RAG實作教學,Streamlit+LangChain+Llama2
我們將重點放在如何使用 Streamlit 來建立一個視覺化的操作介面,以便 Demo 整個RAG(Retrieval-Augmented Generation)的工作流程。
RAG實作教學,Streamlit+LangChain+Llama2 | Demo 版本
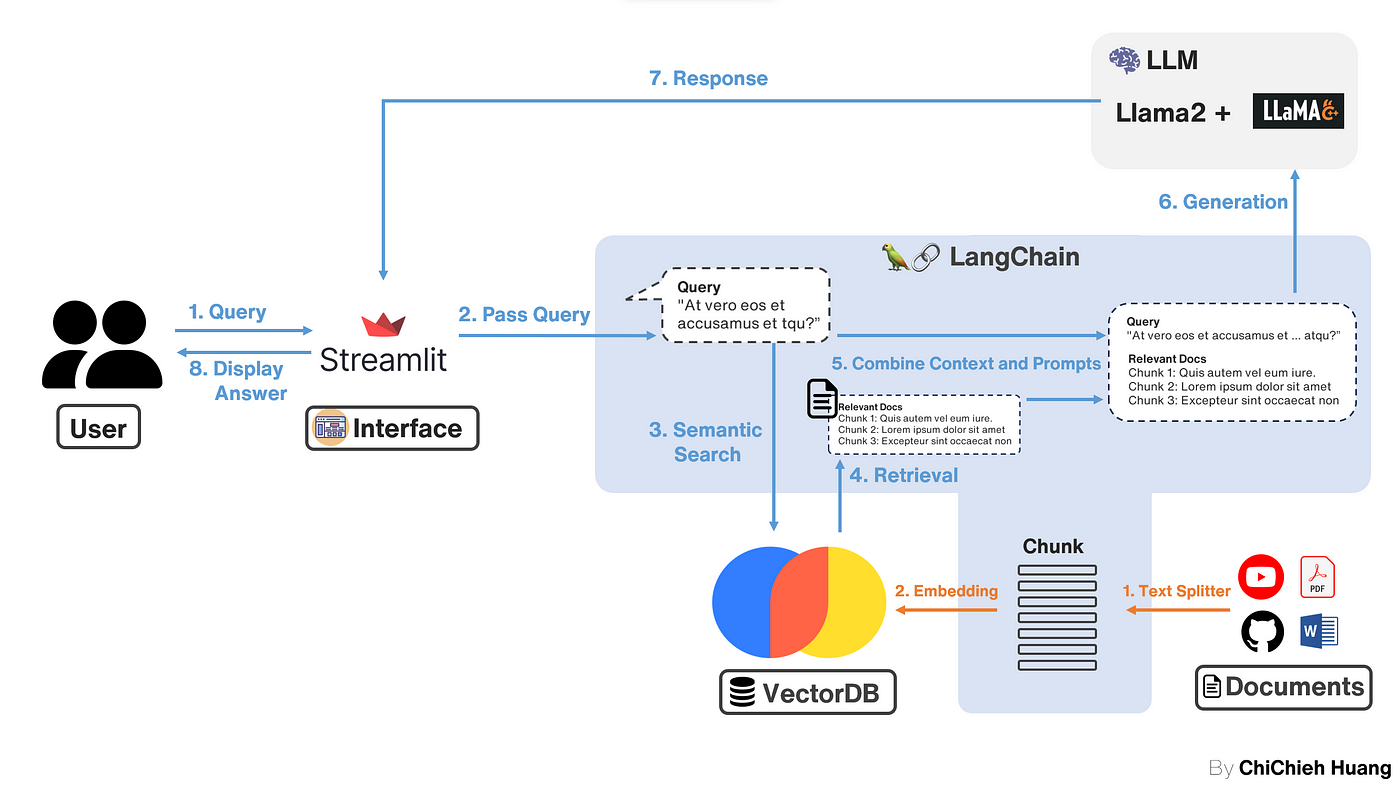
上一篇 示範了如何實作 RAG(Retrieval-Augmented Generation)的核心部分。 這次,我們將重點放在如何使用 Streamlit 來建立一個視覺化的操作介面,以便 Demo 整個 RAG 的工作流程。與上篇介紹的不同的是我把 Gradio 換成 streamlit,因為我最近在寫 streamlit 的專案,相對比較熟悉,當然,你也可以選擇使用 Gradio 來達到相同的效果。
相關 Tech Stack:
- Python 3.7+
