記憶體不夠? 來看 LLM 的壓縮技術
本篇探討 LLM 的 4 種類型的壓縮技術:剪枝(Pruning)、知識蒸餾(Knowledge Distillation)、量化(Quantization)、低秩因子分解(Low-Rank Factorization)
記憶體不夠? 來看 LLM 的壓縮技術

大型語言模型(LLMs)所佔的記憶體非常大:
- GPT-175B 用半精度 FP16(2 bytes) 儲存,需要 175*2 ~ 320 GB
- LLaMA2–65B 用全精度 FP32(4 bytes) 儲存,需要 65*4 ~ 260 GB
對比一張 A100 只有 80G,因此想在常見硬體設備上進行 fine tuning 或預測,是一個極大的挑戰。因此當前 LLMs 的在壓縮技術領域中,有豐富多樣的研究,針對不同的挑戰和應用提出解決方案,目前主要的研究領域有 4 大塊,如下圖可以看到不同領域的模型壓縮技術。
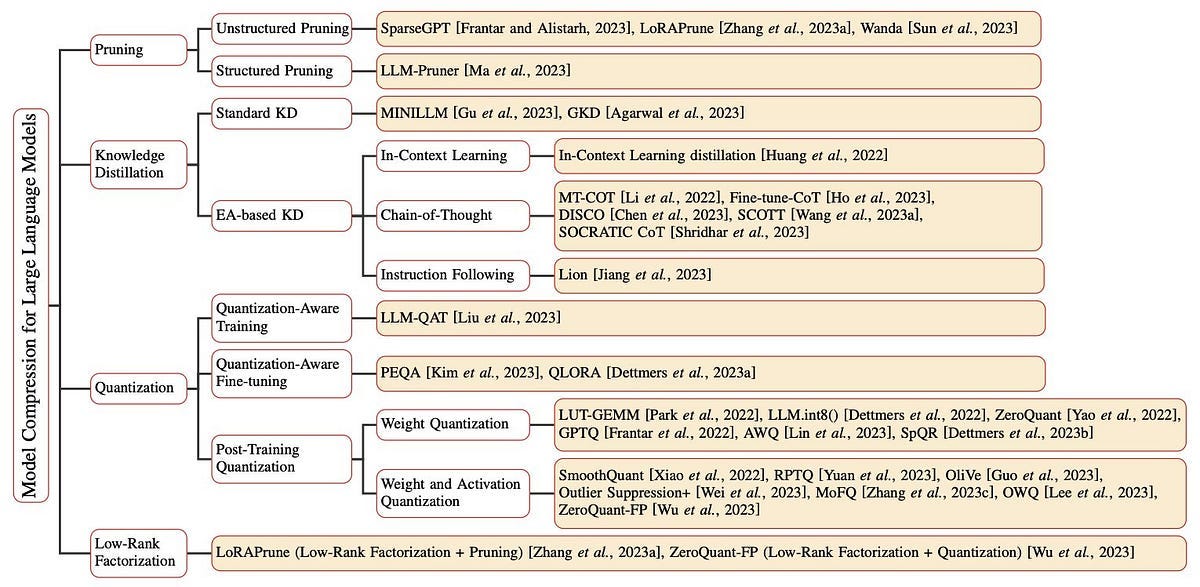
Canwen and Julian (2022) . A Survey on Model Compression for Large Language Models.
