語音大腦崛起:邁向讓機器聽懂你、用聲音回應你的時代
最近參加 Twinkle AI 舉辦的 Podcast,很有收穫就寫了下心得分享給沒聽到的大家,以下文章也同步發布在 AILogora,有興趣可以去那邊討論。
語音大腦崛起:邁向讓機器聽懂你、用聲音回應你的時代
最近參加 Twinkle AI 舉辦的 Podcast,很有收穫就寫了下心得分享給沒聽到的大家,以下文章也同步發布在 AILogora ,有興趣可以去那邊討論。

內容心得
本次訪談由主持人 黃亮勳 邀請 Ethan,深入探討語音模態的世界,特別是在 Vibe Voice 等模仿聲音的技術興起之後,機器如何真正實現「聽懂」並「回應」人類的聲音。Ethan講師擁有數學和統計學背景,曾擔任 9 年高中數學老師,並於 2023 年轉職成為 AI 工程師,現專注於 LLM 的相關應用。
I. 傳統語音流程的限制與 STS 模型的崛起
當我們聊到AI 語音對話的時候,很多人腦中浮現的畫面,可能是 Siri、Google 助理、或 ChatGPT 開口說話的樣子,但其實這些「會講話的 AI」其實大多都不是「端到端」的語音模型。
傳統的 AI 語音系統流程通常包含三個主要階段:
- ASR (Automatic Speech Recognition,語音辨識): 將語音轉換成文字。
- LLM (大型語言模型): 理解文字語意並生成文字回應。
- TTS (Text-to-Speech,語音合成): 將文字轉換成合成語音輸出。
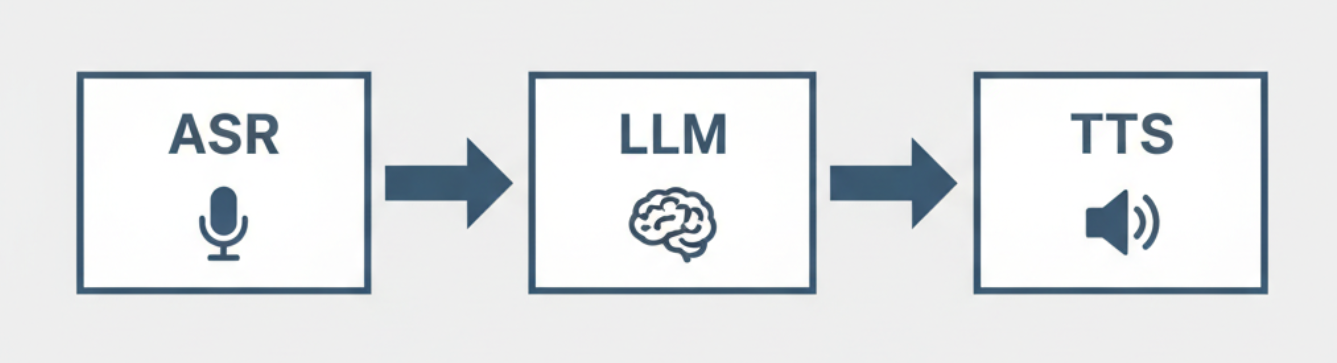
然而,這種轉換流程會 忽略掉聲音中帶有的情緒、音色、節奏和語氣等重要資訊 。
想像你說一句:「你現在是認真的嗎?」這句的語氣可能是驚訝、懷疑、或生氣,這些細節都藏在聲音裡,傳統的語音系統只看到「你現在是認真的嗎」這幾個字,完全聽不出你可能其實是在翻白眼XD
為了解決這個問題,一種新型態的語音模型在去年開始興起,即 Speech-to-Speech (STS) Model 。
它的思維很簡單,就是 不要再經過文字這一關,語音直接對到語音。
這代表 STS 模型會有幾個的關鍵特徵 :
- 模型能直接理解聲音的內容與情緒。
- 回覆也能帶著自然的語氣與節奏。
- 對話可以被打斷,就像真實聊天一樣自然。
在這個模式下,AI 不只是聽懂你說什麼,更能聽出你怎麼說的。
II. 核心技術:Token Base 的概念與優勢
問題是在以往聲音是連續的波形訊號,資料量大得可怕,以常見的 24kHz 為例,意思是電腦每秒鐘會量 24,000 次這條聲音波形的高度,也就是「取樣率」是每秒 24,000 筆資料,所以如果這段錄音有 10 秒,那就會有 24,000 × 10 = 240,000 筆資料 。
這麼龐大的資料如果直接丟進 Transformer 模型,計算量會像滾雪球一樣爆炸成平方級成長,近期研究者想到的妙招是,把連續的聲音 轉換成離散的符號,也就是 Speech Tokens ,這些 token 保留了音色、語氣等特徵,使模型能以 Transformer 架構進行訓練。
