RAG 優化技巧| 7 大挑戰與解決方式 | 增進你的 LLM
儘管 LLM + RAG 的能力已經令人驚嘆,但我們在使用 RAG 優化 LLM 的過程中,還是會遇到了許多挑戰與難題,包括但不限於檢索器返回不準確或不相關的資料,以及LLM基於錯誤或過時資訊生成答案的情況,因此本文旨在提出 RAG 常見的 7 大挑戰,與其各自的優化方案。
RAG 優化技巧| 7 大挑戰與解決方式 | 增進你的 LLM
在當今快速演進的人工智慧領域中,大型語言模型(LLM)已經成為無處不在的技術,它們不僅改變了我們與機器交流的方式,還在各行各業中發揮著革命性的影響。
然而,儘管 LLM + RAG 的能力已經令人驚嘆,但我們在使用 RAG 優化 LLM 的過程中,還是會遇到了許多挑戰與難題,包括但不限於檢索器返回不準確或不相關的資料,以及LLM基於錯誤或過時資訊生成答案的情況,因此本文旨在提出 RAG 常見的 7 大挑戰,與其各自的優化方案,期望能夠幫助到你改善 RAG。
下圖展示了 RAG 系統的兩個主要流程:檢索和查詢,紅色方框代表過程中會遇到的挑戰,主要有7點:
- Missing Content: 缺失內容
- Missed Top Ranked: 錯誤排序內容,導致正確答案沒有被成功 Retrieve
- Not in Context: 上限文限制,導致正確答案沒有被採用
- Wrong Format: 格式錯誤
- Incomplete: 回答不全面
- Not Extracted: 未能檢索資訊
- Incorrect Specificity: 不適合的詳細回答
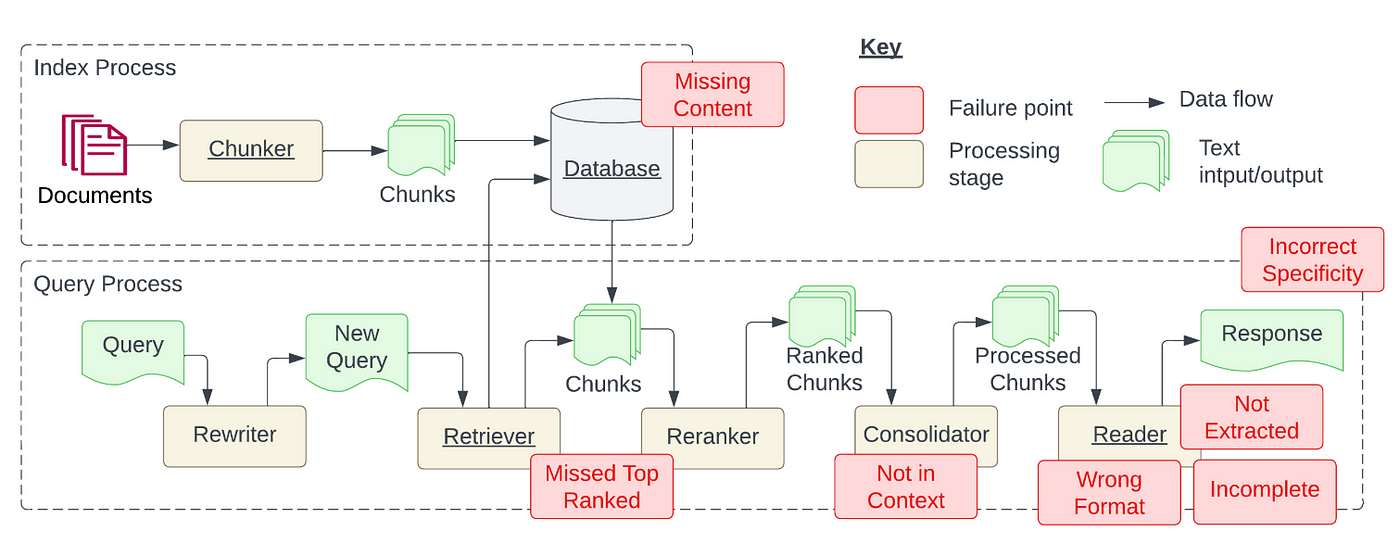
Barnett et al. (2024) Seven Failure Points When Engineering a Retrieval Augmented Generation System.