1. 剪枝 (Pruning)
剪枝透過移除語言模型中的非關鍵或多餘組件(例如權重參數)來提升模型效率,這是一種最佳化的方法。此方法透過裁剪對模型效能貢獻較小的參數,減少了儲存需求,又優化了記憶體和運算效率,同時盡量保持模型效能的穩定性。剪枝主要分為兩大類:非結構化剪枝和結構化剪枝。
1-a. ) 非結構化剪枝 ( Unstructured Pruning )
主要指隨機移除單一參數,不考慮模型的整體架構。
此方法透過將那些低於特定閾值的參數設為零來實現對個別權重或神經元的處理,因此容易使模型產生一種不規則的稀疏結構,而這種不規則性則需要特別的壓縮技術來有效儲存和計算。
非結構化剪枝通常要求對大型語言模型進行廣泛的再訓練以恢復效能,這對於LLM來說成本極高,因此有些研究在探討這個領域,以下提出 3 種不同的方法。
- SparseGPT (Frantar and Alistarh, 2023) 提出了一種無需重新訓練的一次性剪枝方法。此方法將剪枝問題轉化為廣義的稀疏迴歸問題,並採用近似稀疏迴歸求解器來實現顯著的非結構化稀疏性。
- LoRAPrune (Zhang et al. , 2023) 結合了參數高效調整 (PEFT) 策略和剪枝技術,旨在提升特定下游任務的性能。 此方法採用了獨特的參數重要性評估標準,此標準基於Low-Rank Adaption(LoRA)的值和梯度資訊。
- Wanda (Sun et al. , 2023) 則提出了一個新型的剪枝度量方法。此方法透過計算每個權重的大小與對應輸入活化範數的乘積來進行評估,此計算透過使用小型校準資料集來近似實現。 這種度量方式用於模型的線性層輸出中的局部比較,幫助從LLM中剔除相對較不重要的權重。
1-b. ) 結構化剪枝 (Structured Pruning)
結構化剪枝著重於依照預設規則批量移除連接或層次結構,保持模型的整體架構不變。這種方法的優點在於,它透過一次性處理整組權重,降低了模型的複雜度和記憶體佔用,同時保持LLM的整體結構完整。
- LLM-Pruner (Ma et al. , 2023) 提出了一種多元化方法來壓縮大型語言模型,並保留其多任務處理和語言生成的能力。它採用了依賴檢測演算法來識別模型內部的依賴結構,並實現了一種高效的重要性評估方法,該方法考慮了一階資訊和近似 Hessian 資訊。
2. 知識蒸餾 ( Knowledge Distillation )
核心思想為 “教師-學生網路”。目的在於將一個大型複雜模型 (教師模型) 的知識,傳遞給一個更小、更簡單的模型 (學生模型)。透過這種方式,學生模型能夠學習並模仿教師模型的行為,從而在保持較高性能的同時減少計算資源的需求。這些方法分為兩大類: Black-boxKD ,其中僅可訪問教師的預測;和 White-boxKD ,可以利用教師的參數。
2-a. ) White-box KD
White-box KD 中,不僅可以訪問教師 LLM 的預測,還允許訪問和利用教師LLM的參數。這種方法使學生LM能夠更深入地了解教師LLM的內部結構和知識表達,通常能帶來更高層次的性能改進。White-box KD 通常用於幫助較小的學生 LM 學習和複製更大、更強大的教師 LLM 的知識和能力。
- 一個典型的例子是 MINILLM ( Gu et al. , 2023),它探討了來自 White-box生成 LLM 的蒸餾。它發現了一個挑戰,即最小化前向Kullback-Leibler 散度 (KLD) 可能導致教師分布不太可能的區域出現過高的概率,從而在自由生成過程中產生不可能的樣本。為了解決這個問題,MINILLM 選擇最小化反向 KLD。這種方法防止學生模型在教師分布中低概率區域的估計過高,從而改善生成樣本的質量。
- GKD (Agarwal et al. , 2023) 則探索了來自自回歸模型的蒸餾,其中 White-box 生成 LLM 是一個子集。該方法確定了兩個關鍵問題:訓練期間輸出序列與學生部署期間生成的序列之間的分布不匹配,以及模型規格不足,其中學生模型可能缺乏與教師分布匹配的表達能力。GKD 通過在訓練期間從學生模型抽樣輸出序列來處理分布不匹配。它還通過優化像反向 KL這樣的替代散度來解決模型規格不足問題。
