DeepSeek 本地部屬 | llama.cpp 與 ollama
DeepSeek 近期在 LLM 領域的發展炙手可熱,吸引了全球關注。在這篇文章我們使用較具彈性 llama.cpp,以及易於安裝 Ollama,一步一步帶大家示範如何快速在本地部屬 DeepSeek-r1 模型。
DeepSeek 本地部署 | llama.cpp 與 ollama
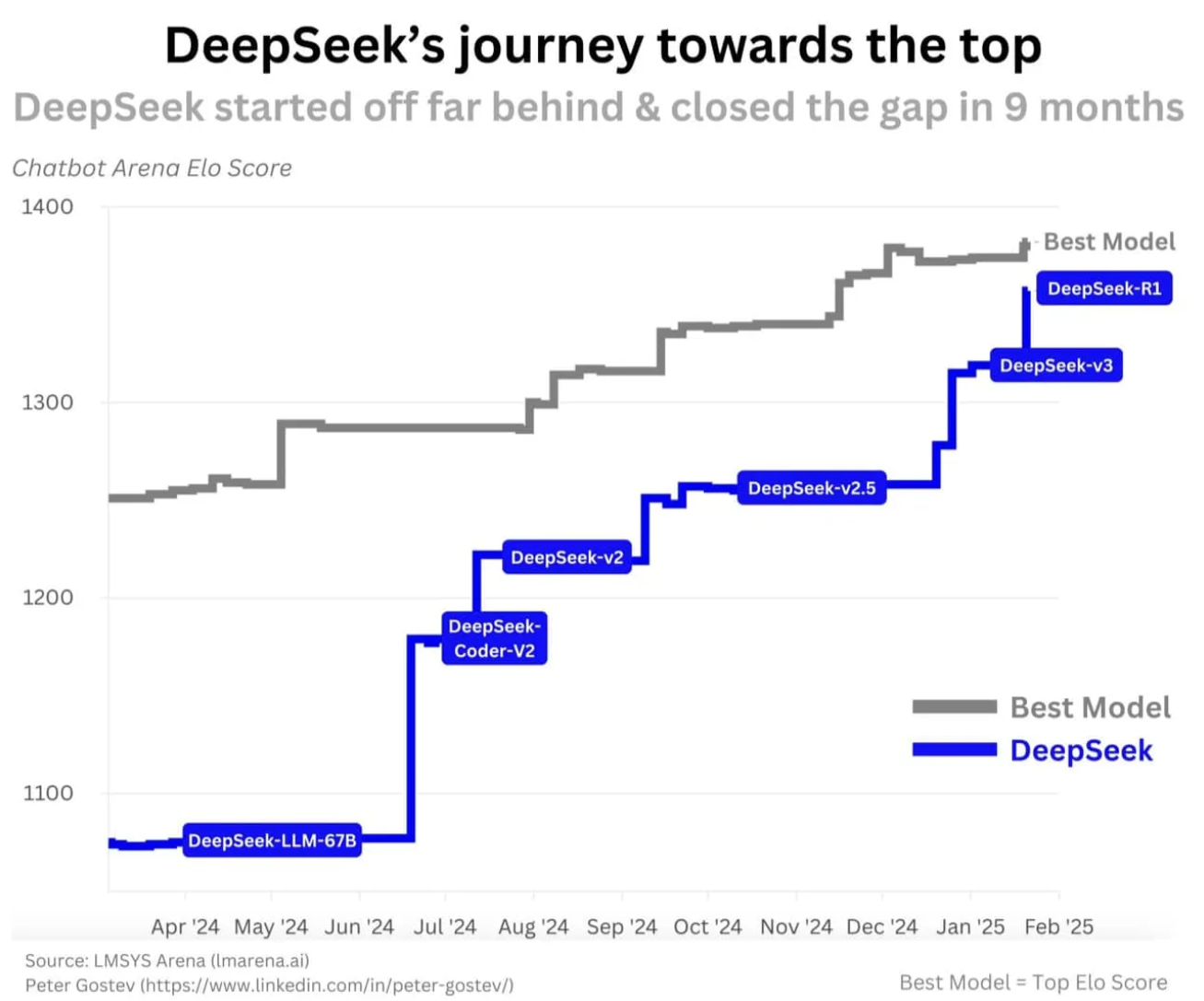
DeepSeek 近期在 LLM 領域的發展炙手可熱,吸引了全球關注。2024 年 12 月 26 日,DeepSeek 推出 DeepSeek-V3,專為數學、程式設計與中文應用優化,性能對標當時的 OpenAI GPT-4o。
在 V3 之後,DeepSeek 團隊持續優化架構,並於 2025 年 1 月 20 日 推出 DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill。相較於 V3,R1 採用更高效的計算方式,以更低的成本實現 OpenAI 在 2024 年 12 月 5日才發布的 Reasoning models — GPT-o1 相當的性能。且在 7 日後,2025 年 1 月 27 日,他們又推出了以視覺為基礎的 Janus-Pro-7B 模型。
雖然部分專家認為 R1 目前主要吸引用戶關注,在企業應用層面尚未帶來革命性變革,但令人興奮的是 DeepSeek 的模型是開源的,任何人都能使用 DeepSeek 的模型建立屬於自己的本地 LLM,並自由加入客製化功能。 因此本篇文章帶你實作 DeepSeek 本地化,並結合 llama.cpp 與 ollama 等工具,讓你能輕鬆打造專屬的 AI 模型。
一、本地運行 LLM 模型工具與模型選擇
