RAG實作教學,LangChain + Llama2 |創造你的個人LLM
在這篇文章中,我們將帶你使用 LangChain + Llama2,一步一步架設自己的 RAG(Retrieval-Augmented Generation)的系統,讓你可以上傳自己的 PDF,並且詢問 LLM 關於 PDF 的訊息。
RAG實作教學,LangChain + Llama2 |創造你的個人LLM
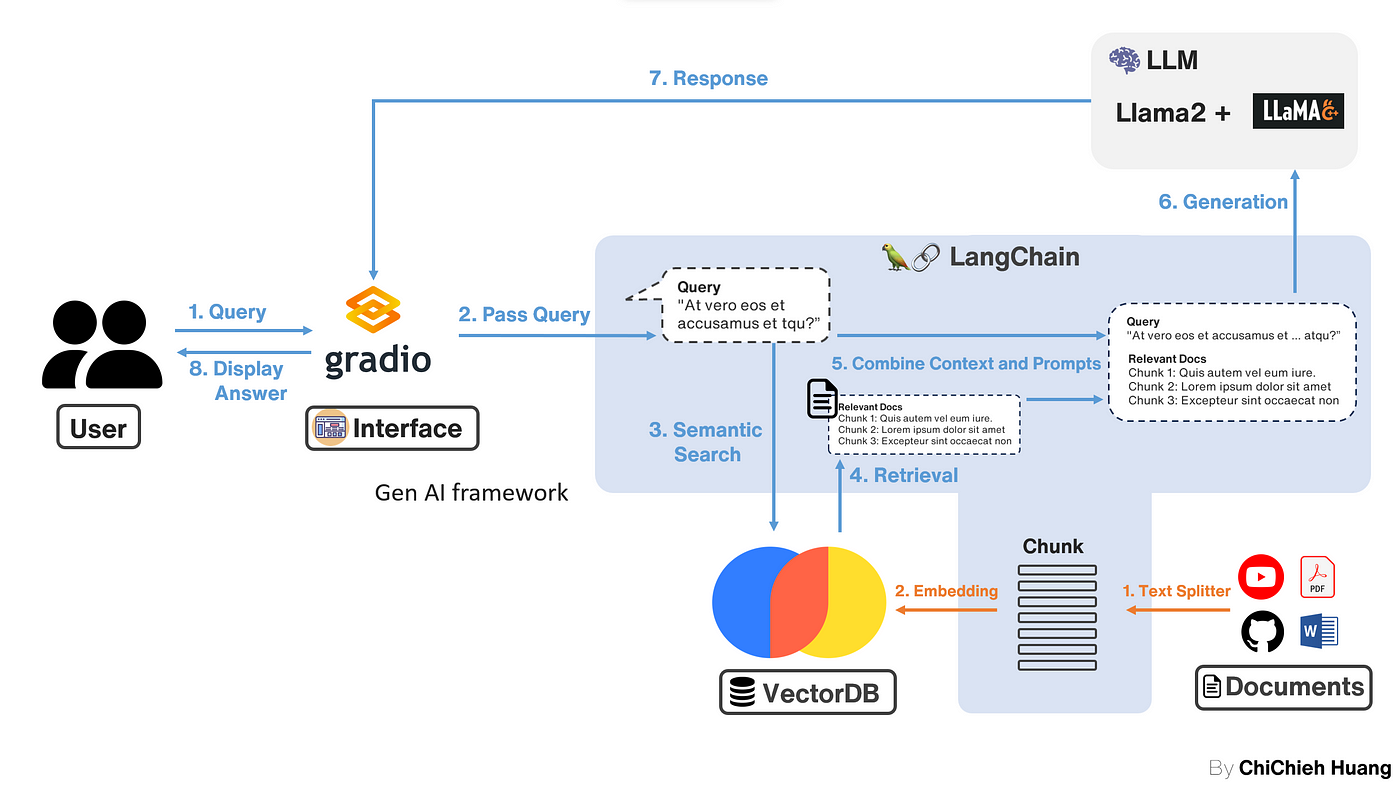
RAG 服務範例
在這篇文章中,會帶你一步一步架設自己的 RAG(Retrieval-Augmented Generation)系統,讓你可以上傳自己的 PDF,並且詢問 LLM 關於 PDF 的訊息,這篇教學注重在上圖藍底色的部份,也就是先不接 Gradio (想看接好的可以參考 下篇 )。相關的 tech stack 有以下幾個:
- LLM : Llama2
- LLM API: llama.cpp service
- Langchain
- Vector DB : ChromaDB
- Embeding : sentence-Tranformers
其中的核心在於 Langchain,它是用於開發由語言模型支援的應用程式的框架,LangChain 就像膠水一樣,有各種接口可以將 LLM 模型與其他工具和數據源連接,不過現在 LangChain 正在蓬勃發展中,許多文件或 API 改版很多,以下我使用最簡單的方式示範。
步驟1. 環境設置
首先設置 python 環境,我使用 conda 創建環境,並安裝以下 library,我在 Jupyter 環境完成範例,完整 code 可以在 github 找到。
1
2
3
4
5
6
7
8
# python=3.9
ipykernel
ipywidgets
langchain
PyMuPDF
chromadb
