dataset 模組便於比較不同的數據構建, Metric 模組則介紹與特定目標和數據集對應的評估指標。
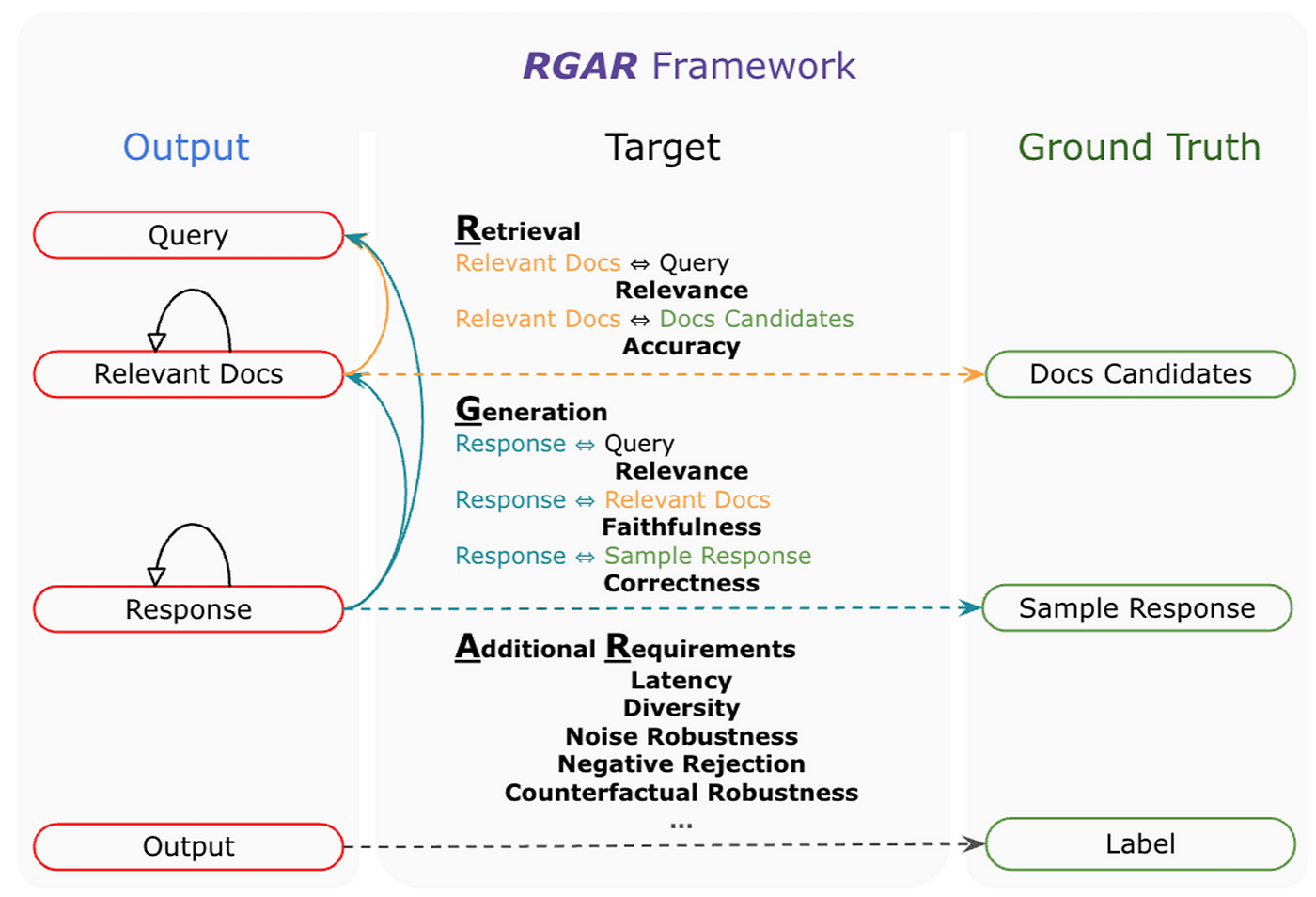
Yu et al. (2024) . Evaluation of Retrieval-Augmented Generation: A Survey.