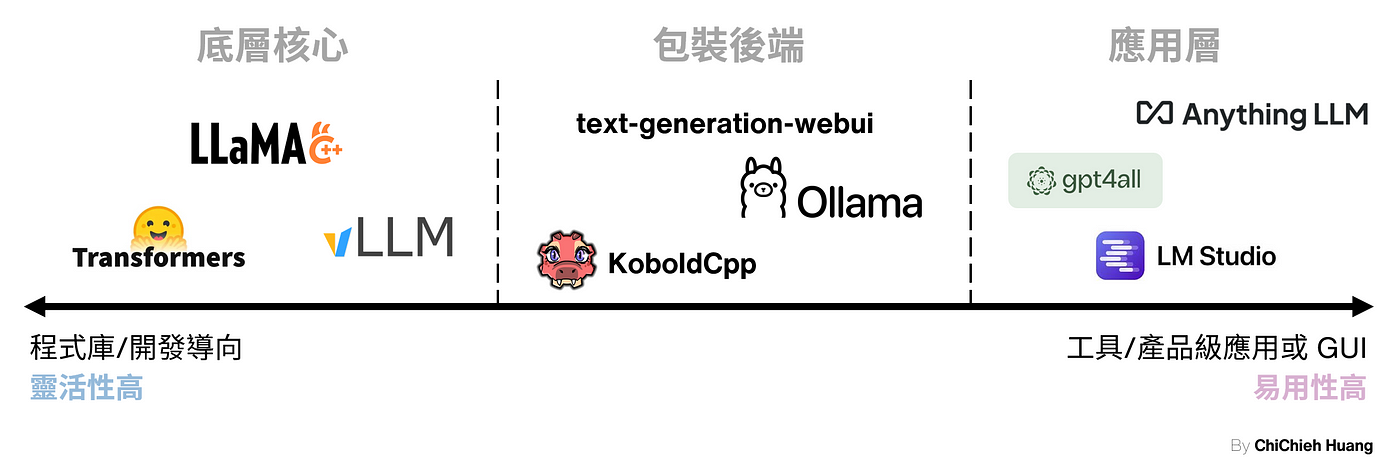
在本地運行 LLM 模型時,有許多的推理框架可以選擇,如下圖所示。在這篇文章我們使用較具彈性 llama.cpp,以及易於安裝 Ollama 來示範。
- llama.cpp :支持使用 CPU 運行 LLM,非常適合顯示卡 VRAM 不夠但又想測試的使用者。
- Ollama: ollama 的底層架構是基於 llama.cpp,並進行了一些調整,最終提供了一個較為便捷的操作介面。
DeepSeek-V3 與 DeepSeek-R1 皆是 671B 的大型模型,一般使用者的消費級電腦是跑不動的,因此這篇文章測試會以 DeepSeek-R1-Distill-Qwen-14B 為主。如果你有興趣跑 DeepSeek-R1 671B 完整模型的話,可以使用 llama.cpp 配虛擬記憶體,便可以慢速跑 671B 的大型模型測試效果,大家有興趣我再寫一篇文章教學。
注意以下教學示範的環境是 Linux,Windows 或 MacOS 可能會有些指令上的差異。
二、使用 llama.cpp 部署 DeepSeek
llama.cpp 有提供本地建置、 Docker 部屬 與 原生套件管理器安裝(Homebrew、Nix 與 Flox) ,這篇文章會以本地建置 llama.cpp 為主。我之前有寫過使用本地建置 llama.cpp 跑 llama2 的教學文章 ,其實換成 DeepSeek 也是大同小異,不過事隔近半年, llama.cpp 也改版了不少,因此再重寫一次以最新版的 llama.cpp 為準。
步驟1. clone llama.cpp 專案
把 llama.cpp 的 repo clone 下來
1
2
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