sentence-transformers
llama-cpp-python
步驟2. 讀入檔案處理並匯入 DB
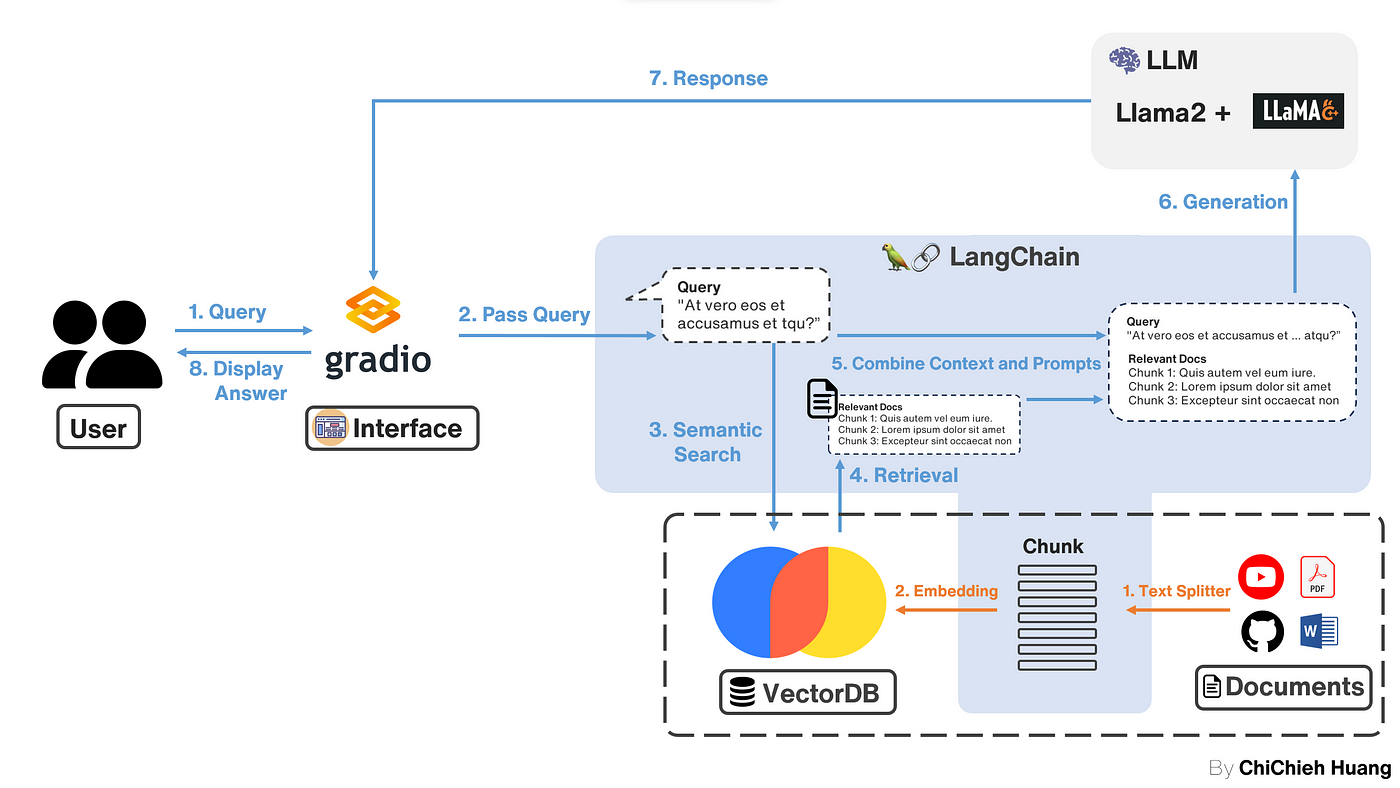
首先我們要將外部資訊處理後,放到 DB 中,以供之後查詢相關知識,這邊的步驟對應到上圖框起來的部分,也就是橘色的 1. Text splitter 與 2. Embedding
a) . 使用文件載入器
Langchain 提供了很多文件載入器,總計大概有 55 種,包含 word, csv, PDF, GoogleDrive, Youtube 等,使用方式也很簡單,這邊我創建了一個虛擬人物 Alison Hawk 的 PDF 資訊,並使用 PyMuPDFLoader 讀入,Alison Hawk 的PDF 資訊可以在 github 查看。注意 PyMuPDFLoader 需要安裝 PyMuPDF 才能使用。
1
2
3
from langchain.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("LangChain/Virtual_characters.pdf")
PDF_data = loader.load()
b) . 使用 Text splitter 分割文件
Text splitter 會將文件或文字分割成一個個 chunk,用以預防文件的資訊超過 LLM 的 tokens,有一些研究在探討如何將 chunk 優化,可以參考我的另一篇 文章 。
這步驟常用的工具 RecursiveCharacterTextSplitter 與 CharacterTextSplitter ,差別在於 RecursiveCharacterTextSplitter 如果區塊大小超過指定閾值,它也會遞歸地將文字分割成更小的區塊。LangChain 2種方式皆有提供,另外主要參數為以下:
- chunk_size:決定分割文字時每個區塊中的最大字元數。它指定每個區塊的大小或長度。
- chunk_overlap:決定分割文字時連續區塊之間重疊的字元數。它指定前一個區塊的多少應包含在下一個區塊中。
1
2
3
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=5)
all_splits = text_splitter.split_documents(PDF_data)
c) . 載入 Embedding model
接著使用 Embedding 將步驟 b)分割的 chunk 文字轉換為向量,LangChain 提供了許多 Embedding model 的接口,如OpenAI、Cohere、Hugging Face、Weaviate 等,可以參考 LangChain官網 。
這邊我使用 Hugging Face 的 Sentence Transformers,它提供了許多種 pretrain 模型,可以根據你的需求或應用情境選擇,我選擇 all-MiniLM-L6-v2 ,其他 model 細節可以看到 SBERT.net 或 HuggingFace 。注意要先安裝 sentence-Tranformers 才能使用。
1
2
3
4
5
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "sentence-transformers/all-MiniLM-L6-v2"
model_kwargs = {'device': 'cpu'}
embedding = HuggingFaceEmbeddings(model_name=model_name,
model_kwargs=model_kwargs)
d) . 將 Embedding 結果匯入 VectorDB
Embedding 後的結果我們會儲存在 VectorDB 中,常見的 VectorDB 有 Chroma、Pinecone、FAISS等,這邊我使用 Chroma 來實作。Chroma 跟 LangChain 的整合得很好,可以直接使用 LangChain 的接口來做。
1
2
3
4
5
# Embed and store the texts
# Supplying a persist_directory will store the embeddings on disk
from langchain.vectorstores import Chroma
persist_directory = 'db'
vectordb = Chroma.from_documents(documents=all_splits, embedding=embedding, persist_directory=persist_directory)
步驟3. 啟用 LLM 服務
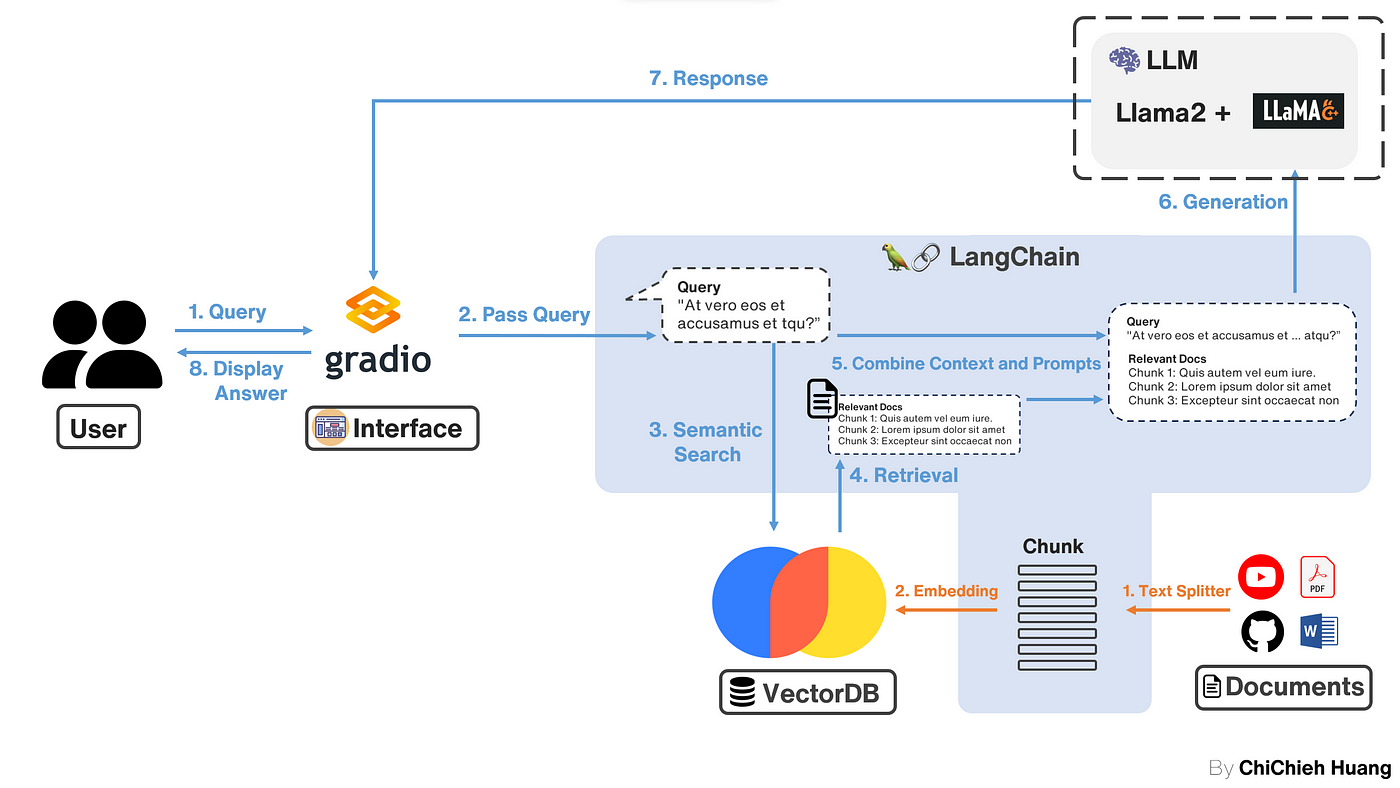
有兩種方法啟動你的 LLM 模型並連接到 LangChain。一是使用 LangChain 的 LlamaCpp 接口來實作,這時候是由 LangChain 幫你把 llama2 服務啟動;另一個方法是用其他方式架設 Llama2 的 API 服務,例如使用 llama.cpp 的 server 啟動 API 服務等,這部分細節可以看到我的另一篇 llama.cpp教學 。我 2 個方式都會示範,你可以選擇適合你的方案。
a) . 使用 LangChain 的 LlamaCpp
使用 LlamaCpp 接口載入 model,它會幫你啟動 Llama 的服務,這方法較簡單,直接使用下面 code 就可以執行,model_path 指定到你的模型中,例子中我使用量化過後的 Llama2 Chat。注意這邊要安裝 llama-cpp-python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
