深入探討 Reasoning models 與 Test-Time Compute | DeepSeek-R1 的建構
推理模型 (Reasoning models) 正迅速崛起,如 OpenAI-o1、DeepSeek-R1。本文將以淺顯易懂的語言,探討什麼是 Test-Time Compute 以及其與 Reasoning models 的關係,並以 DeepSeek-R1 為例。
深入探討 Reasoning models 與 Test-Time Compute | DeepSeek-R1 的建構
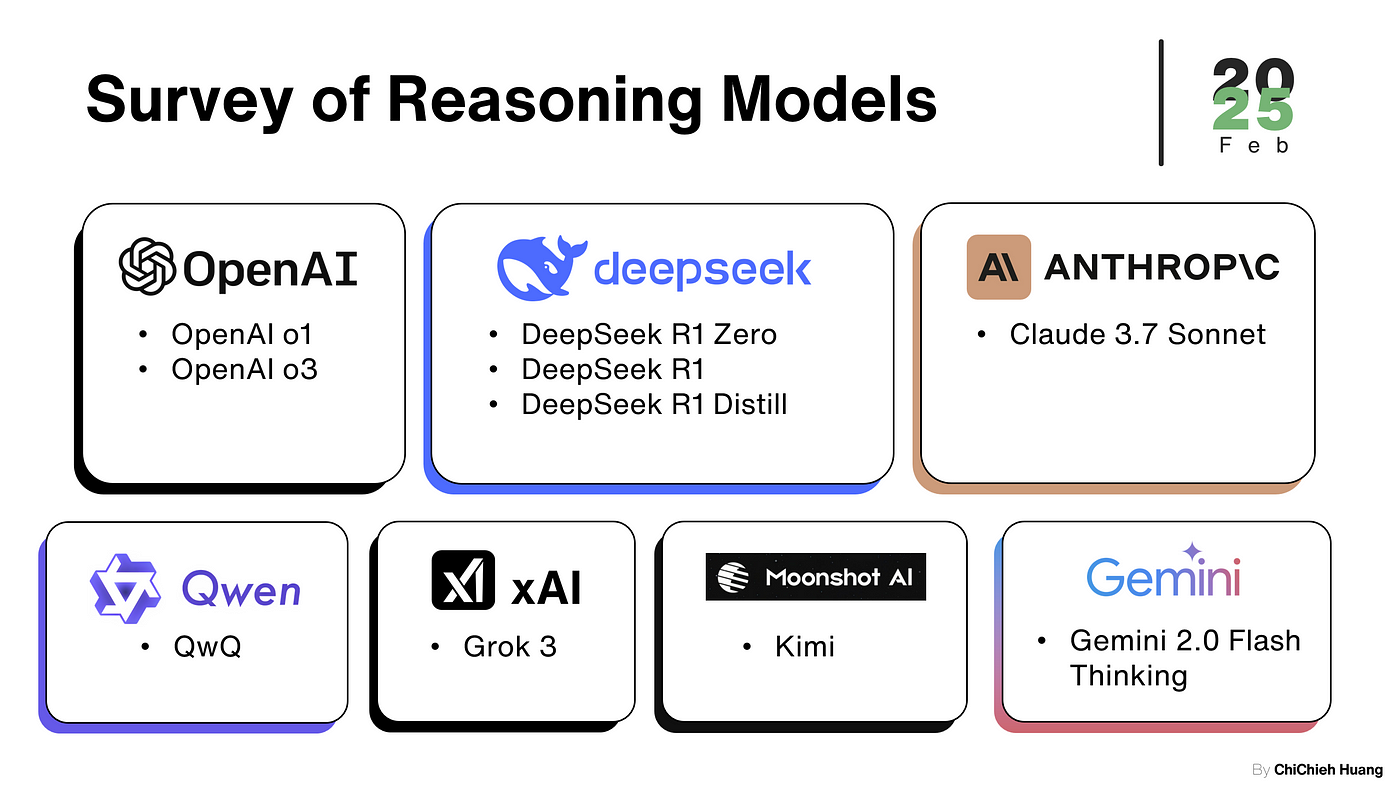
目前已知的推理模型 (Reasoning models),調查範圍至2025 年 2 月 28 號
最近,一種全新類型的 LLM 正在迅速崛起 — — 推理模型 (Reasoning models),如 OpenAI-o1、DeepSeek-R1 與 Alibaba QwQ 等。在這種 Reasoning models 出來之前,許多 AI 研究人員以及使用這些技術的人都更傾向於讓模型「立刻」產生輸出。然而,OpenAI 推出的 o1 模型所引入的「慢思考」 理念,徹底改變了這一切,o1 在程式測驗競賽的表現突出 (第 89 位),也在 US math olympiad qualifier 排進前 500 名,甚至在物理、生物與化學等多項 benchmark 中,達到了超越博士級別的準確率。
自從這一突破出現之後,我們清楚地看到,當模型並不「匆忙」而是有時間「思考」逐步推理時 ,模型的推理能力有多麼強大。而這些都與一個很有意思的主題息息相關:Test-Time Compute。
因此,本文將以淺顯易懂的語言,探討什麼是 Test-Time Compute 以及其與 Reasoning models 的關係。我們會先從 Reasoning models 的起源與演進說起,並探討什麼是 Test-Time Compute;在了解這一切基礎後,我們會以 DeepSeek-R1 為例,探究其是如何應用 Test-Time Compute;緊接著討論 Test-time Compute 的效果與限制;最後則是展望這塊領域未來的發展發向。
什麼是 Reasoning models ?