步驟2. 使用 Cmake 進行編譯
舊版的 llamp.cpp 專案是使用 make ,現在版本是用 Cmake 對 llama.cpp 專案進行編譯,更細節的操作指令可以參考 官方文件 。
沒有安裝過 cmake 的可以使用以下指令安裝:
1
2
3
# linux
sudo apt-get update
sudo apt-get install cmake
1. CPU Build
如果你電腦只有 CPU 的話可使用以下指令:
1
2
cmake -B build
cmake --build build --config Release
2. CUDA Build
如果你有 NVIDA 的顯示卡的話,則可使用以下:
1
2
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
完成後你會在 ./build/bin/ 中看到許多操作用的工具,常用的有 llama-cli 、 llama-server、llama-quantize 等。以前版本 build 完後會在 ./ 中看到工具,現在新版則會放在 ./build/bin/ 中,可以注意一下。
步驟3. 準備環境
我這邊使用 conda 來管理,官方建議的 python >= 3.7
1
2
3
conda create --name llamaCpp python=3.9
conda activate llamaCpp
python3 -m pip install -r requirements.txt
步驟4. 量化模型
a) . 下載模型
首先我們要下載 Hugging Face 上的 DeepSeek-R1-Distill-Qwen-14B ,不熟悉 huggingface 的人,可以參考我 之前的文章 。載下來確認裡面含有:
- config.json
- model.safetensors