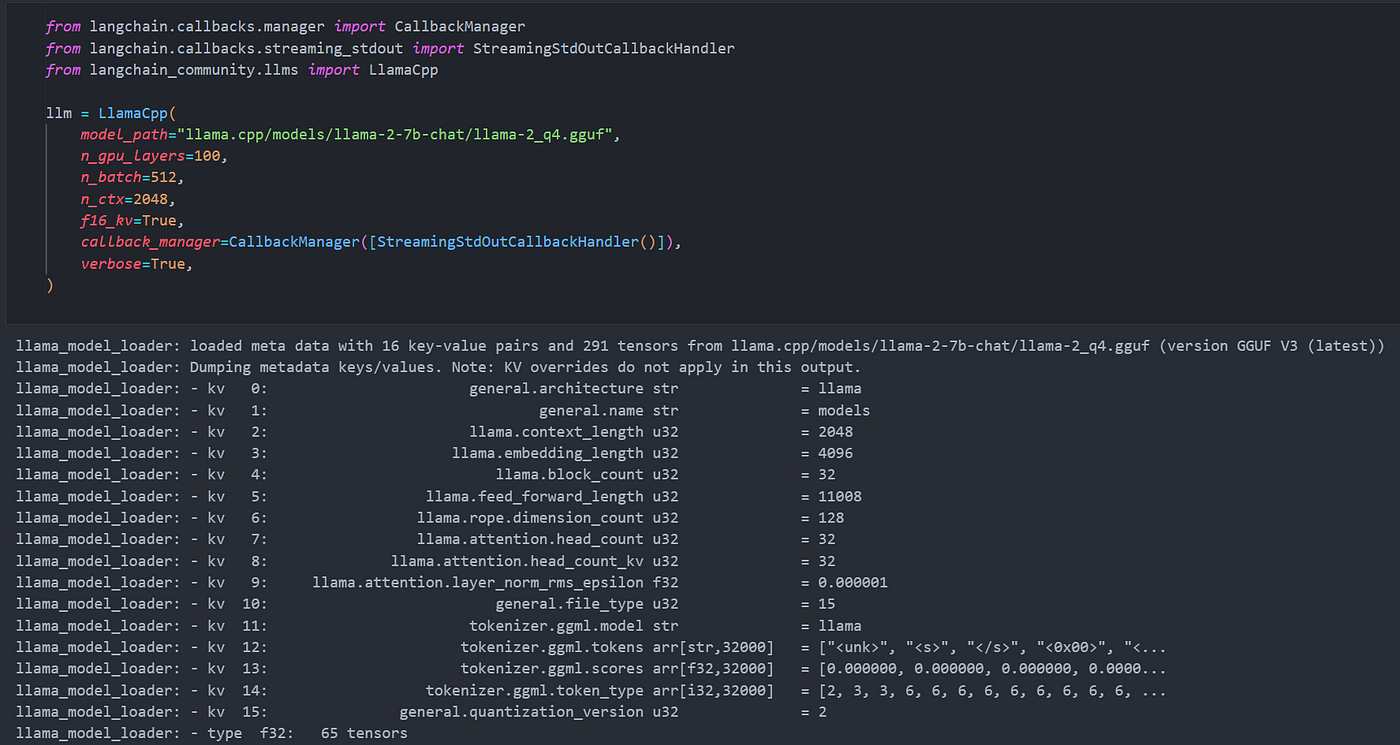
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain_community.llms import LlamaCpp
model_path = "llama.cpp/models/llama-2-7b-chat/llama-2_q4.gguf"
llm = LlamaCpp(
model_path=model_path,
n_gpu_layers=100,
n_batch=512,
n_ctx=2048,
f16_kv=True,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
verbose=True,
)
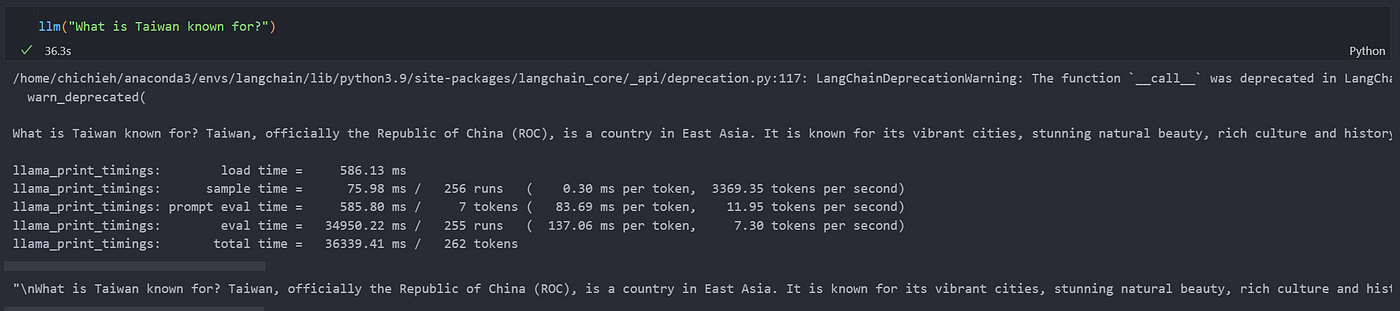
可以使用測試看看有沒有 llm 服務啟動沒:
1
llm("What is Taiwan known for?")
b) . 使用已架設的 API 服務
如果你已經使用其他方式架設 LLM 的 API 服務,或者是使用 openai 的 API 的話,你需要使用 LangChain 的 ChatOpenAI 接口。我這邊示範是 llama.cpp 的 server 服務 ( llama.cpp教學 ),它提供了類別OpenAI的API,因此我們能直接用同個接口來操作,以下是該接口的一些相關參數:
- open_ai_key :由於並沒有使用真正的 OpenAI API,因此可以隨意填寫。
- openai_api_base :為模型API的Base URL
- max_tokens: 規範模型回答的長度
1
2