這些挑戰不僅關係到系統的可用性和準確性,還直接影響到用戶對技術的信任度。為了解決這些問題,以下是針對每個挑戰的優化方案:
1. Missing Content(缺失內容)
當 RAG 系統面對的問題無法從現有文件中得到答案時,就會出現這種情況。在最佳情況下,我們會希望 RAG 系統直接回答「我不知道」。然而,實務上RAG 系統常常會編造或錯誤回答問題。
針對這個問題,目前有兩大解決策略:
1. 資料清理
俗話說「garbage in garbage out」。原始資料品質對於資訊處理系統準確性的重要性,如果輸入資料錯誤或矛盾,或預處理步驟不當,那麼無論檢索增強生成(RAG)系統多麼先進,都無法從混亂資料中提取有價值的資訊。這意味著我們必須在資料來源選擇、資料清洗、預處理等環節投入資源和技術,以確保輸入資料盡可能的準確和一致。這個策略不僅適用於本文討論的問題,也適用於所有資料處理流程中,資料品質始終是關鍵。
2. Prompt Engineering
在知識庫缺乏相關訊息,導致系統可能給出看似合理但實際上錯誤的答案的情況下,使用 Prompt Engineering 是一個非常有幫助的解決方式。例如透過設定 Prompt:「如果你對答案不確定,就直接告訴我你不知道」,如此可以鼓勵模型採取更謹慎和誠實的回應態度,從而避免誤導用戶。雖然不能確保系統回答的絕對準確性,但透過這樣的 Prompt,確實能提高回答品質。
2. Missed Top Ranked(錯誤排序內容)
這個挑戰主要的問題在於「答案在文件中,但因為排名靠前,而未能提供給用戶」。理論上,所有文件在檢索系統中都會被賦予一個排名,而這個排名會決定其在後續處理中的使用程度。但在實際操作中,由於性能和資源的限制,通常只有排名最高的前 K 個文檔會被選中並展示給用戶,這裡的 K 是一個基於性能考慮的參數。
針對這個問題,有兩種解決方式:
1. 調整參數優化搜尋效果
這部分提出兩個面向調整增加 RAG 的效率和準確性: chunk_size 和 k
在 chunk_size 方面, 之前文章 中有介紹到,為了建立準確語意空間, chunk_size 非常重要,同時 Chunk optimization 也是 RAG 領域中很熱門的研究領域,常見的方法如 Sliding window technology, small2big 與 Abstract embedding 等。
如果想在 langchain 直接調整 chunk size,可以使用以下 code:
1
2
3
4
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100)
all_splits = text_splitter.split_documents(PDF_data)
k 則涉及檢索器應該回復多少答案,我們可以選擇更多的回覆答案,來確保正確答案不會沒有被送給 LLM:
1
2
3
4
5
6
7
8
retriever = vectordb.as_retriever(search_kwargs={"k": 8})
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
2. 優化檢索文件的排序
在把檢索到的文件送到 LLM 前,先對文件進行最佳化排序,能大幅提升 RAG 系統的效能,因為初始排序無法反映件與查詢的真實相關性。這系列的論文可以看 Liu et al. 2023 ,論文中指出, 將最相似的文檔放在開頭或結尾時,效能通常最高,因為模型容易迷失在中間 。
在 langchain 中,我們可以使用 langchain 原生的 Long-Context Reorder 或 Cohere Reranker 來實作,以下兩者都會示範:
2.1 Long-Context Reorder
可以參考 官方文件 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
retriever = vectordb.as_retriever(search_kwargs={"k": 8})
query = "What can you tell me about the Celtics?"
# Get relevant documents ordered by relevance score
docs = retriever.get_relevant_documents(query)
# Reorder the documents:
# Less relevant document will be at the middle of the list and more
# relevant elements at beginning / end.
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
# Confirm that the 4 relevant documents are at beginning and end.
reordered_docs
2.2 Cohere Reranker
可以參考 官方文件 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
from langchain_community.llms import Cohere
retriever = vectordb.as_retriever(search_kwargs={"k": 8})
query = "What can you tell me about the Celtics?"