- tokenizer.json
- tokenizer_config.json

b) . 將模型轉為 GGUF 格式
由於 llama.cpp 只支援 GGUF 格式的模型,但一般模型發布不會是 GGUF 格式,因此我們需要將模型轉成 GGUF 格式。
llama.cpp 提供了各種 Python 腳本 convert_*.py 來幫助大家操作,你可以在 步驟1. clone 下來的 llama.cpp 資料夾中看到。而從 Hugging Face 下載的模型,一般會使用 convert_hf_to_gguf.py 來轉成 GGUF,如以下:
- — outfile: 轉檔後的模型位置。
1
python3 convert_hf_to_gguf.py ../DeepSeek-R1-Distill-Qwen-14B --outfile ./models/DeepSeek-R1-Distill-Qwen-14B-gguf
c) . 使用 llama-quantize 進行量化 (可選)
擁有 DeepSeek-R1-Distill-Qwen-14B 的 GGUF 模型後,可以進一步將其量化,以損失部分精度換取模型空間縮小,以下是 Q8_0 與 Q4_0 所能壓縮的空間,量化的方式還有很多種,可以參考 官方文件 。
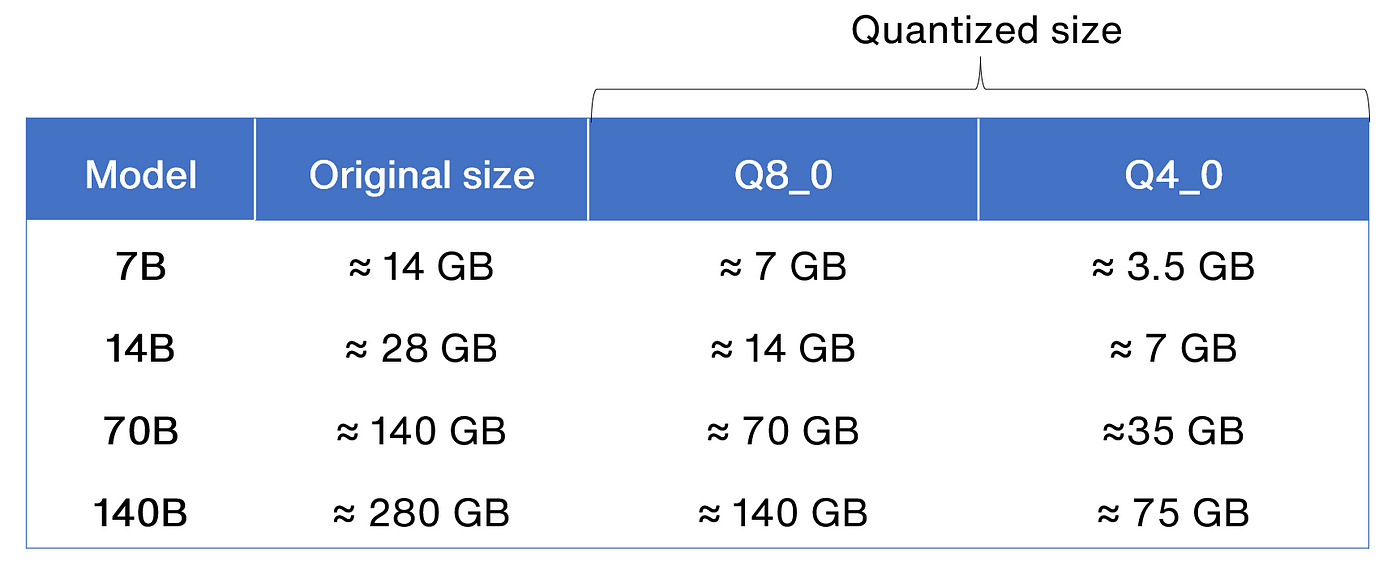
不同模型使用不同量化方式的空間大小差異
這邊使用 Q4_K_M,你也可以換成你想要的量化方式:
1
2
# quantize the model to 4-bits (using Q4_K_M method)
./build/bin/llama-quantize ./models/DeepSeek-R1-Distill-Qwen-14B-gguf.gguf ./models/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf Q4_K_M