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(openai_api_key='None', openai_api_base='http://127.0.0.1:8080/v1')
步驟4. 設定你的 Prompt
一些 LLM 可以使用特定的 Prompt。例如,Llama 可使用特殊 token,細節可以參考 twitter 。我們可以使用 ConditionalPromptSelector 根據模型類型設定 Prompt,如以下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from langchain.chains import LLMChain
from langchain.chains.prompt_selector import ConditionalPromptSelector
from langchain.prompts import PromptTemplate
DEFAULT_LLAMA_SEARCH_PROMPT = PromptTemplate(
input_variables=["question"],
template="""<<SYS>> \n You are an assistant tasked with improving Google search \
results. \n <</SYS>> \n\n [INST] Generate THREE Google search queries that \
are similar to this question. The output should be a numbered list of questions \
and each should have a question mark at the end: \n\n {question} [/INST]""",
)
DEFAULT_SEARCH_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an assistant tasked with improving Google search \
results. Generate THREE Google search queries that are similar to \
this question. The output should be a numbered list of questions and each \
should have a question mark at the end: {question}""",
)
QUESTION_PROMPT_SELECTOR = ConditionalPromptSelector(
default_prompt=DEFAULT_SEARCH_PROMPT,
conditionals=[(lambda llm: isinstance(llm, LlamaCpp), DEFAULT_LLAMA_SEARCH_PROMPT)],
)
prompt = QUESTION_PROMPT_SELECTOR.get_prompt(llm)
prompt
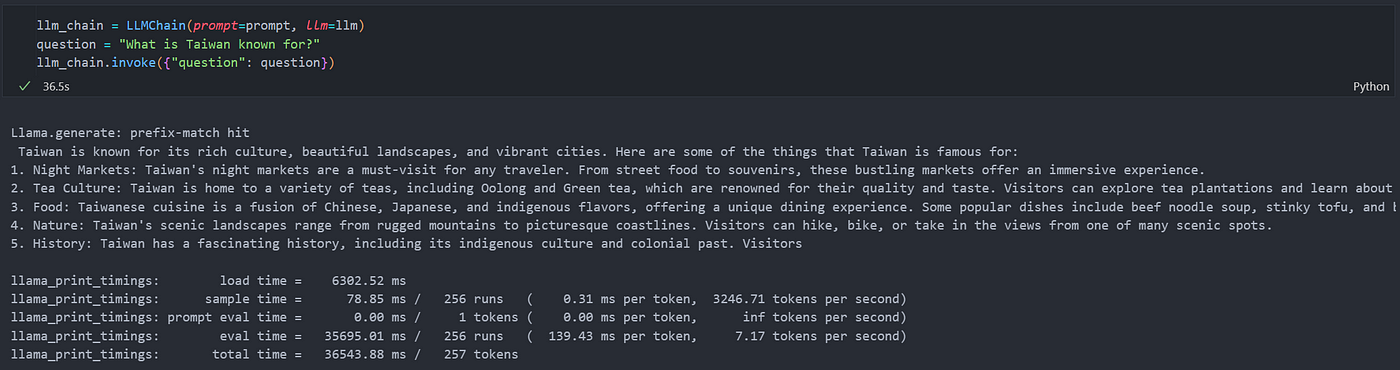
使用 LLMChain 將 prompt 與 llm 接在一起,另外 LangChain 最近的改版使用 invoke 替代 run ,當你看到其他文章使用 run 時可以注意。
1
2
3
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "What is Taiwan known for?"
llm_chain.invoke({"question": question})