- LangChain : 一個強大的庫,用於建立和管理語言模型。
- Chroma : 用於處理和分析文字資料。
- Streamlit : 用於建構和分享美觀的資料應用。
- Llama2 或 OpenAI API : 選擇使用自建的 LLM 伺服器或是 OpenAI 提供的 API。
- PDF : 作為資訊的來源和查詢的基礎。
實現流程:
- 連接 LLM:在這個 Demo 中,我們可以選擇要使用自己架設的 LLM server 或使用 openAI API
- 文件上傳與處理:使用者可以上傳 PDF 文檔,系統會使用 Chroma 對文檔進行處理,包括文字分割和嵌入等操作。
- 資料儲存:處理後的資料會儲存到資料庫中,以便於後續的檢索和分析。
- 互動式查詢:使用者可以透過一個友善的介面向系統提問,系統會根據問題從資料庫中檢索相關信息,並利用 LLM 產生答案。
實際畫面:
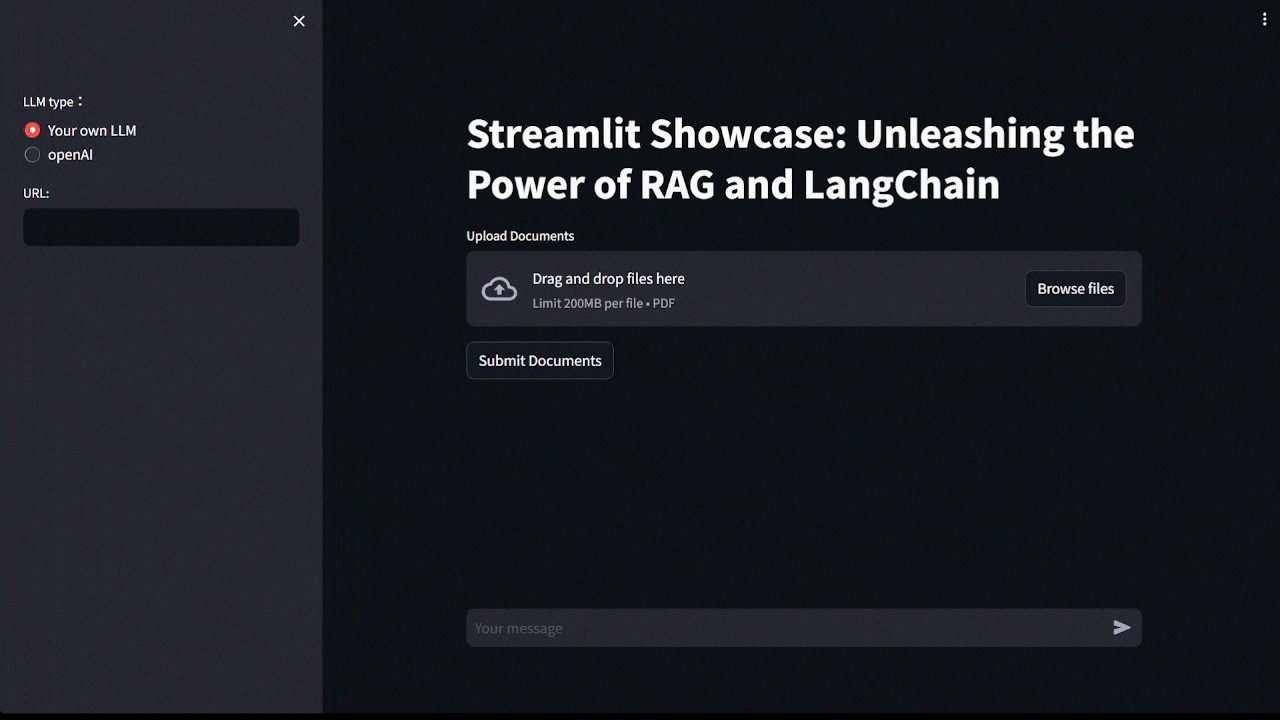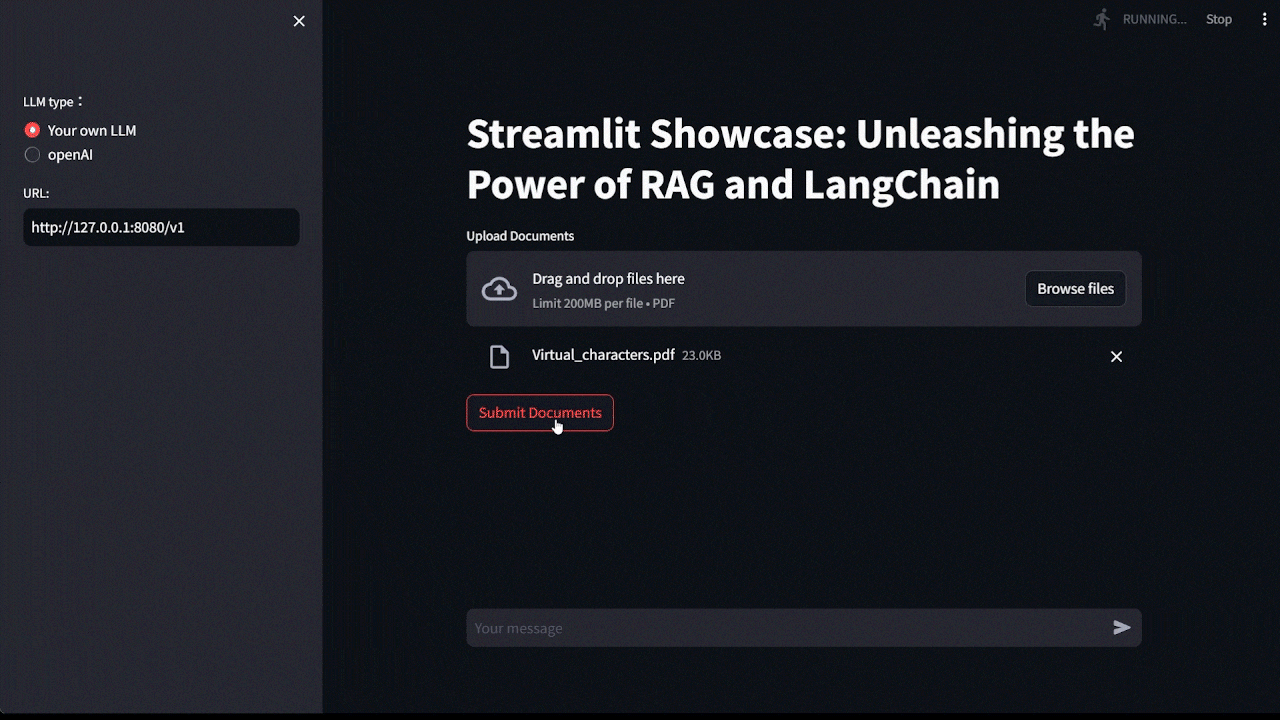