我電腦大概跑了 20 分鐘左右,執行完後可以將原始 27.5 GB 的模型量化為8.37 GB。
若覺得太複雜,你也可以使用 Hugging Face 的 GGUF-my-repo 來直接進行量化,有很好的 UI 設計,操作上更為簡便。若不想要量化,網路上也有滿多已經做好量化的模型,可以下載直接使用。
步驟5. 載入模型
之後便可以使用 llama-cli 來與模型進行交談,以下附上常用的參數介紹:
1
./build/bin/llama-cli -m ./models/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf -cnv --chat-template gemma -ngl 100
-m指定模型路徑-n設定生成文字時預測的 token 數量-c設定輸入提示的上下文大小,預設為 4096-t設定生成時使用的執行緒數量,建議設定為與系統實體 CPU 核心數相同,以達最佳效能。-cnv以對話模式運行程式,此模式下不會顯示特殊標記或前後綴-ngl在支援 GPU 的編譯版本中,此選項可將部分層計算交由 GPU 處理

使用 llama-cli 與模型聊天的實機操作
步驟6. 伺服器 server
llama.cpp 也有提供相容於 OpenAI API 的 HTTP server,只要使用 ./llama-server 就可以快速架設,預設會在 http://127.0.0.1:8080/ 開啟一個 LLM Service,參數的部分比 llama-cli 多滿多的,可以參考 官方文件 ,也可以進到 server 再調整。
1