簡單來說,RGAR 比 TruLens 多考慮了以下指標,我以上面 RAG Triad 為基準,重新繪製了一張幫助大家理解,為了統一表準, Ground Truth Context 代表 Doc Candidates ;而 Ground Truth Answer 則代表 Sample Response 。
- Context Accuracy : 評估
Context在Ground Truth Context中的準確性,衡量系統識別和評分相關文件的能力。 - Answer Correctness : 衡量
Response相對於Ground Truth Answer的準確性。評分範圍從 0 到 1,越高表示生對齊度越高,即更正確。 - 其他指標: Latency, Diversity, Noise Robustness 等
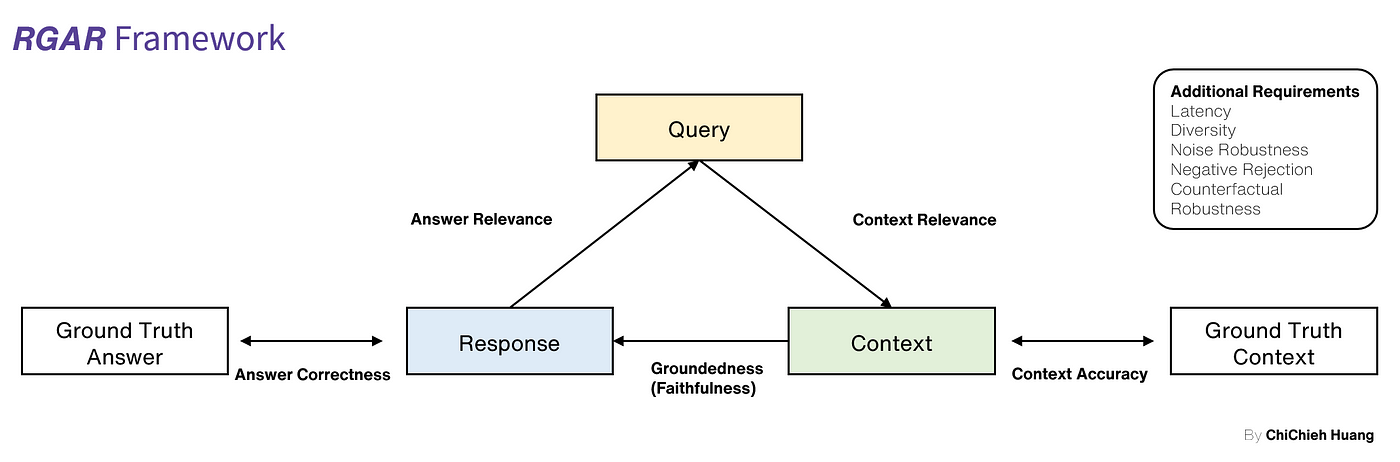
RGAR 的架構很好的將 Ground Truths 導入,並提出對應該評估的指標,同時針對整體 RAG 系統,也提出了很多應該納入的評估指標。
2. RAGAs
另外提一個非常熱門的工具框架,Shahul et al. 在 2023 提出的 RAGAs,這是一種用於自動評估 RAG 的方法,演變至今,是需多人在評估 RAG 時的首選之一。