這個過程大致分為三個步驟:
- 語音編碼 (Speech Encoding):
- 使用特製的編碼器 (如 SoundStream、EnCodec 等) 將連續音訊壓縮成一組固定長度的向量。這些向量會保留音色、節奏等關鍵訊息,但資料量大幅縮小。
- 特徵蒸餾 (Feature Distillation):
- 編碼器通常透過從大型聲音模型 (如 WavLM、HuBERT) 中「蒸餾」學習,讓模型在壓縮訊號的同時仍能保留語音的語意與情感特徵。
- Token 化 (Discretization):
- 壓縮後的聲音片段被映射成一組離散 tokens,每個 token 代表一段特定的語音特徵,這使得語音資料可以被視為「聲音的語言」,從而能以類似文字 LLM 的方式進行訓練與生成。
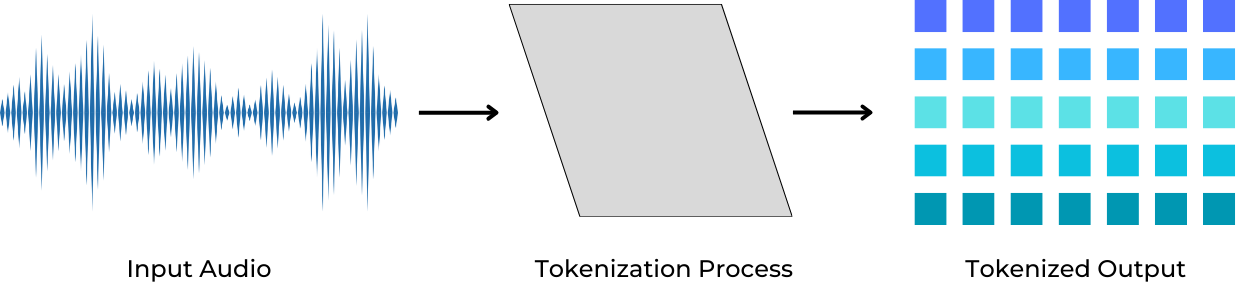
如此一來就能將原本每秒 24,000 筆的訊號,壓縮成大約每秒 12.5 個 Token,這讓 STS 模型不只更輕量,也能以「文字模型的思維」學習聲音。
這種聲音 Token 化的方式帶來多項明顯優勢:
- 計算效率更高: 以 Moshi 模型為例,原本每秒 24,000 筆的語音訊號可以壓縮到每秒 12.5 筆,大幅降低了推理成本。
- 可被 Transformer 理解: 聲音被 Token 化後,可以被 Transformer 結構 (類似於訓練文字 LLM 的方式) 去理解和學習。
- 保留原始特徵: 能夠擷取並保留原本的音色、情緒和節奏。
- 低延遲 (Low Latency): 延遲可低至 200 毫秒以下,使得使用者在體感上幾乎感受不到機器的思考停頓,實現自然的互動。
III. 代表性模型與架構
STS 模型雖然概念明確,但在實作上仍屬前沿研究,近兩年,數個關鍵模型逐漸奠定了這一領域的技術格局,不過現在商用 LLM 來說,還沒有原生的 STS 模型,Ethan 提到幾個著名的 STS 模型:
而在 STS 模型中,編碼器被視為整個模型的耳朵跟嘴巴,Ethan 也介紹了幾個 代表性編碼器:
- MIMI : 由法國 kyutai labs 在 2024 年開發,專門針對即時語音互動設計,許多最新的 STS 模型仍沿用此編碼器。
- SoundStream (Google, 2021): 利用殘差向量量化方式壓縮聲音。
- Encodec (Meta, 2022): 在音樂生成方面具有優勢。
詳細 STS 模型與 編碼器 可以參考下面的觀點卡:
VI. STS 模型的推論過程
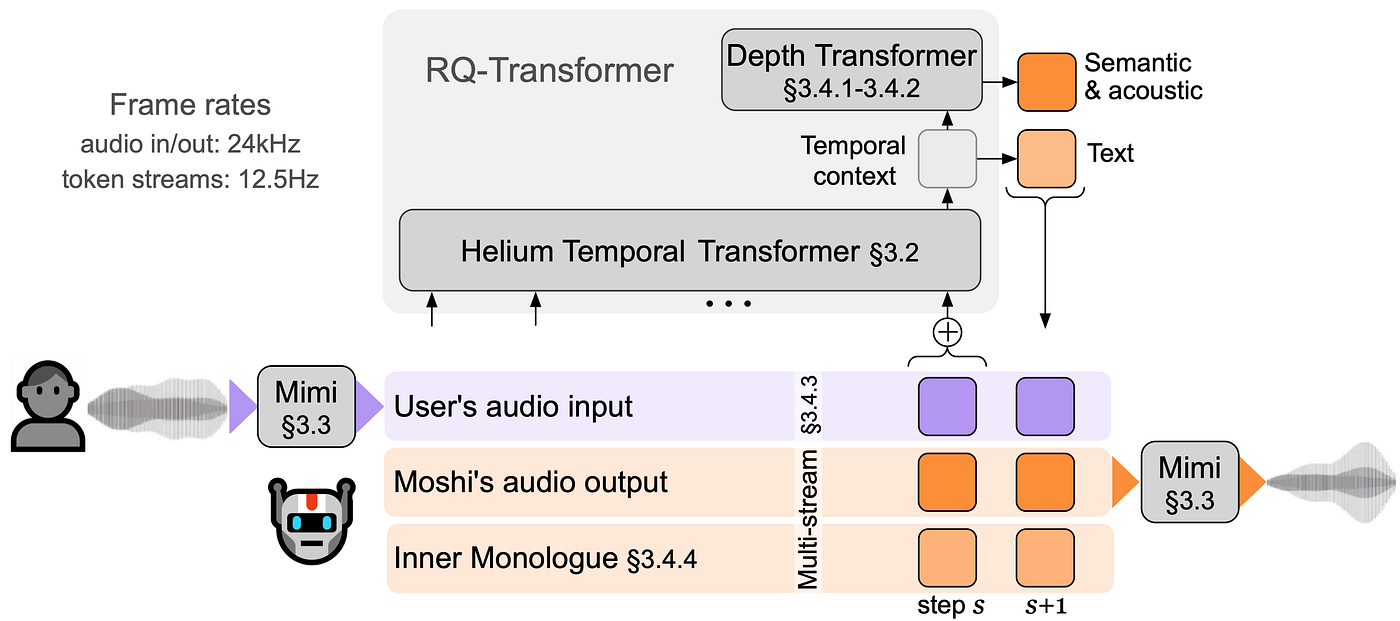
滿多人好奇 STS 模型的推論過程是怎樣,主持人也很貼心幫我們問到,Ethan 以 Moshi 例子來說明,主要會分成 4 個步驟:
- 語音輸入: 使用者的語音經由 MIMI 編碼器 編碼,產生 Speech Token 。
