AI Avatar | 虛擬人偶的製作與種類
虛擬人偶(Avatar)早已是我們數位生活中的一部分,從遊戲角色到社交媒體的個性化形象,它們一直以多種形式出現在不同場合。然而,隨著 GenAI 的強勢崛起,AI 驅動的 Avatar(AI…
AI Avatar | 虛擬人偶的製作與種類
虛擬人偶(Avatar)早已是我們數位生活中的一部分,從遊戲角色到社交媒體的個性化形象,它們一直以多種形式出現在不同場合。然而,隨著 GenAI 的強勢崛起,AI 驅動的 Avatar(AI Avatar)正以前所未有的速度進化,變得更聰明、更生動,也更能應用在我們的日常需求,如去年推出的的民視 AI 主播、客服虛擬人、肯德基的點餐機器人等,AI Avatar 已逐漸融入我們的生活中。

民視 AI 主播 - 敏熙(Source: 民視新聞網)
可以預期的是未來 AI Avatar 的進步會越來越快,但就 Avatar 製作本身就是一大領域,因此本篇旨在探討各種類型 Avatar (如下圖),我會介紹其製作方式以及應用範圍,希望能跟大家一起了解這個領域的潛力與未來。
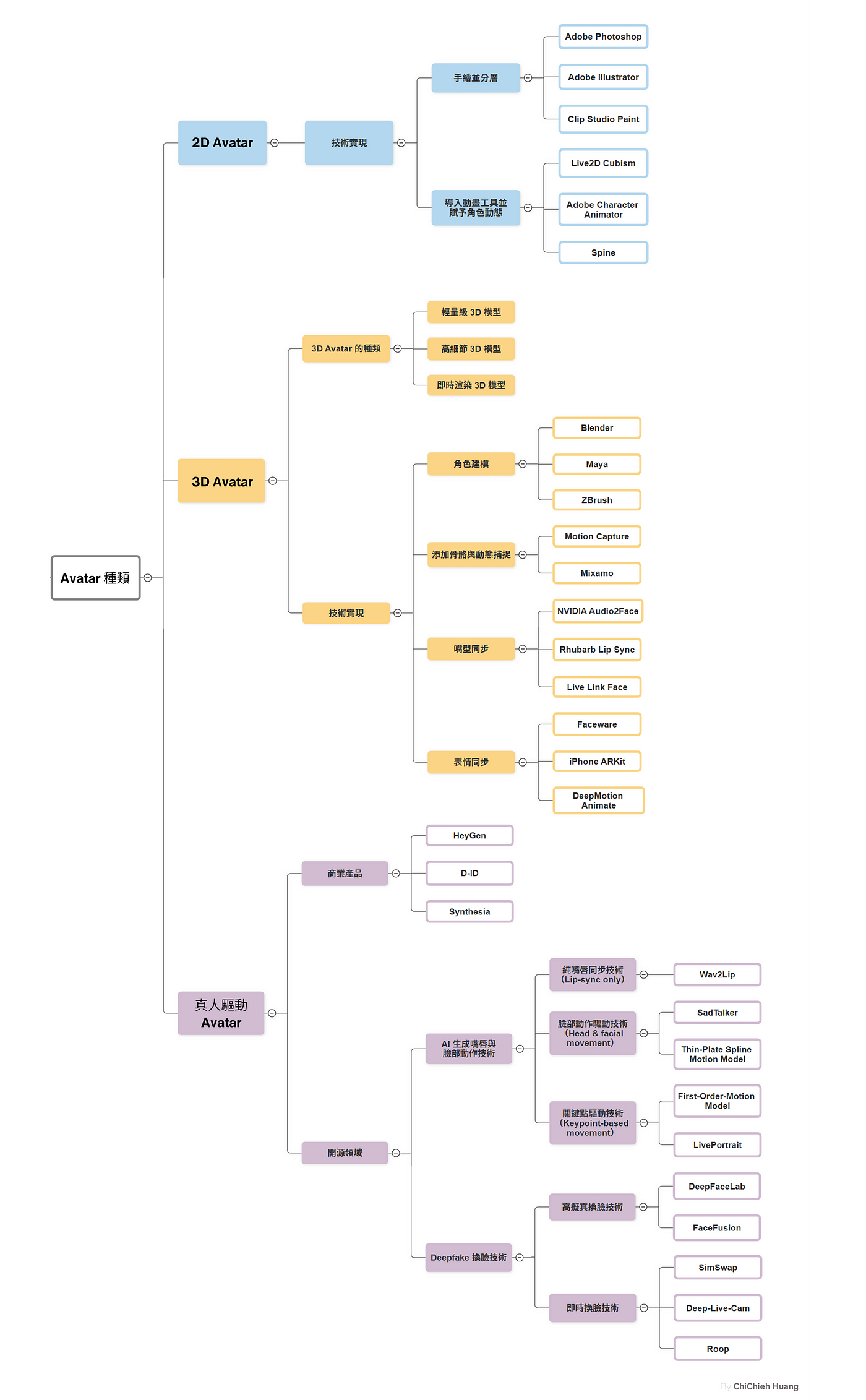
文章的 Avatar 種類分類
一、AI Avatar 製作
AI Avatar 的製作可以拆解為兩大核心部分: 內容生成 與 Avatar 的製作呈現 。這兩種技術的結合,便能製作出是一個能夠「聽懂」、「回應」和「表達」的智能化身,讓使用者擁有更貼近真實的互動體驗。
內容生成
無論 Avatar 製作有多麼細緻,都還是需要結合 內容生成 的結果,才能帶給使用者生動自然的互動體驗,這部分主要由 GenAI 技術主導,包括文字轉語音(TTS)、大型語言模型(LLM)以及語音識別(ASR)等技術的協作。這些技術負責為Avatar 賦予「靈魂」,例如生成自然流暢的對話、理解並回應使用者的語音指令,或是創造符合歷史對話的內容,讓 AI Avatar 能夠真正理解人類的指令並與其互動,下圖是對話式 AI Avatar 內容生成的流程。
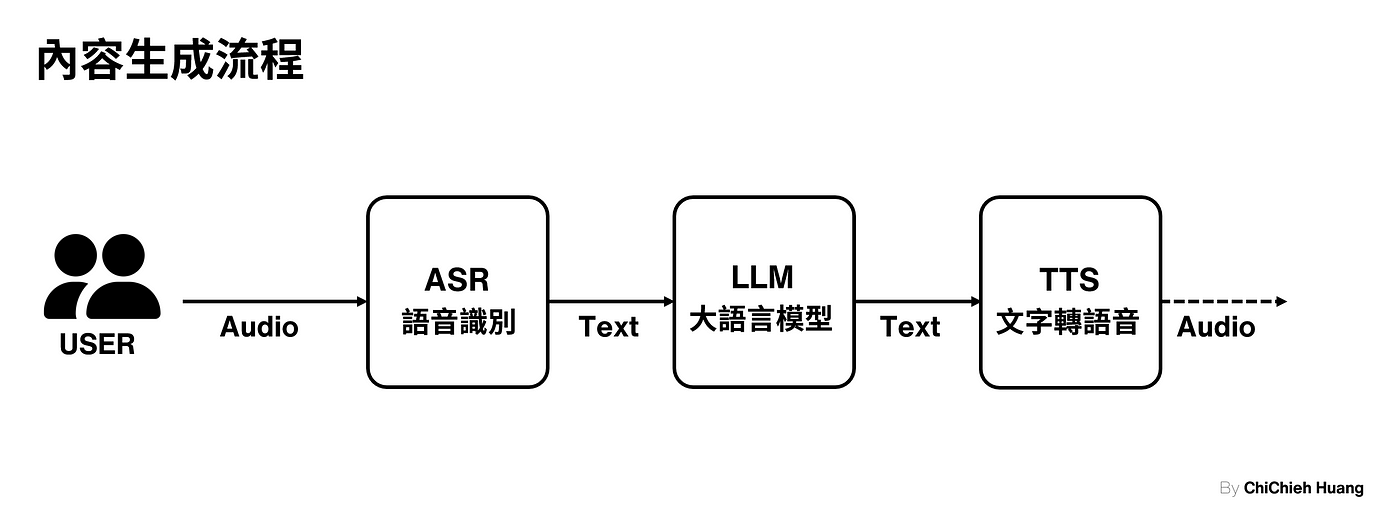
以語音驅動為初始的過程
內容生成 的完整流程可以參考我之前的 文章 ,這邊便不再贅述。
Avatar 的製作呈現
有了內容生成後,我們便需要一個 Avatar 來做回應,因此這步驟的重點在於外觀設計與行為建構,其會根據 Avatar 的用途與種類而有所差異。例如,遊戲中的 3D 虛擬角色與客服平台上的 2D 動態頭像,其製作需求與技術細節截然不同。由於種類繁雜,因此接下的篇幅都會注重在探討有什麼樣類型的 Avatar,以及各自的製作流程與應用。