與 RGAR 一樣,RAGAs 也考量到了 Ground Truths 的關係,但它只包含 Ground Truth Answer ,也就是 RGAR 的 Sample Response ,沒有涵蓋 Doc Candidates 的部分。不過單就 Ground Truth Answer ,RAGAs 就提出了 5 種不同的新評估指標:
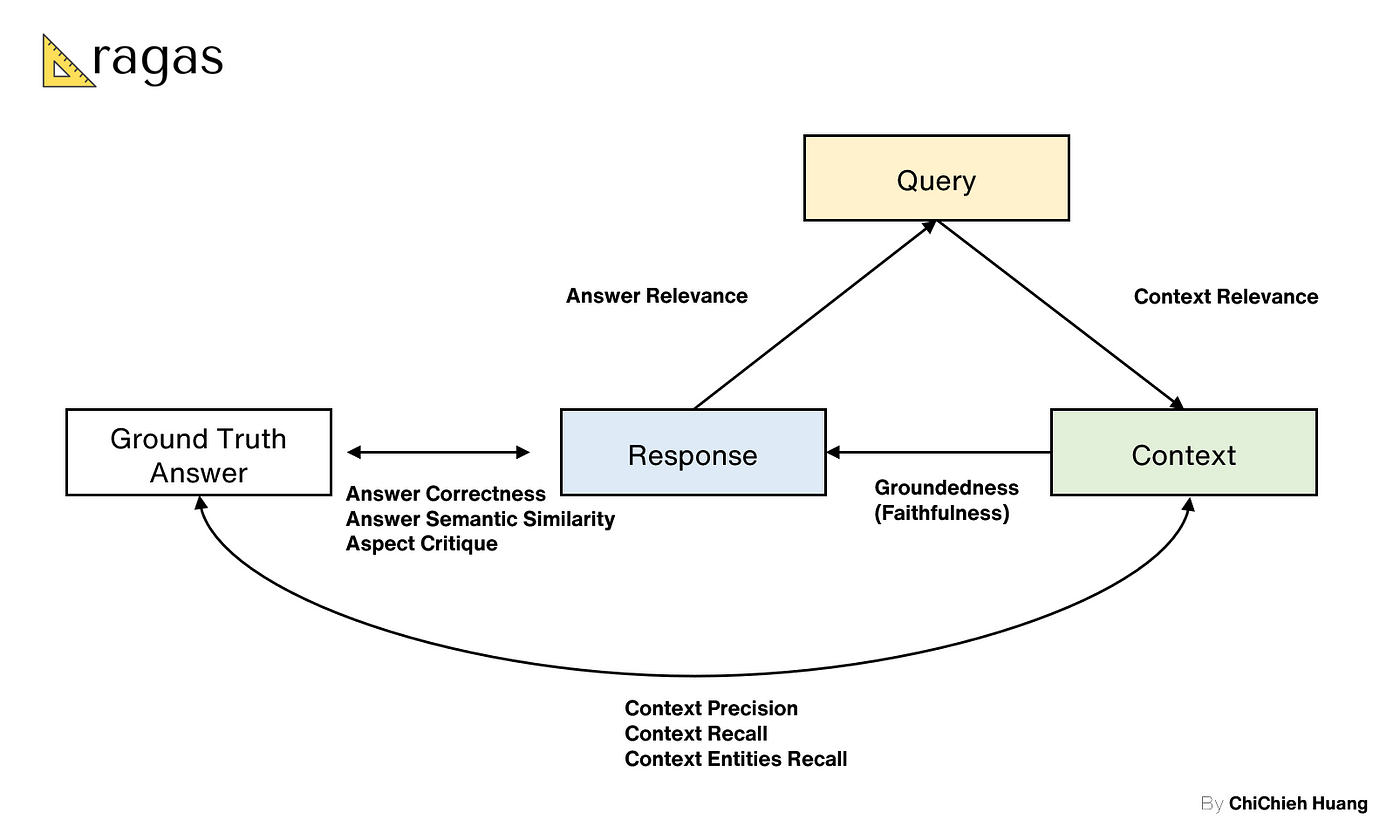
- Context Precision : 這個指標衡量在給定問題和背景下,所有與
Ground Truth Answer相關的項目是否都被排在了更高的位置。理想情況下,所有相關的資訊應該出現在最前面。該指標考慮了Query,Ground Truth Answer和Context,分數範圍是0到1,分數越高表示精確度越好。 - Context Recall : 用於衡量檢索到的
Context與Ground Truth Answer的對齊程度。具體來說,它分析每一句Ground Truth Answer的陳述是否能夠被歸因於檢索到的Context。完美情況下,Ground Truth Answer的每個句子都應該能對應到Context。分數同樣介於0到1之間,越高表示性能越好。 - Context Entities Recall : 該指標測量在檢索到的
Context中,有多少是與Ground Truth Answer共同出現的,相對於只在Ground Truth Answer中出現的數量。這是基於在兩個集合中出現的次數來計算的。這個指標特別適用於需要大量事實支撐的場景,如旅遊諮詢台或歷史問答等。分數計算方式是兩個集合中共同出現的數量除以Ground Truth Answer的總數 - Answer Correctness : RGAR 也有。