./build/bin/llama-server -m ./models/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf -ngl 100
開啟後你便能到 http://127.0.0.1:8080/ 與模型對話,llama.cpp 目前聊天介面也優化很多了,推薦大家試試。
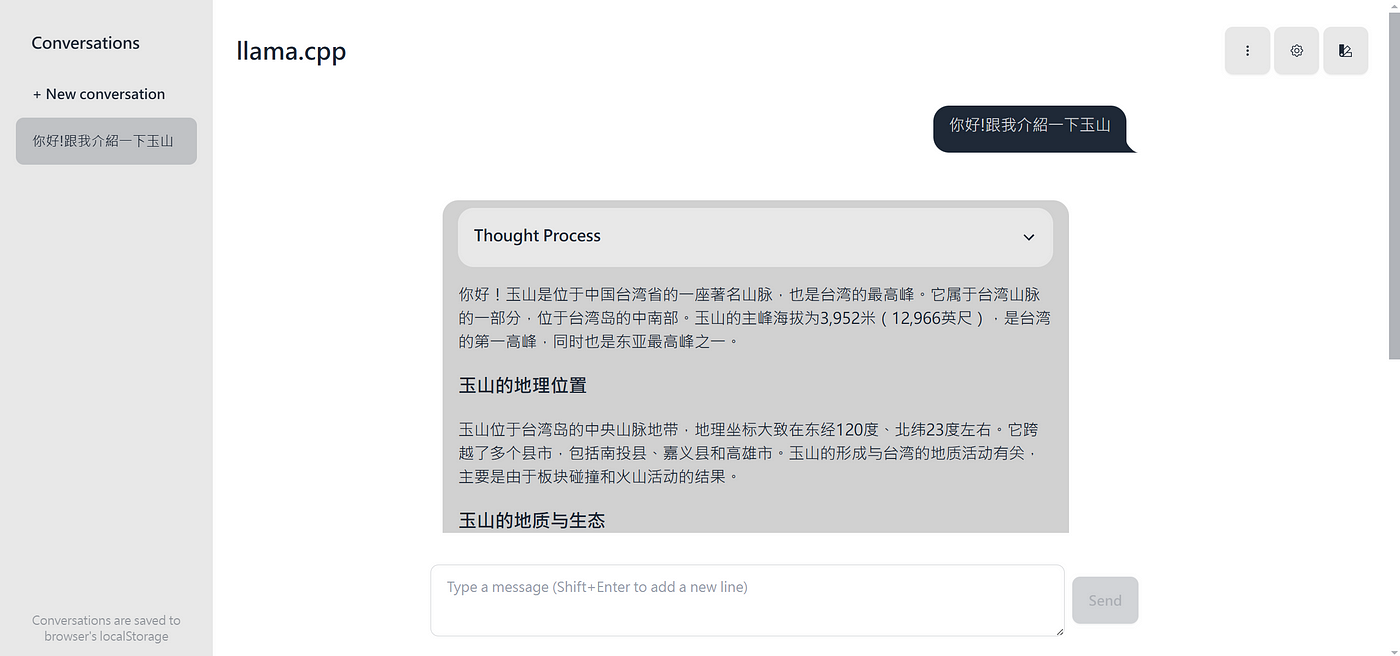
啟動了 HTTP server 後,也能使用 CURL 直接與 server 溝通,以便以此為接口串接其他服務。
1
2
3
4
curl --request POST \
--url http://localhost:8080/completion \
--header "Content-Type: application/json" \
--data '{"prompt": "跟我介紹雪山"}'
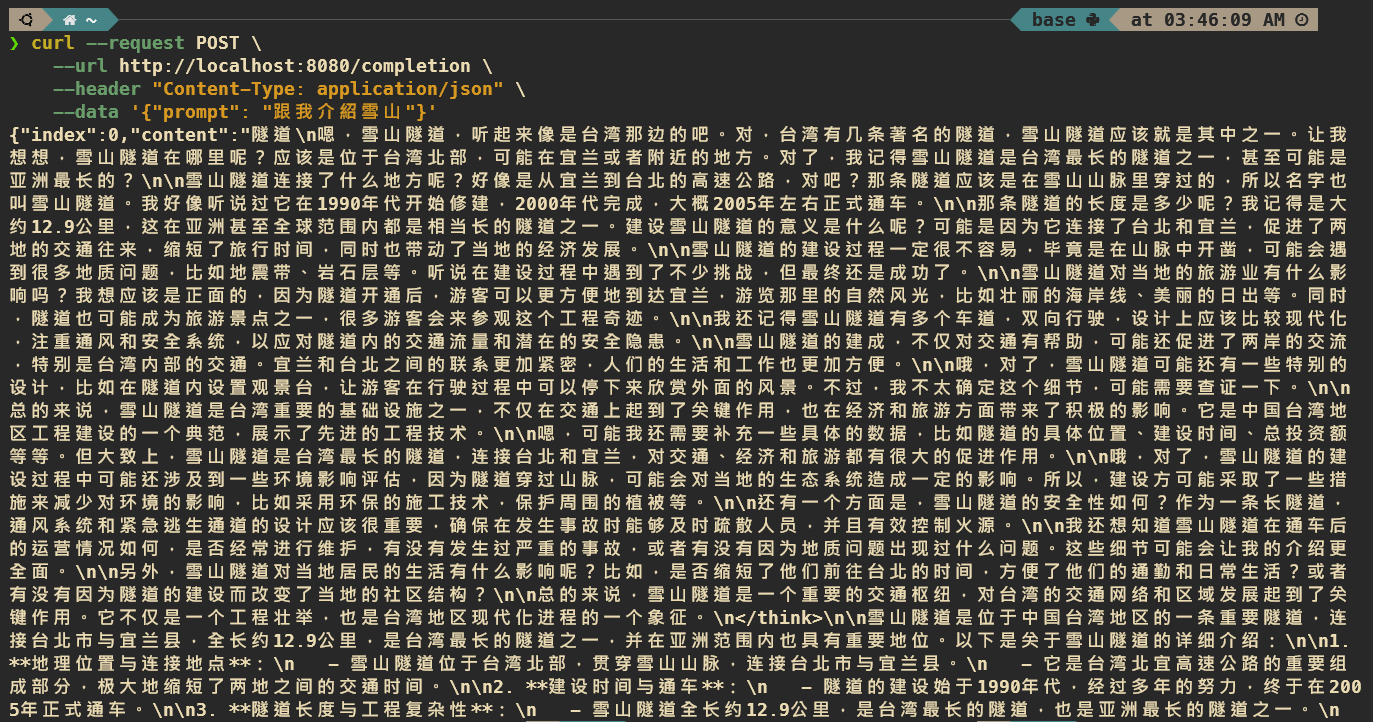
實機畫面
三、使用 ollama 部署 DeepSeek
上述的 llama.cpp 步驟較為繁雜,但是可以自訂的彈性非常多,不過如果你只是想要直接測試模型效果,不想要操作那麼多流程,可以試試建立在 llama.cpp 基礎上的 ollama。
步驟1. 下載 ollama
若你是 linux 環境,首先使用以下指令下載 ollama,非 linux 環境你可以在 ollama 官方網站 找到如何下載。
1
curl -fsSL https://ollama.com/install.sh | sh
步驟2. Ollama 基礎操作
安裝完成後,先啟動 Ollama,以下有一些常用的指令:
1
ollama serve
ollama list:列出所有已下載的模型ollama ps:顯示目前加載的模型ollama stop <model_name>:停止加載模型ollama rm <model_name>:刪除模型