- LLM 處理: Speech Token 被送入一個客製化的 LLM ( 例如 Moshi 使用的 Helium 模型)。這個 LLM 與一般 LLM 的不同之處在於它能接收和吐出 Speech Token。
- 生成輸出: LLM 理解語意和上下文後,會生成兩種 Token, 語意 Token 和 聲學 Token 。
- 語音輸出: 聲學 Token 再送到 MIMI 解碼器 ,轉換成真實的語音波形。
V. STS 模型的訓練過程
STS 模型的訓練與文字模態類似,也經過 Pre-training 和 Supervised Fine-Tuning (SFT) 兩階段,並在結構上採用「聲學 Token 與語意 Token 結合」的多模態設計。
1. Pre-training:語音理解與模態對齊
在預訓練階段,模型需要學會「理解聲音」並建立與文字的對應關係,這通常包含兩部分:
- 語音自監督學習 (Speech Encoder): 使用大量未標記的語音資料,讓模型學習聲音中的語音內容、節奏、音色與語調等特徵。
- 語音與文字對齊(Speech-Text Alignment): 利用語音與文字配對資料,將語音表示投影到與語言模型相容的語義空間,透過對比損失或跨模態匹配訓練,使語音特徵與文字 embedding 能互相對應。
這個階段的目的是讓模型能「聽懂語音」並與語言模態建立共享語義基礎。
2. SFT (Supervised Fine-Tuning):對話與情境適應
在微調階段,模型會以 雙人或多人的語音對話資料 進行監督訓練,使其學習更自然的互動與語音行為:
- 對話能力訓練: 學習語音輪替、回應策略、上下文理解。
- 打斷學習: 資料中包含插話或打斷標記,讓模型學會在語音被中斷時停止生成、切換話題或快速回應。
- 音色與情緒表達: 若資料中帶有情緒或音色標記,模型可學習在生成階段控制語氣與聲調,使對話更具表現力。
這一階段主要讓模型從「能理解語音」進一步進化為「能對話與互動」。
3. Token 對齊與融合機制
在模型結構中,STS 通常採用與 VLM (Vision-Language Model) 類似的多模態融合策略:
- 聲學 Token (Acoustic Tokens) 由語音編碼器產生,承載聲音的節奏、音色與語氣資訊。
- 語意 Token (Semantic Tokens) 由語言模型產生,負責理解與生成語義內容。
- 融合方式: 聲學 Token 通常作為前綴 (prefix) 輸入,並透過 cross-attention 或 adapter 層與語言 token 互動,而非單純拼接,如此能平衡不同模態間的資訊權重,降低長序列造成的干擾。
這樣的設計使模型能同時保留語音中的情感表現,又能維持語言層級的邏輯與語意連貫性。
VI. 打斷機制
大家都滿好奇打斷功能是如何實現了,主持人一樣很貼心幫我們問到。打斷功能是在 SFT 雙人對話訓練 中實現的,當對話中的 B 方說話時,新的聲學 Token 會不斷輸入。在 Transformer 中,基於長度限制, 新的 Token 會把舊的 Token 排擠掉 ,迫使模型去理解 B 方新說的內容,並準備回覆,這種機制有人也稱為 inner monologue 。