二、Avatar 種類
我個人將 Avatar 分為 3 大類: 2D Avatar 、 3D Avatar 與 真人驅動的Avatar 。每種類型都有其獨特的特點與應用場景,接下來讓我們逐一探討。

不同 Avatar 種類示意
1. 2D Avatar
2D Avatar 以平面形式呈現,通常具有動畫化的外觀,風格可涵蓋卡通、動漫或手繪等。這類 Avatar 因製作相對較簡單,適用於直播、影片、品牌形象等多種情境。

(1) . 技術實現
- 手繪並分層: 使用常見的繪圖工具如 Adobe Photoshop 、 Adobe Illustrator 或 Clip Studio Paint ,繪製角色並按照部位(如臉部、眼睛、嘴巴、手臂等)分層。每個部件需細緻劃分,確保後續動畫能夠靈活調整。
- 導入動畫工具並賦予角色動態: 使用 Live2D Cubism 、 Adobe Character Animator 、 Spine 等專業工具將分層的角色圖片導入,設置骨骼系統與關節點,接著定義角色的動態範圍(如眨眼、點頭、嘴巴同步),並調整動作的自然度與流暢度。
(2) . 應用範圍
- 直播與內容創作 :許多 Vtuber 使用 2D 虛擬形象進行直播,吸引喜歡動漫風格的觀眾。
- 遊戲與教育 :角色化的 2D 圖像能使教學或遊戲內容更加親切,適合兒童教育等應用。
2. 3D Avatar
3D Avatar 是基於三維模型創建的虛擬角色,相較於2D,能夠展示更真實的細節與動態。
(1) . 3D Avatar 的種類
3D的種類非常多,下圖為依照「真實度」與「成熟度」來做分類。
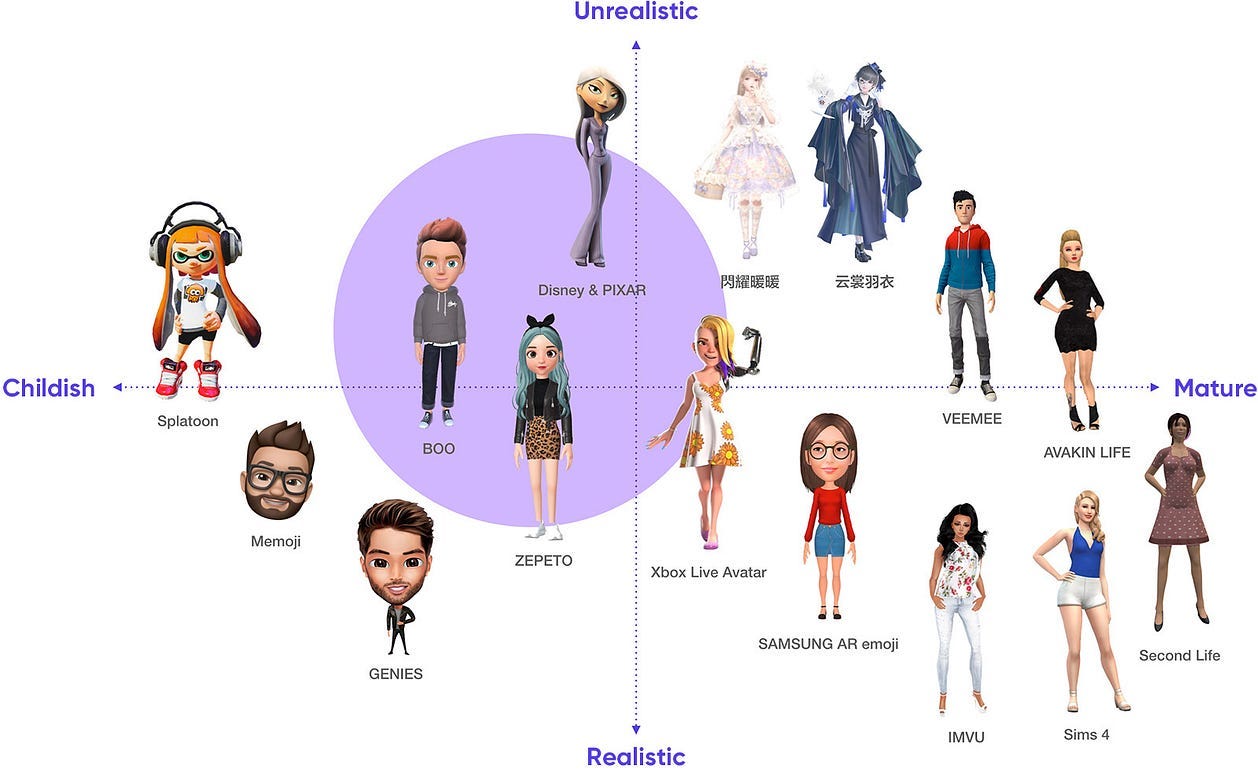
人物型 3D Avatar 象限圖(Source: Tencent ISUX)
另外還可以根據技術細節和應用場景進行分類,以下是幾個常見 3D avatar 類型的介紹:
A. 低多邊形與輕量級 3D 模型(適合網頁、AR、電商展示)
這類模型以低多邊形(low-poly)為主,強調文件體積小、渲染速度快,適合即時傳輸與瀏覽器加載。常見格式包括 GLTF(適合網頁和 WebAR)、USDZ(適合 iOS ARKit)以及 FBX(部分 AR/VR 平台支援)。
應用場景:
- 電商展示 :虛擬試穿、3D 商品 360 度瀏覽
- AR/VR 互動 :手機 AR 遊戲、虛擬家具擺設
- 網頁端應用 :線上 3D 角色展示
B. 高細節與電影級 3D 模型(適合電影、雕刻、工業設計)