Reasoning models 是一種新的 LM 分類,這種模型的特色在於將複雜的問題分解為更小、更易於管理的步驟,並透過明確的邏輯推理來解決,也成被稱為 Reasoning Language Models (RLMs) 或 Large Reasoning Models (LRMs) ( Besta et al. ,2025 )。
RLMs 與 一般 LM 的差異可以用 Kahneman 的暢銷書籍《快思慢想》(Thinking, Fast and Slow) 中的概念作比喻。書籍中提到人類有兩種認知模式系統:
- 系統 1 思維 (System-1 thinking):更快、更直覺
- 系統 2 思維 (System-2 thinking):相對更為緩慢、深思熟慮且邏輯性強
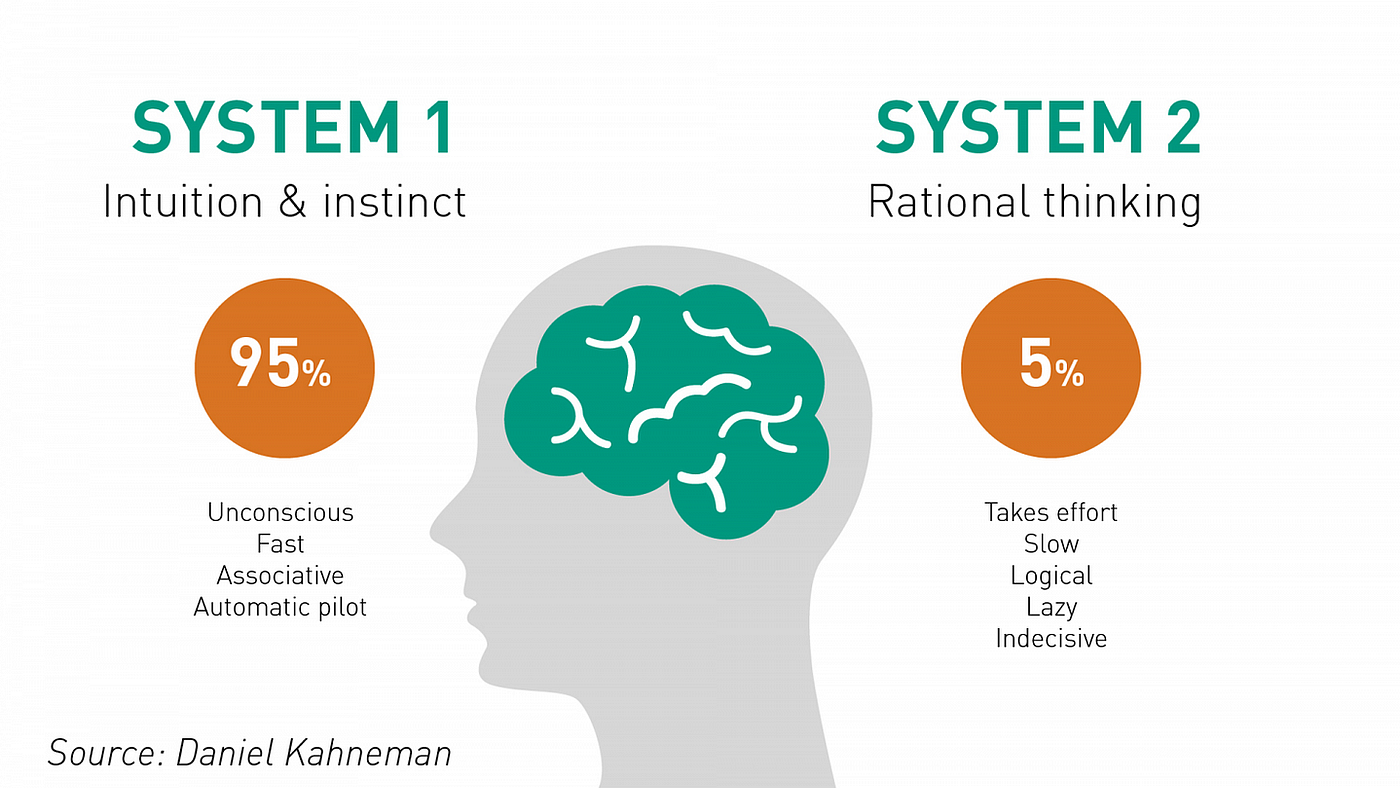
人類的兩種認知模式:System 1 thinking & System 2 thinking
System 1 任務,一般的 LM 就能透過一些技巧輕鬆解決,世界各地每天使用 ChatGPT 的許多學童都可以證明這一點;然而 System 2 任務,如大學數學題,對 LM 來說就沒那麼簡單,為了解決數學應用題,模型需要將問題分解為多個推理步驟,而這就是我們 RLMs 所在做的事。
Reasoning models 起源
在 LLM 展現出優異的 System 1 任務能力後,研究者開始探索其在 System 2 任務上的瓶頸與改進方法。其中, Wei et al. (2022) 所提出的 Chain-of-Thought (CoT) 實驗成為一大突破,該研究發現,僅需在 Prompt 中加入簡單的指令,例如「讓我們一步步思考 (Let’s think step by step)」,即可促使 LLM 進行推理步驟,大幅提升其推理能力。隨後, Kojima et al. (2022) 進一步驗證了這一現象,並推動了一系列相關研究的發展,如 ToT (Tree of Thoughts) 等更複雜的推理框架。
表面上,o1 所展現的「多思考」似乎與現有的 CoT 技術相似,但二者有著關鍵差異。CoT 這類技術鼓勵模型將推理過程和思路闡述出來,但推理過程的中間步驟並未經過驗證,或與其他可能性進行權重比較。因此,即使大部分步驟正確,若其中某一步出錯,也容易會導致最終答案錯誤。也就是說,這些方法僅是 Prompt 的層面讓 LLM 展現這個能力,並未真正讓模型本身學到推理的能力,換句話說,LLM 仍無法真正「內化」這種推理流程。
Reasoning models 演進
目前建立 RLM 的技術基礎仍然 不透明且複雜 ,同時也仍不清楚 OpenAI o1 的創新是否來自於模型本身,或還是仰賴外部系統。雖然 OpenAI o1 的技術還披著一層面紗,但不可否認的是它帶動了 RLM 演進,而這一切的發展都離不開以下三個關鍵的技術進步:
- 基於 RL 的模型設計,如 AlphaZero
- 基於 LLM 和 Transformer 的模型進步,例如 GPT-4o
- 超級電腦、高效能運算 (HPC) 能力的不斷增長
{:target="_blank"} 探討 RLM 的歷史與演進的三大要素](/assets/73c870be4b10/1*nhRPBDxaFX-6nVd5DzV5og.png)
Besta et al. (2025) 探討 RLM 的歷史與演進的三大要素
有鑑於 OpenAI o1 的成功,有一系列研究試圖探討重現 OpenAI o1 的思考系統。如 Besta et al. (2025) 與 Wang et al. (2024) 皆提到,RLM 的設計可能結合了多種技術,如蒙地卡羅樹搜尋 (Monte Carlo Tree Search, MCTS) 或 Beam Search 這樣的搜索算法來提升決策品質,並利用強化學習 (Reinforcement Learning, RL) 進行調整。此外,Process-Based Supervision (PBS)、上述提到的 CoT 與 ToT,甚至檢索增強生成 (Retrieval-Augmented Generation, RAG) 也被認為是其核心機制之一。
而在開源領域 OpenR (Wang et al., 2024) 、 Rest-MCTS (Zhang et al., 2024) 、 Journey Learning (Qin et al., 2024) 、 LLaMA-Berry (Zhang et al., 2024) 也做了諸多嘗試,如以下是 Journey Learning 的研究歷程。
{:target="_blank"} ) 探索 OpenAI o1 技術的研究歷程,發佈於 2024 年 10 月 8 日](/assets/73c870be4b10/0*cPHzQAg2b1po86PY.png)
Qin et al. (2024 ) 探索 OpenAI o1 技術的研究歷程,發佈於 2024 年 10 月 8 日
Reasoning models 與 DeepSeek-R1
然而,以上這些方法均未能達到與 OpenAI o1 相當的推理效能。直到 DeepSeek-R1 的出現才打破了這個僵局,根據 DeepSeek 在其論文中所述 ( DeepSeek-AI et al., 2025 ),他們的理念明確地承襲 OpenAI o1 提倡的核心 — — 深度、逐步的推理過程在解決複雜任務時至關重要。而驅動他們的動力是:如何讓模型在推理階段更深入的「思考」,因此他們著手研究對 Test-Time Compute 的擴展。