2-b. ) Black-box KD
Black-box KD 僅可訪問教師 LLM 的預測結果。近期的研究強調,像 GPT-3 (175B) 和PaLM (540B參數) 等較大型的 LLM,與較小的模型如BERT (330M) 和 GPT-2(1.5B) 相比,會展現出獨特的行為。這些能力被稱為新興能力,主要有三種:
- 上下文學習 (In-Context Learning, ICL)
ICL 運用結構化自然語言提示,其中包含任務描述和可能的幾個任務示例作為演示。通過這些任務示例,LLMs可以把握並執行新任務,而無需明確的梯度更新。
2. 思緒鏈 (Chain of Thought, CoT)
與 ICL 不同,CoT 採用了不同的方法,將中間推理步驟 (可以導致最終輸出)納入提示中,而不是僅使用簡單的輸入輸出對。 MT-COT (Li et al. , 2022) 旨在利用LLMs產生的解釋來增強小型推理器的訓練。它利用多任務學習框架來賦予較小模型強大的推理能力以及產生解釋的能力。
3. 指令遵循 (Instruction Following, IF)
IF 旨在提升語言模型僅憑閱讀任務描述就能執行新任務的能力,而無需依賴少樣本示例。通過使用一系列以指令形式表達的任務進行微調,語言模型展示了準確執行以前未見指令描述中的任務的能力。例如,Lion (Jiang et al. , 2023) 利用LLMs的適應性來提升學生模型的性能。它促使 LLM 識別並生成 “難” 指令,然後利用這些指令來增強學生模型的能力。這種方法利用了LLM的多功能性,指導學生模型在處理複雜的指令和任務時進行學習。
3. 量化 (Quantization)
核心在於將 Float 轉換為整數或其他離散形式,減輕儲存與計算負擔。根據應用量化壓縮模型的階段,量化方法可分為以下三種:
3-a. ) 量化感知訓練 (Quantization-Aware Training, QAT)
量化感知訓練是在訓練過程中直接將量化的影響納入考慮的方法。通過模擬訓練過程中的量化效果,QAT 能夠使模型對量化產生的誤差更具韌性。這樣,模型在量化後的性能下降會較小,甚至在某些情況下可以達到與未量化模型相近的性能。
LLM-QAT (Liu et al. , 2023) 利用預訓練模型產生的結果來實現無數據蒸餾,並量化權重、activation value 以及 KV Cache,提升吞吐量並支持更長的序列依賴,能夠將帶有量化權重和 KV Cache 的大型LLaMA模型蒸餾為僅有4bits 的模型,證明了製造精準的4 bits 量化 LLM 的可行性。
3-b. ) 量化感知微調 (Quantization-aware Fine-tuning, QAF)
QAF 是指在量化過程後對模型進行微調,以恢復因量化導致的性能損失。QAF 通常在 PTQ 之後執行,通過微調量化模型的參數,進一步優化模型的表現。
相關的技術如 PEQA (Kim et al., 2023) 和 QLORA (Dettmers et al., 2023) ,它們都專注於促進模型壓縮和加速推理。PEQA 通過雙階段過程,先將全連接層參數矩陣量化為低位整數矩陣和標量向量,再對每個特定下游任務的標量向量進行微調。QLORA 則引入新的數據類型、雙重量化和分頁優化器等創新概念,旨在節省內存並保持性能,使大型模型可在單GPU上微調,在Vicuna基準測試上達到先進水平。值得注意的是這些方法都是屬於量化感知參數高效微調(Parameter-Efficient Fine-Tuning, PEFT) 的技術範疇。
3-c. ) 後訓練量化 (Post-Training Quantization, PTQ)
PTQ 是在模型訓練完成後進行的量化過程。這種方法不需要重新訓練模型,可以直接在訓練好的模型上進行。PTQ 的優勢在於操作簡單、快速,但缺點是可能會因為無法根據量化後的表現進行優化,而導致模型精度有所下降,這部分方法盛行,以下列舉一些近期發表的方法。