這類模型通常具有高細節雕刻,適用於需要精確渲染的場景,例如電影、動畫、工業設計與醫療應用。常見格式包括 OBJ(通用 3D 格式)、Alembic(適用於電影與動畫的動態模型)、ZTL(ZBrush 雕刻專用格式),而 STL 則主要用於 3D 列印。
應用場景:
- 電影與動畫 :高細節角色建模、VFX 視覺特效
- 工業設計 :精密零件、產品原型開發
- 醫療應用 :牙科 3D 列印、醫療掃描建模
C. 遊戲與即時渲染 3D 模型(適合遊戲、VTuber、元宇宙)
這類模型專為即時渲染設計,強調效能與視覺品質的平衡,適合用於遊戲引擎或即時互動的應用。常見格式包括 FBX(遊戲引擎通用格式)、GLTF(開源遊戲與 WebXR)、以及 VRM(專為 VTuber 角色設計的標準格式)。
應用場景:
- 遊戲角色 :適用於 Unreal Engine、Unity 的 3D 角色
- VTuber 角色 :虛擬主播、直播互動角色
- 元宇宙應用 :虛擬社交、數字分身
(2) . 技術實現:製作 3D Avatar 的步驟
- 角色建模: 使用 Blender 、 Maya 或 ZBrush 建立角色的基本形態,設計包括身體比例、面部特徵與服裝等細節。遵循拓撲結構設計,確保模型具有動畫友好的多邊形佈局。
- 添加骨骼與動態捕捉: 設置骨架並權重綁定(Rigging),為角色賦予動作控制能力,利用 Motion Capture 技術捕捉真人動作,或使用 Mixamo 產生動作應用於角色。
- 嘴型同步(Lip Sync) :嘴型同步可透過 AI 驅動或音頻分析技術來實現。以下是幾種常見方法: ● NVIDIA Audio2Face :基於深度學習,能夠根據語音自動生成逼真的嘴部動畫,適合高品質 AI Avatar。 ● Rhubarb Lip Sync :開源工具,根據音頻分析語音內容並生成嘴型動畫,適合遊戲或動畫製作。 ● Live Link Face (適用於 Unreal Engine):透過 iPhone ARKit 進行即時臉部捕捉,驅動嘴型動畫。
- 表情同步(Facial Animation) :使用 Blendshape(混合變形)或骨架驅動技術捕捉並驅動角色的臉部表情。 ● Faceware :專業的臉部捕捉技術,常用於電影級角色動畫。 ● iPhone ARKit :透過 TrueDepth 相機進行高精度臉部追蹤。 ● DeepMotion Animate :利用 AI 推算出符合語音的臉部動畫。
(3) . 應用範圍