其實回頭來看,OpenAI o1 在其技術報告 ( OpenAI, 2024 ) 便首次引入了通過延長推理過程來進行 Test-Time Compute 的擴展,且該報告與 DeepMind 的研究 ( Snell et al., 2024 ) 皆顯示,傳統應用於訓練階段的 Scaling Law 也同樣適用於推理階段。這一點不僅在數學、物理與化學等 benchmark 上得到驗證,也使得模型在實際應用中更接近人類專家的思考模式。
{:target="_blank"} )](/assets/73c870be4b10/1*veenUtAeZ6DFTKYFe4DNUA.png)
o1 效能隨著 Train-Time compute 和 Test-Time Compute 而平穩提升 ( OpenAI, 2024 )
DeepSeek 在模型架構與訓練方法上有自己的設計特色,其特別強調 RL 以及Test-Time Compute 的擴展。因此接下來我們隨著 DeepSeek 的步伐,來一步一步探討他們是如何搭建 RLM,但在這之前,我們得先來了解什麼是 Test-Time Compute。
什麼是 Test-Time Compute ?
Test-Time Compute 是指的是模型在推理階段所使用的計算量 — — 也就是模型在訓練完成後,為產生答案所投入的資源與時間。從根本上來講,Test-Time Compute 代表了在人工智慧系統中 分配計算資源方式的轉變 。
在 2024 年上半年之前,為了提升 LLM 的效能,開發者通常會增加以下三個面向的規模來提升性能,這也就是以前常說的 Train-Time compute。儘管這種模式已被證明非常有效,但隨著 pre-training 的模型越來越大,其所需的資源變得越來越昂貴,甚至已經出現需要花費數十億美元狀況。
- 模型參數 (parameters)
- 資料集 (tokens)
- 計算量 (FLOPs)
而就剛上文提到的,Train-Time compute 的 Scaling Law 也同樣適用於 Test-Time Compute,這種規律早在 Jones (2021) 對棋盤遊戲研究就發現,Train-Time compute 的增加大致與 Test-Time Compute 的減少呈線性關係,且減少的倍數相同。
{:target="_blank"} )](/assets/73c870be4b10/1*2SIIlNycBVcAkBk_bazA-w.png)
不同基準下 Train-Time compute 與 Test-Time Compute 的關係 ( Jones, 2021 )
這個新的規律發現,讓開發者重新思考計算資源的分配,不再只關注於 pre-training 過程,而更注重推理階段的運用。在 Test-Time Compute 投入更多的資源,意味著 LLM 能進行更深層的推理與「思考」,這對打造能自行優化、自主處理開放式高強度推理與決策任務的代理 (agent) 來說至關重要。
DeepSeek-R1 如何應用 Test-Time Compute ?