- LUT-GEMM (Park et al., 2022) 通過對權重進行量化和使用BCQ格式來優化LLM中的矩陣乘法,提升計算效率,降低延遲,同時維持良好性能。
- LLM.int8( ) (Dettmers et al., 2022) 採用 8-bit 量化方法,有效減少GPU內存使用,同時保持模型性能,其可以在具有多達 1750B 個參數的模型中進行推理,而不會影響效能
- ZeroQuant (Yao et al., 2022) 結合硬件友好的量化方案、逐層知識蒸餾和優化技術,將基於 Transformer 的模型權重和激活精度減至 INT8,對精度影響極小。
- GPTQ ( Frantar et al., 2022) 則提出一種基於近似二階信息的創新層級量化技術,將權重位寬減至3或4 bits,而幾乎不損失精度。
- AWQ ( Lin et al., 2023) 發現權重對於 LLM 的影響不一致,因此通過僅保護1%的關鍵權重,可以顯著減少量化誤差。
- OWQ ( Lee et al., 2023) 分析了激活異常如何放大權重量化的誤差,並引入混合精度量化策略。
- SpQR ( Dettmers et al., 2023) 則專注於識別和隔離異常權重,並將其以較高精度存儲,同時將其他權重壓縮至3–4bits。
- SmoothQuant ( Xiao et al., 2022) 針對量化激活過程中的挑戰,引入逐通道縮放轉換,有效地平滑幅度,便於量化,實現高達 3bits 超低精度的無損壓縮。
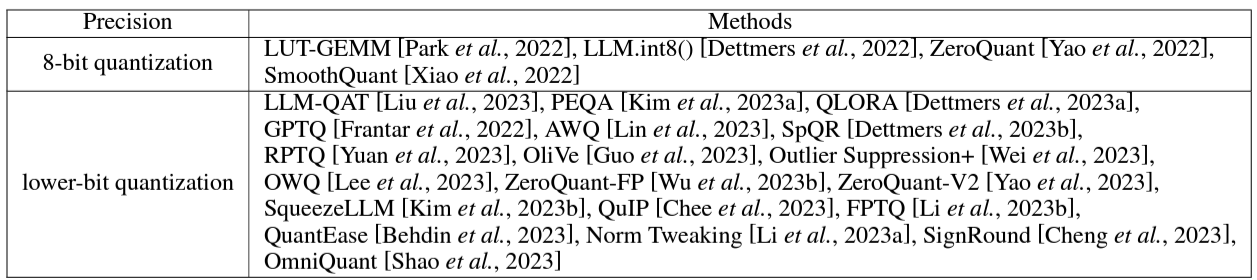
LLM 量化方法 Canwen and Julian (2022) . A Survey on Model Compression for Large Language Models.
4. 低秩因子分解 (Low-Rank Factorization)
核心思想是將一個大的矩陣分解為兩個或多個較小、低秩的矩陣的乘積,從而達到數據壓縮和特徵提取的目的。這種方法在降維、噪聲過濾、數據壓縮以及模型參數壓縮等領域有廣泛應用。
簡單來說,這個方法將大矩陣 W 分解為兩個矩陣 U 和 V,使得 W ≈ UV,其中 U 是 m×k 矩陣,V 是 k×n 矩陣,k 比 m 和 n 小很多。低秩因子分解在數學上應用很久,大家也常使用如奇異值分解 (Singular Value Decomposition, SVD)、主成分分析 (Principal Component Analysis, PCA) 或非負矩陣分解 (Non-negative Matrix Factorization, NMF) 等。
在 LLM 中,低秩因子分解已被廣泛應用於有效地 fine tuning LLM,例如著名的如 LORA (Hu et al., 2022) 及其許許多多的變體。而將這個方法應用在模型壓縮上,近期的研究有以下:
- TensorGPT (Xu et al., 2023) 以低秩張量格式存儲大型嵌入(embeddings),減少了LLMs的空間複雜性,使其能夠在邊緣設備上運行。具體來說,TensorGPT利用張量列車分解 (Tensor-Train Decomposition, TTD) 有效壓縮LLMs中的嵌入層。通過將每個 token 嵌入視為一個矩陣積態 (Matrix Product State, MPS),嵌入層的壓縮比可達到高達38.40倍,同時仍然維持或甚至提升模型相比原始LLM的性能。
總結
總結來說,LLM 的壓縮技術正迅速進步,重點在於在保持準確性和效率的同時,解決多任務處理、語言多樣性和魯棒性等挑戰,希望這篇文章能幫助到你了解 LLM 的相關壓縮技術。
參考資料
Canwen and Julian (2022) . A Survey on Model Compression for Large Language Models.