一般而言, AI Avatar 主要使用 輕量級 3D 模型 和 遊戲與即時渲染 3D 模型 。這是因為 AI Avatar 需要兼顧運算效率與即時互動,同時保持視覺表現。
- 輕量級 3D 模型: 適合應用於虛擬助理、線上客服等場景,確保低延遲與流暢的動畫。
- 遊戲與即時渲染 3D 模型: 則更適合 VTuber 直播、元宇宙互動和遊戲內 NPC,能夠提供更高的沉浸感與多樣的動畫表現,如上古卷軸5 便有人開發將 LLM 導入 NPC 當中。
3. 真人驅動的 Avatar
這類技術能將真人的影像與 AI 模型結合,使 Avatar 能夠流暢地模仿真人的嘴唇運動、頭部動作,甚至完整的表情與肢體動作。
目前市面上有許多相關商業產品,如 HeyGen、D-ID、Synthesia 等,它們可以讓使用者透過輸入文字或語音,生成高度擬真的 Avatar 影片,大多的商業產品功能皆差不多,且有支援 API,因此你也可以直接使用它們的 API 來完成你的產品。

真人驅動的 Avatar - 商業產品
商業產品結合了非常多技術做整合,不過使用開源領域也能做到類似的事,但需要較熟悉這個領域的技術分類,這類技術大致可以分為 「語音驅動」 及 「影像驅動」 兩種;如果再更細區分,我個人主要會將這類技術分為以下幾種:
(1) . AI 生成嘴唇與臉部動作技術
A. 純嘴唇同步技術(Lip-sync only)
這類技術專注於讓人物的嘴型與語音同步,常見的代表技術有 Wav2Lip ,其核心能力在於將語音內容與目標影像無縫結合,確保人物的嘴型動作與發音一致。
Wav2Lip 開源在 Github ,並有提供 Colab Notebook 給大家直接實作,有興趣可以試試。
應用領域 :
- 影片後製:為無聲影像補上自然的口型動畫。
- AI 數位人:讓 AI 助理、數位主播能夠「說話」。
- 教育與語言學習:讓虛擬導師能夠發音教學。
B. 臉部動作驅動技術(Head & facial movement)
此類技術不僅能同步嘴唇,還能生成頭部運動與部分表情變化,使 Avatar 的動作更具真實感。代表技術包括 SadTalker 和 Thin-Plate Spline Motion Model (TPSMM) ,兩者皆開源在 Github , 這些技術能夠讓靜態圖片轉變為具有語音同步與頭部運動的影片。
應用領域 :
- AI 企業形象:企業可利用 AI Avatar 製作行銷影片。
- 歷史照片復原:讓過去的歷史人物「活」起來。
- AI 聊天機器人:讓虛擬助手具備更生動的表情與動作。
C. 關鍵點驅動技術(Keypoint-based movement)