2025 年 1 月 20 日 DeepSeek 推出三種不同的模型 DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill,從這 三種模型的演進 ,我們可以清楚的看到 DeepSeek 是如何建構 RLM。
以下是三種模型的簡介 ,由下圖可以很清楚看到整個流程是如何變化:
- DeepSeek-R1-Zero :純 RL 模型。
- DeepSeek-R1 :先使用少量多步驟推理的範例進行微調,再應用 RL。
- 蒸餾 (Distillation) :將DeepSeek-R1 的推理能力傳遞到較小規模的AI 模型中,讓它們也具備強大的推理表現。
{:target="_blank"} )](/assets/73c870be4b10/0*LsCseumS39nkwxV-.png)
DeepSeek R1 技術報告中三種不同模型的開發過程 ( Raschka, 2025 )
1. DeepSeek-R1-Zero: 從零開始的純 RL 模型
- 這個階段的模型完全依靠 RL 來學習推理技巧,沒有任何初始的監督式數據。它透過自身行為 (模型的回答) 獲得獎勵或懲罰,並透過持續試錯來掌握多步驟推理。
- 在推論時,DeepSeek-R1-Zero 會透過回顧先前的思路不斷自我演進,隨著推理步驟的增加而具備更深層的「反思」能力,如下圖所示,模型從最初的數百個推理 tokens 增加到數千數萬個,這一行為被稱為「自進化(self-evolution)」。而這些額外的推論 tokens 就意味著更多的運算量,也即所謂的 Test-Time Compute。
- 雖然 DeepSeek-R1-Zero 在數學與邏輯推理任務上取得了顯著效果,但因為沒有任何監督微調,仍存在輸出易 語言混雜、格式雜亂 等問題。
- 註:這邊 RL 採用的演算法為 Group Relative Policy Optimization (GRPO),這是對 PPO (Proximal Policy Optimization) 的改進。GRPO 的特點是無需額外的價值函數模型,而是透過在一個組內比較動作並使用平均獎勵作為基線,從而降低訓練成本並提升表現。有興趣可以看 DeepSeek-AI et al. (2025) 的技術報告。
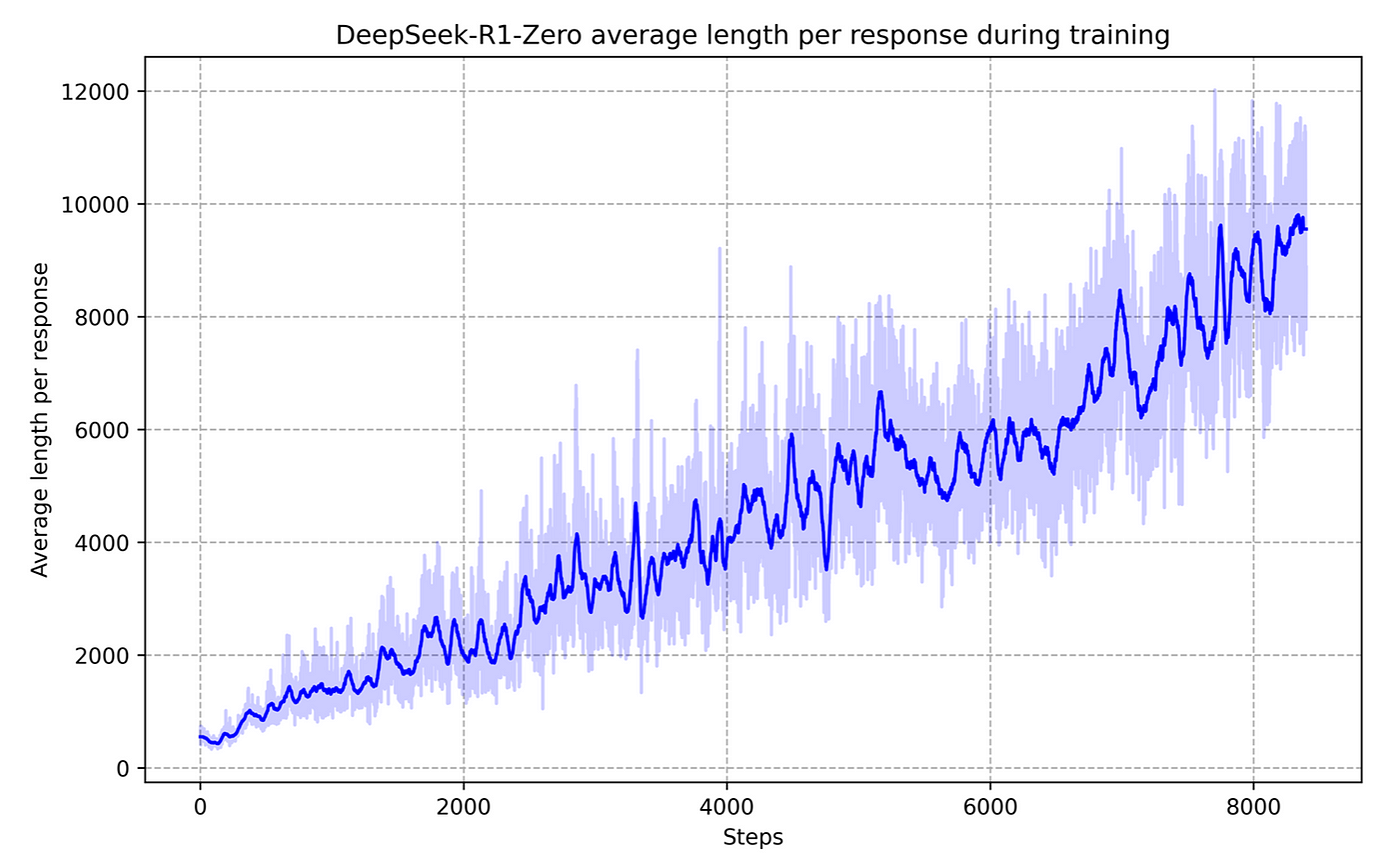
DeepSeek-R1-Zero 的思考時間隨著 RL 訓練過程越長而持續提升
2. DeepSeek-R1:多階段優化管線,進一步強化推理
由於 DeepSeek-R1-Zero 的輸出容易混雜語言且格式雜亂,因此 DeepSeek 在後續版本中引入了以下調整:
- 冷啟動微調 (Cold Start Fine-Tuning) :首先利用少量高品質的 CoT 範例和可讀性高的數據來讓模型「暖身」。這一步讓模型在推理時可更快進入深度推理,而不會像從零開始一樣容易發散或失控,並為後續的多步推理奠定了基礎。