VII. 資料集收集的優勢
相較於收集文字或圖片描述的資料集,STS 模型的 SFT 資料集收集相對容易。只需要錄製對話的語音檔案,再進行整理即可。這不僅能保留對話的知識內容,還能將說話者的 音色 訓練進去。然而,訓練時對語音資料的品質有要求,需要考慮 清晰度 以及 發音咬字的標準程度 。
VIII. 繁體中文的技術挑戰
目前主流的 STS 模型 (如前述的 Moshi, LFM2audio) 多由外國實驗室開發,僅支援英文和法文,並沒有原生支援中文,因此若要應用在繁體中文,Ethan 提出兩個方法:
- 方法一 (高成本): 為中文量身打造新的 Speech Encoder,重新定義中文語音的離散 Token,優點是效果最佳、語音保真度高;缺點是成本極高,需要龐大的中文語音語料與算力資源。
- 方法二(較經濟): 使用原有的編碼器擷取聲音的聲學特徵 (音色、語調、速度),再與對中文有一定掌握能力的 LLM (如 Gemini) 整合,相當於為中文 LLM 「加裝耳朵與嘴巴」, 在成本與可行性之間取得折衷
IX. 挑戰、應用與倫理議題
1. 幻覺問題
STS 模型的幻覺問題主要源自於 模型 Size 的限制 。為了達到低延遲的要求,STS 模型使用的 LLM 尺寸通常較小 (如 1.X B 或 3B,7B 就算大),這限制了模型本身的能力,例如在進行數學運算時可能會算錯。如果 SFT 訓練過於集中,也可能出現 overfit 情況,導致模型在特定情境下一字不漏地重複訓練過的語句。
2. 情緒辨識
同一句話若使用不同情緒去問,會產生不同的聲學 Token ,而語意 Token 則相似。這證實了模型是利用離散 Token 來辨識情緒感受的。不過,對於複雜的語氣如 反諷或挖苦 ,僅靠聲音較難完全抓取,通常需要搭配語意一起理解。
- 特定族群服務: Moshi 實際應用於為 視障者 提供全語音操作服務。
- 情緒辨識應用: 由於能辨識語氣,未來可能應用在長照或醫療領域,偵測使用者的焦慮、悲傷等感受。
- 多模態發展: 在 Token 的世界中,語音技術可以融合視覺模態。例如,將影像也轉換成 Token,讓 Transformer 同時學習語音和影像,雖然實際效果和應用場景仍在發展中。
3. 倫理與資安挑戰
最後有觀眾問到資安方面的議題,Ethan 也分享幾個方向要注意:
- 聲音複製與濫用: 複製音色變得非常容易,模型可以直接模仿說話者的聲音與不同人對話,未來詐騙防治會是一大問題。
- 版權與隱私: 像文字和影像一樣,使用真人聲音進行模型訓練,會存在數據未經同意被使用的問題。
聽完這場分享,能感受到 STS 技術帶來的 AI 的新紀元,雖然在中文支援、複雜情感理解和倫理規範方面仍有待發展,但其應用潛力,特別是在提升人機互動自然度及服務特定族群方面,非常令人期待!