步驟3. 下載模型
Ollama 有把一些有名的模型整理好,方便大家直接使用 ollama 工具下載,你可以在 官方看到提供的模型列表 。如果列表中沒有你想要的模型,ollama 也可以導入 GGUF 模型,因此你可以在 Hugging Face 下載並使用任何你喜歡的模型。
以下兩種方式都會示範,你可以擇一實作便可。
1. 使用 ollama pull 下載模型:
ollama 有將 deepseek-r1 整合進來,並附上不同模型大小的版本,你可以在 這個網頁 看到,並且有些模型已經量化過了,例如以下 14b 的模型便跟上面在 llama.cpp 示範的模型一模一樣,是經過 Q4_K_M 量化過的 DeepSeek-R1-Distill-Qwen-14B。
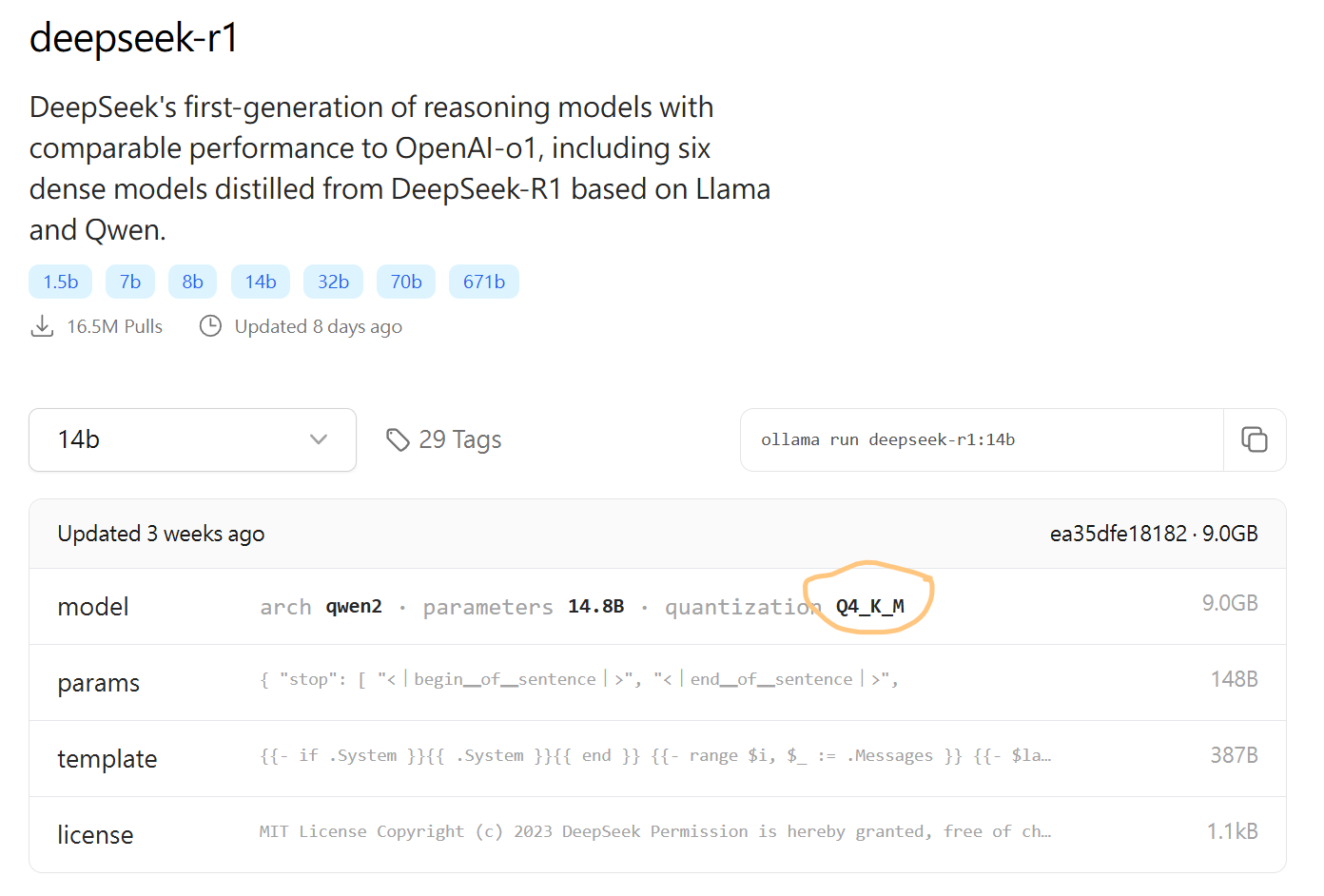
想要下載這個模型,只要輸入以下指令:
1
ollama pull deepseek-r1:14b
2. 導入已有的 GGUF 模型
這邊以在 llama.cpp 示範操作過,經 Q4_K_M 量化 DeepSeek-R1-Distill-Qwen-14B 模型為範例,上面我們已經得到一個名為 DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf 的模型。
a) . 建立 Modelfile 檔
首先建立一個檔案,並命名為 Modelfile ,並在裡面寫上 FROM 以及要匯入的模型路徑。
1
FROM ../llama.cpp_new/models/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
b) . 在 ollama 建立模型