- Answer semantic similarity : 這個指標評估
Response與Ground Truth Answer之間的語義相似性。利用 cross-encoder model 來計算兩者之間的語義相似度分數,範圍從 0 到 1,越高表示一致性越好。這個指標可以幫助評估Response的質量,特別是在語義層面上的準確性。 - Aspect Critique : 這個指標是用來根據不同的面向如「無害性」和「正確性」等,來評估回答,除了預設的面向外,用戶也可以自定義特定的面向來評估。
3. 融合
如果我們將上述兩個框架的概念融合在一起,便可以全面地看在評估 RAGs 時,應該注意的指標有哪些。
五. 其他框架
以上介紹了許多評估 RAG 的工具框架,還有很多框架沒有納入這篇討論,如 RGB , CRUD-RAG 等,不過核心觀念不外乎,都是在引入 Ground Truths 後,所評估的新指標有所不同。
Yu et al. (2024) 在文章中有整理評估 RAG 的工具框架比較,在表中,有些框架所評估的指標沒有全部列出,但這個表讓你可以很方便比較框架間的差異性。
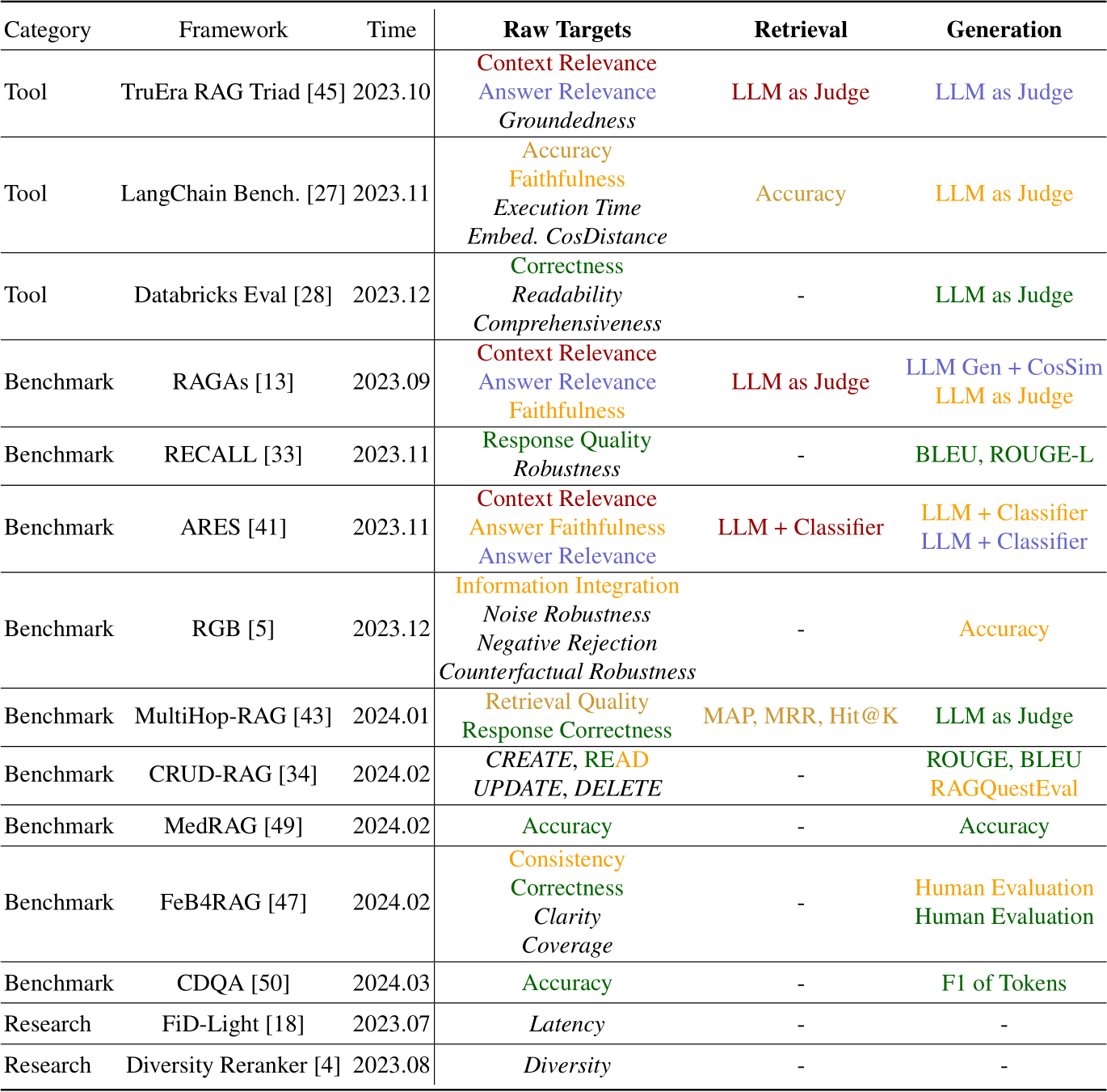
Yu et al. (2024) . Evaluation of Retrieval-Augmented Generation: A Survey.