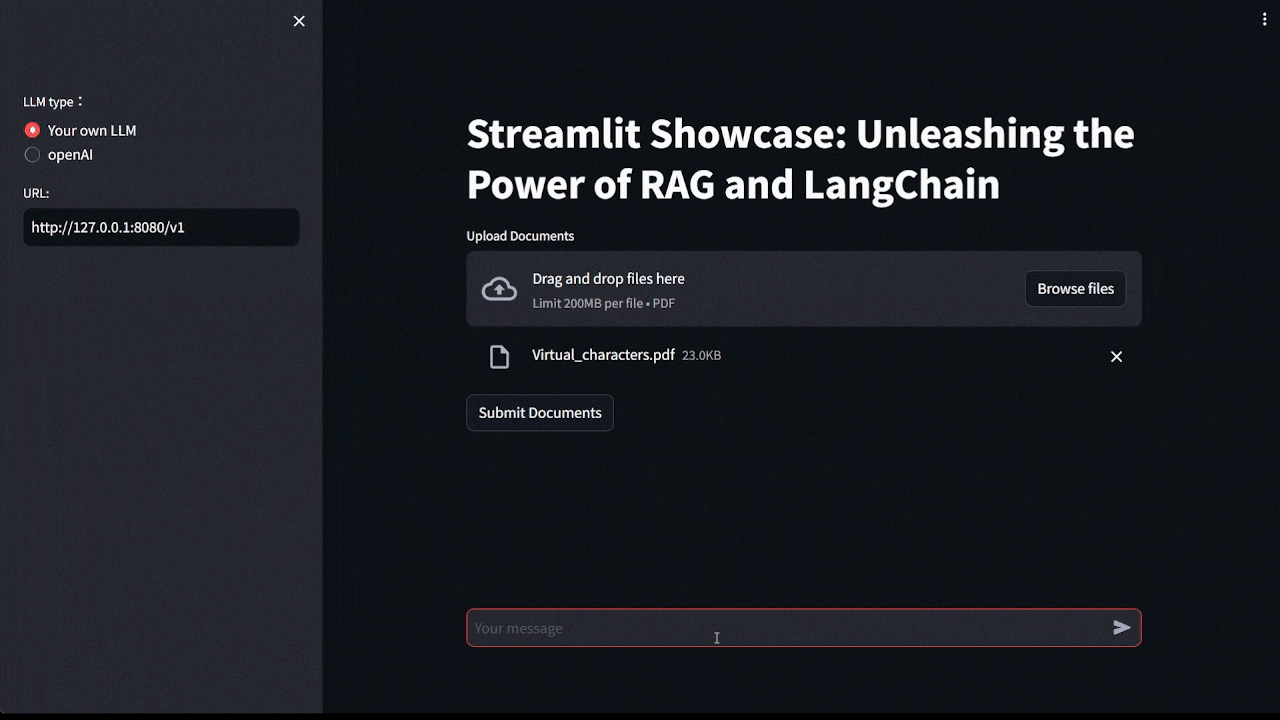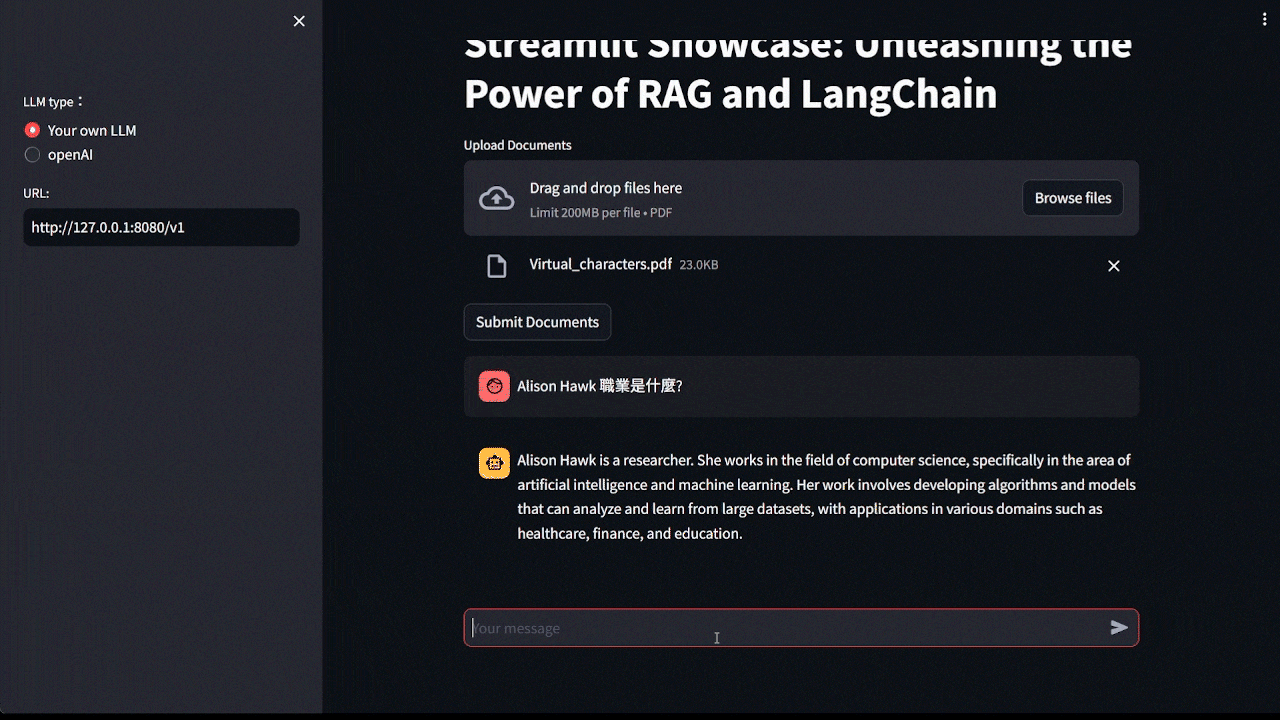
Demo 的畫面中,我是用自己本地的 LLM 模型,並使用 llama.cpp 開設 API service,因此你可以看到 URL 是: http://127.0.0.1:8080/v1,如果這部分不清楚可以參考 llama.cpp 教學 ,你也可以選擇使用 openAI API。
上傳 PDF 使用的文件一樣與上一篇一樣,是使用虛擬人物 Alison Hawk 的資訊,裡面記錄了他的職業與個性,因此你可以看到 Demo 中我詢問 Alison Hawk 的職業是甚麼,而 LLM 有拿到 PDF 的訊息準確回答。
建立你的 Demo
如果你對這個專案感興趣,並想親自嘗試建造和運行,我將 code 放在 github ,你可以藉由以下步驟快速架設你自己的 streamlit Demo:
步驟1. Clone 專案
1
2
git clone https://github.com/wsxqaza12/RAG_LangChain_streamlit.git
cd RAG_LangChain_streamlit
步驟2. 準備環境
1
2
3
conda create -n RAG_streamlit python=3.7
conda activate RAG_streamlit
pip install -r requirements.txt
步驟3. 啟動 streamlit
1
streamlit run rag_engine.py
完成上述步驟後,你應該可以看到一個友善的 Streamlit 應用程式介面。在這個介面上,你可以上傳 PDF,查詢訊息,並觀察 LLM 如何從你提供的資料中擷取資訊,注意如果你要使用你自己的 LLM,記得先在另外的 process 啟動。
希望這篇文章能幫助你更好地理解 RAG 的實現過程,並透過 Streamlit 創建出色的互動式 Demo。如果有任何問題,歡迎在專案的 GitHub 頁面上提出。