# Get relevant documents ordered by relevance score
docs = retriever.get_relevant_documents(query)
# Uses the Cohere rerank endpoint to rerank the returned results
llm = Cohere(temperature=0)
compressor = CohereRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
3. Not in Context(上下文限制)
論文有提到:「答案所在的文檔雖從資料庫中檢索出來,但並未包含在生成答案的上下文中。」這種情況通常發生在返回的文檔太多,需透過一個整合過程來選取答案的情境。
為了解決這個問題,擴大上下文的處理範圍是一種方式,此外也建議可以嘗試以下方法:
1. 調整檢索策略
Langchain 中提供許多檢索的方法,確保我們在 RAG 中能拿到最符合問題的文件,詳細的列表可以 參考官網 ,其中包含:
- Vectorstore: 之前範例中提到的
- ParentDocument
- Multi Vector
- Self Query
- Contextual Compression
- Time-Weighted Vectorstore
- Multi-Query Retriever
- Ensemble
- Long-Context Reorder: 上一步驟有介紹
這些策略為我們提供了一種靈活多樣的方式,能夠根據不同的檢索需求和應用場景進行調整,以此提升檢索過程中的準確性和效率。
2. Finetune Embeddings
針對特定任務對 Embedding model 進行 Finetune,是提升檢索準確性的有效方法。如果你的 Embedding model 是開源的,那可以使用 LlamaIndex 的功能來實做,對比 Langchian,LlamaIndex 是針對檢索資料進行最佳化的套件,LlamaIndex 在這塊提供了詳細的教學,Langchian 則沒有對應的功能。
下面示範如何設定一個微調框架、執行微調操作,並取得經過微調的模型,也可以參考 官網文件 。
1
2
3
4
5
6
7
8
9
10
finetune_engine = SentenceTransformersFinetuneEngine(
train_dataset,
model_id="BAAI/bge-small-en",
model_output_path="test_model",
val_dataset=val_dataset,
)
finetune_engine.finetune()
embed_model = finetune_engine.get_finetuned_model()
4. Wrong Format (格式錯誤)
當你使用 prompt 要求 LLM 以特定格式(如表格或清單)提取資訊,但卻被而被 LLM 忽略時,可以嘗試以下 3 種解決策略:
1. 改進 prompt
你可以採用以下策略來改進你的 prompt,解決這個問題:
A. 明確說明指令
B. 簡化請求並使用關鍵字
C. 提供範例
D. 採用迭代提示,提出後續問題
2. Output Parsers
Output Parsers 負責取得 LLM 的輸出,並將其轉換為更合適的格式,因此當你想使用 LLM 產生任何形式的結構化資料時,這非常有用。他主要是在以下方面幫助確保獲得期望的輸出:
A. 為任何提示/查詢提供格式化指令
B. 對大語言模型的輸出進行「解析」。
Langchain 有提供許多不同類型 Output Parsers 的串流接口,以下是示範 code,細節可以看 官網文件 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import OpenAI
model = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.0)
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# And a query intended to prompt a language model to populate the data structure.