實機畫面:
步驟5. Text Retrieval + Query LLM
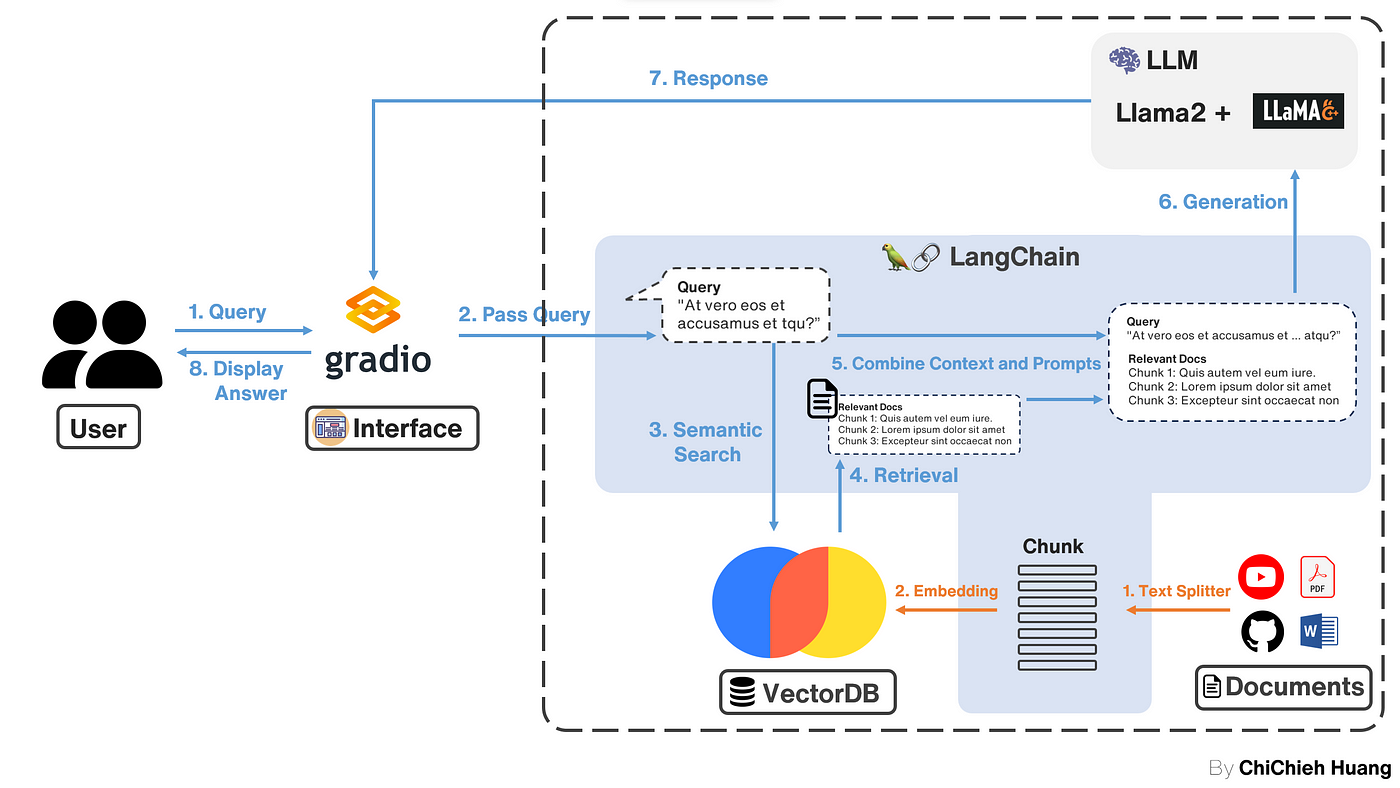
上面我們將 PDF 資訊匯入 DB 中,並且啟動了 LLM 服務,接下來我們要將整個 RAG 的步驟串起來:
- User 發來 QA
- 從 DB 中 Text Retrieval
- 結合 QA 與 Text Retrieval 發送給 LLM
- LLM 根據資訊回答
首先我們要先創建 Retriever,它可以根據非結構化QA 返回相應文件,LangChain 提供了很多種方式,也整合進第三方的工具,目前有很多研究在探討如何根據 QA 找尋對應的文件。我這邊使用的是 Vectorstore 的方式,其他種類可以參考 Retrievers 。
接著使用 RetrievalQA 結合 Retriever 與 QA 與 llm,注意 VectorDBQA 的功能已經被棄用,現在都使用 RetrievalQA ,如果看到別的文章使用可以注意。
1
2
3
4
5
6
7
8
retriever = vectordb.as_retriever()
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
步驟6. 使用你的 RAG
到這裡我們就串好整個 RAG 的流程,接下來我們來問問 Alison Hawk 的訊息(PDF 紀錄的虛擬人物名稱)
1
2
query = "Tell me about Alison Hawk's career and age"
qa.invoke(query)
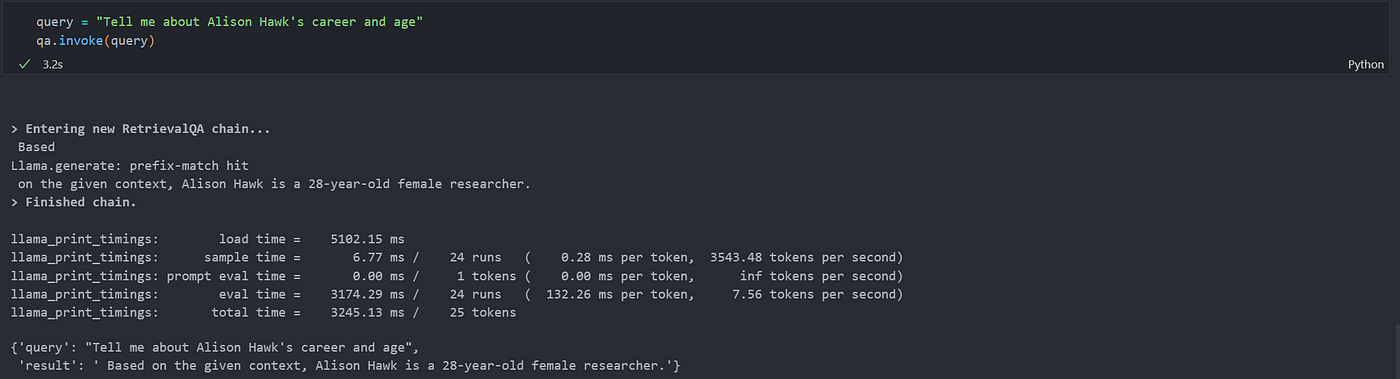
可以看到 LLM 有拿到從 DB 中拿到我們上傳的 Alison Hawk 的 PDF 訊息,並且得知她是一位 28 歲的 researcher。