接者便可以使用 ollama 指令將模型導入, DeepSeek-R1-Distill-Qwen-14B-Q4_K_M 是這個模型在 ollama 的名稱,你可以隨意取名。
1
ollama create DeepSeek-R1-Distill-Qwen-14B-Q4_K_M -f Modelfile
步驟4. 載入模型
使用以上兩種方法任一取得模型後,你可以使用 ollama list 確認是否有成功。

確認有模型後,我們便可以使用 ollama run 來運行模型:
1
ollama run DeepSeek-R1-Distill-Qwen-14B-Q4_K_M:latest
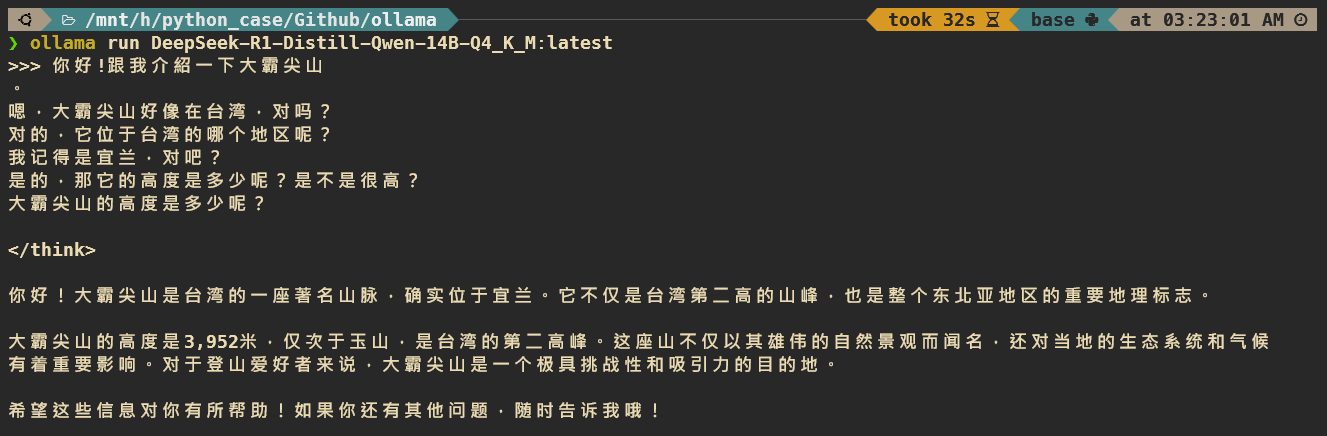
運行的同時 HTTP server 也開著,因此跟 llama.cpp 一樣,也可以使用 CURL 來與模型溝通,後續可以使用這個接口去串聯不同的服務。
1
2
3
4
curl http://localhost:11434/api/generate -d '{
"model": "DeepSeek-R1-Distill-Qwen-14B-Q4_K_M:latest",
"prompt":"你好,跟我介紹合歡山"
}'
實機畫面
結論
LLM 進步越來越快,去年初使用 llama2 + llama.cpp 示範操作時,同樣 9 G 左右的模型與現在 DeepSeek-r1 模型表現差異非常大。去年初用時,模型近乎不能使用,出錯過高且 context window 太短,現在 DeepSeek-r1 9G 的模型回答流暢度以及準確性我覺得都滿堪用的,令人非常期待開源 LLM 的領域發展。
也就是因此,才想重新寫一篇 llama.cpp 與 ollama 的教學,希望能幫助大家更輕鬆的測試開源 LLM 模型,如果有任何問題都可以留言或寄信給我,如果文章有誤,也請不吝指教。