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": "Tell me a joke."})
parser.invoke(output)
3. Pydantic parser
Pydantic 是一個多功能框架,它能夠將輸入的文本字符串轉化為結構化的 Pydantic 物件。Langchain 有提供此功能,歸類在 Output Parsers 中,以下是示範 code,可以參考 官方文件 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
from typing import List
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
model = ChatOpenAI(temperature=0)
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
# And a query intented to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
chain.invoke({"query": joke_query})
5. Incomplete(回答不全面)
有時候 LLM 的回答並不完全錯誤,但會遺漏了一些細節。這些細節雖然在上下文中有所體現,但並未被充分呈現出來。例如,如果有人詢問「文檔A、B和C主要討論了哪些方面?」對於每個文檔分別提問可能會更加適合,這樣可以確保獲得更詳細的答案。
- Query Transformations
提高 RAG 系統效能的一個策略是添加一層查詢理解層,也就是在實際進行檢索前,先進行一系列的 Query Rewriting。具體而言,我們可以採用以下四種轉換方法:
1.1 Routing :在不改變原始查詢的基礎上,識別並導向相關的工具子集,並將這些工具確定為處理該查詢的首選。
1.2 Query Rewriting :在保留選定工具的同時,透過多種方式重構查詢語句,以便跨相同的工具集進行應用。
1.3 Sub-Questions :將原查詢拆解為若干個更小的問題,每個問題都針對特定的工具進行定向,這些工具是根據它們的元數據來選定的。
1.4 ReAct Agent Tool Picking :根據原始查詢判斷最適用的工具,並為在該工具上運行而特別構造的查詢。
Llamaindex 有針對這個問題有整理成一系列功能方便操作,細節看 官方文件 ;Langchain 則大部分功能散落在 Templates 裡面,如 HyDE 實作 與 paper內容實作等。以下示範使用 Langchain 進行 HyDE:
1
2
3
4
5
6
7
8
9
10
11
12
13
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import LLMChain, HypotheticalDocumentEmbedder
from langchain.prompts import PromptTemplate
base_embeddings = OpenAIEmbeddings()
llm = OpenAI()
# Load with `web_search` prompt
embeddings = HypotheticalDocumentEmbedder.from_llm(llm, base_embeddings, "web_search")
# Now we can use it as any embedding class!
result = embeddings.embed_query("Where is the Taj Mahal?")
6. Not Extracted (未能檢索資訊)
當 RAG 系統面對眾多資訊時,往往難以準確提取出所需的答案,關鍵資訊的遺漏降低了回答的品質。研究顯示,這種情況通常發生在上下文中存在過多干擾或矛盾資訊時。
以下是針對這一問題提出的三種解決策略:
1. 數據清洗
數據的品質直接影響到檢索的效果,這個痛點再次突顯了優質數據的重要性。在責備你的 RAG 系統之前,確保你已經投入足夠的精力去清洗數據。
2. 訊息壓縮
提示信息壓縮技術在長上下文場景下,首次由 LongLLMLingua 研究項目提出,並已在 LlamaIndex 中得到應用,相對 Langchain 的資源則較零散。現在,我們可以將 LongLLMLingua 作為節點後處理器來實施,這一步會在檢索後對上下文進行壓縮,然後再送入 LLM 處理。