另外 Leonie 在 2024/01/24 時製作了 RAG evaluation metrics and frameworks 的海報,一樣有些框架所評估的指標並沒有全部列出,但還是讓大家可以一目瞭然不同框架之間的差異。
https://x.com/helloiamleonie/status/1747252654047142351
六. RAG 評估未來展望
隨著 LLM 與 RAG 技術的持續發展,未來的評估框架也將變得更加複雜和多樣化。以下是幾個可能的發展方向:
1. 多模態評估: 目前大多數的 RAG 系統評估集中在文本檢索和生成上,但未來可能會擴展到多模態數據,包括圖像、音頻和視頻的檢索和生成。這將需要開發新的評估指標和方法,以應對不同類型數據的特定挑戰。例如,在處理圖像生成時,可能需要考慮圖像的清晰度、內容相關性和藝術風格的一致性。
2. 更強的上下文理解: 未來的 RAG 評估將更加注重系統對上下文的深度理解和解析能力。這包括對長篇文本的全局理解、對多段落信息的統合能力以及對複雜查詢的準確解釋。這種進步將使得 RAG 系統能夠在處理更具挑戰性的任務時表現出更高的精確度和可靠性。
3. 使用者體驗評估: 除了技術性能的評估,使用者體驗(UX)的評估也將成為未來 RAG 系統評估的重要一環。這將包括對系統易用性、回應速度和整體使用滿意度的測量。使用者反饋將成為改進系統設計和功能的重要依據,確保系統能夠滿足實際應用場景中的需求。
4. 強化安全與倫理考量: 隨著 RAG 系統應用範圍的擴大,其安全性和倫理問題也變得愈加重要。未來的評估框架將更加注重系統在處理敏感信息、隱私保護和防範有害內容生成方面的表現。這將包括開發專門的安全評估指標和工具,以確保系統能夠在各種情況下安全運行。
七. 結論
本文探討了 RAG 評估的重要性、挑戰以及現有的評估方法和指標。現有的評估框架如 TruLens 和 RGAR 等,提供了不同的指標和方法來評估 RAG 系統,然而,這些框架指標並不統一,且非常複雜,因此希望藉由這篇文章,能幫助到你了解 RAG 評估的基礎架構與概念。
參考文獻
Chen, J., Lin, H., Han, X., & Sun, L. (2023) . Benchmarking Large Language Models in Retrieval-Augmented Generation. AAAI Conference on Artificial Intelligence .
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., & Liu, T. (2023) . A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ArXiv, abs/2311.05232 .
Yu, H., Gan, A., Zhang, K., Tong, S., Liu, Q., & Liu, Z. (2024) . Evaluation of Retrieval-Augmented Generation: A Survey.
Salemi, A., & Zamani, H. (2024) . Evaluating Retrieval Quality in Retrieval-Augmented Generation.
Shahul, E., James, J., Anke, L.E., & Schockaert, S. (2023) . RAGAs: Automated Evaluation of Retrieval Augmented Generation. Conference of the European Chapter of the Association for Computational Linguistics .
Zhao, P., Zhang, H., Yu, Q., Wang, Z., Geng, Y., Fu, F., Yang, L., Zhang, W., & Cui, B. (2024) . Retrieval-Augmented Generation for AI-Generated Content: A Survey. ArXiv, abs/2402.19473 .