這類技術透過關鍵點驅動影像中的臉部動作,讓 AI 模型能夠模仿真人的完整表情與頭部運動。常用技術包括 First-Order-Motion Model (FOMM) , 也可以使用整合 FOMM 的 LivePortrait 。
應用領域 :
- AI 動畫角色:讓 AI 生成的角色能模仿真人表情。
- 虛擬直播:虛擬主播可透過 AI 進行即時互動。
- 影像修復:幫助改善舊影片或低解析度影像的動態表現。
(2) . Deepfake 換臉技術(Face Swapping)
除了讓 AI 角色根據語音和驅動影像產生動作外,另一類技術則是 換臉技術 ,可分為 需要訓練的高擬真換臉技術 和 即時換臉技術 。
A. 需要訓練的高擬真換臉技術
這類技術透過深度學習進行換臉,生成效果細膩但需要訓練時間。代表技術包括 DeepFaceLab 和 FaceFusion ,其中 FaceFusion 是一款簡化版的 DeepFaceLab,很適合一般用戶使用。
應用領域 :
- 影片換臉 (如電影、短片後製)。
- AI 創意內容生成 (如 AI 創作、角色扮演)。
B. 即時換臉技術(Real-time Face Swapping)
即時換臉技術能讓使用者在直播或影片通話中即時替換臉部,應用於 VTuber 直播、AI 角色互動等場景。代表技術包括 SimSwap 、 Deep-Live-Cam 和 Roop ,這些技術透過 AI 演算法讓一個人的臉即時變成另一個人的臉,並保持原始影片的流暢度,大家應該常在短影音平台看到許多人在做類似的影片。
應用領域 :
- 虛擬主播(VTuber) :讓真人透過 AI 技術變成動漫或卡通角色。
- 直播角色扮演 :讓創作者能夠以不同的形象參與直播。
- AI 互動娛樂 :用於遊戲、社交媒體或 AI 客服機器人。
結論
GenAI 的崛起帶動了 AI Avatar 的發展,從簡單的 2D 到高度擬真的 3D Avatar,甚至能夠透過 AI 深度學習模仿真人的語音、表情與動作。這些技術已廣泛應用於 虛擬主播、企業客服、教育培訓、品牌行銷 等領域,降低了真人參與的成本,並提供更靈活的互動體驗。
我大膽推測未來 AI Avatar 的發展會朝向 更即時、更智能、更個性化 的方向邁進,尤其是注重在以下兩點:
- 多模態融合 :未來的 AI Avatar 將結合 手勢、情緒分析 ,甚至能夠理解使用者的表情與語氣,提供更自然的互動體驗。
- 低成本高擬真技術普及 :目前高擬真虛擬人偶的製作成本仍較高,未來隨著 AI 技術優化,普通用戶將能更輕鬆創建自己的 AI Avatar,應用於日常社交與商務場景。