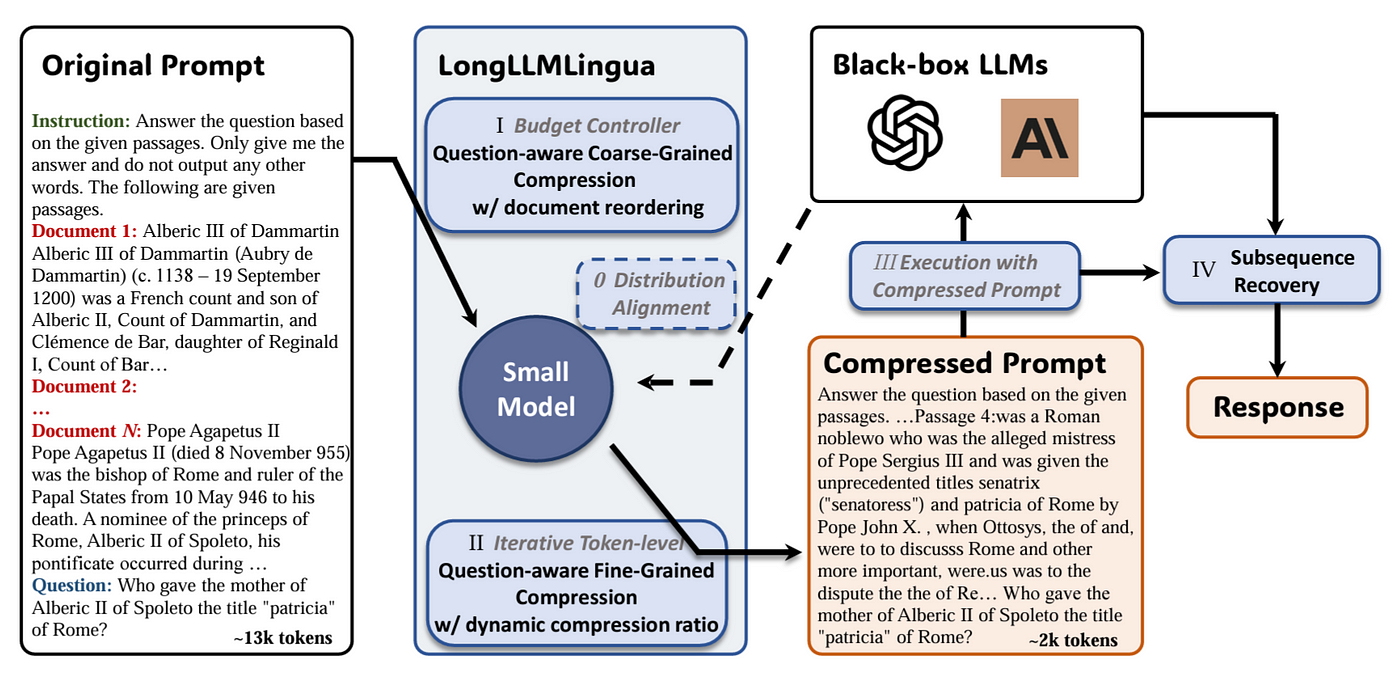
Jiang et al. (2023) LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression.
以下是在 LlamaIndex 中使用 LongLLMLingua 的示範,其他細節可以參考 官方文件 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.response_synthesizers import CompactAndRefine
from llama_index.postprocessor import LongLLMLinguaPostprocessor
from llama_index.schema import QueryBundle
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
},
)
retrieved_nodes = retriever.retrieve(query_str)
synthesizer = CompactAndRefine()
## outline steps in RetrieverQueryEngine for clarity:
## postprocess (compress), synthesize
new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=query_str)
)
print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))
response = synthesizer.synthesize(query_str, new_retrieved_nodes)
3. LongContextReorder
這在第二個挑戰,Missed Top Ranked 中有提到,為了解決 LLM 在文件中間會有「迷失」的問題,它通過重新排序檢索到的節點來優化處理,特別適用於需要處理大量頂級結果的情形。細節示範可以參考上面的內文。
7. Incorrect Specificity(不適合的詳細回答)
有時候,LLM 的回答會不夠詳細或具體,可能需要進行多次追問才能得到清楚的解答。這些答案或許過於籠統,無法有效滿足用戶的實際需求。
因此,我們需要採取更高級的檢索策略來尋找解決方案。
當你發現答案的詳細程度未達預期時,通過優化檢索策略,可以顯著提升資訊獲取的精確度。LlamaIndex 提供了許多高級檢索技巧,Langchain 在這方面的資源則較少,因此以下舉幾個 LlamaIndex 中,能夠有效緩解此類問題的高級檢索技巧:
結論
在本文中,我們探討了使用 RAG 技術會遇到的七大挑戰,而對於每個挑戰,我們提出了具體的優化方案,旨在提升系統的準確性和用戶體驗。
- Missing Content : 解決方案包括資料清理和 Prompt Engineering,確保輸入資料的品質和引導模型更加精確地回答問題。
- Missed Top Ranked: 可通過調整檢索參數和優化文件排序來解決,以確保最相關的資訊被呈現給用戶。
- Not in Context: 擴大處理範圍和調整檢索策略是關鍵,以包含更廣泛的相關信息。
- Wrong Format: 可以通過改進 prompt、使用 Output Parsers 和 Pydantic parser 來達成,這有助於以用戶期望的格式獲得信息。
- Incomplete: 可以通過 Query Transformations 來解決,確保對問題的全面理解和回答。
- Not Extracted: 數據清洗、訊息壓縮、和 LongContextReorder 是有效的解決策略。
- Incorrect Specificity: 可以通過更高級的檢索策略來解決,如 Auto Merging Retriever、Metadata Replacement 等技巧,進一步精細化信息檢索。
綜合以上,通過針對 RAG 系統的挑戰進行細致的分析和優化,我們不僅可以提升LLM的準確性和可靠性,還可以大大提高用戶對技術的信任度和滿意度。希望這篇能幫助到你改善你的 RAG 系統。