- 面向推理的強化學習 (Reasoning-Oriented RL) :接著針對數學、程式碼等需要多步推理的領域進行 RL 訓練,同時引入「語言一致性獎勵」,懲罰混雜語言、鼓勵可讀性更高的人類可理解輸出。在推理時,因為模型能夠在遇到複雜問題時花更多時間做多輪思考和檢查,便自然需要更多 Test-Time Compute。
- 拒絕採樣 + 監督微調 (Rejection Sampling + SFT) :在模型經過一輪 RL 並收斂後,使用其生成的大量數據進行拒絕採樣,保留優質樣本來微調模型,擴展到其他應用領域。這一步也讓模型在推理階段對不同任務都能調整思考步驟。
- 第二階段 RL (Second RL Phase) :在完成上述微調後,再進一步用 RL 進行對齊與性能提升,使模型對於使用者指令更友好、推理更精準。
3. 蒸餾 ( Distillation) :將龐大模型的推理能力傳遞給更小模型
由於 DeepSeek-R1 擁有 671B 參數,運行成本與硬體門檻十分高。為了讓更多人能使用其強大的推理能力,研究人員也將 DeepSeek-R1 作為「教師模型」,對更小規模的「學生模型」進行 Distillation。
- 蒸餾訓練資料:80 萬高品質樣本
- 研究團隊收集了總數約 80 萬條高品質示例 (其中 60 萬個包含 Chain-of-Thought 推理步驟,另外 20 萬則是一般問答)。
- 學生模型與教師模型在面對相同提示時,教師先輸出一組機率分佈,學生則學習去模擬、逼近該分佈。
2. 學生模型學到的,不僅是輸出內容,還有「思路」
- 透過比較自己的輸出與教師模型輸出的機率分佈差異,學生模型漸漸掌握 DeepSeek-R1 所展示的推理模式。
- 這讓最終蒸餾出來的 Qwen-32B 等小模型,能在各種推理任務中展現高準確率,同時可在消費級硬體上運行,大幅降低了部署門檻。
總結來說,從 DeepSeek-R1-Zero 的驗證性研究開始,到 DeepSeek-R1 在推理階段充分運用多步思考,再到將大型模型的推理思維「蒸餾」給更小規模模型,這一系列工作都圍繞著一個核心理念 — — 在推理階段進行更深、更靈活的思考,即 Test-Time Compute 。這些額外的推理步驟與運算資源,使得 DeepSeek-R1 能在面對複雜問題時展現出強大的解題能力與高品質輸出,同時也能透過蒸餾技術擴散其成果,讓更多開發者與用戶也能享受到高階推理技術。
在這個過程中,Test-Time Compute 不僅是單純延長推理 tokens,而是讓模型在推理階段有更多時間與資源進行反覆檢查、反思和優化其解題過程。這使得模型能夠在不同階段動態調整策略,充分發揮其潛在的推理能力,進而能在多個 benchmark 上取得優異成績。
DeepSeek 失敗的嘗試
然而,DeepSeek 在追求更深層次的 Test-Time Compute 旅程上也並非一帆風順。還記得在上面「Reasoning models 演進」的篇幅中,我們提到 RLM 的設計可能結合了多種技術,如蒙地卡羅樹搜尋 (MCTS)、Beam Search、RL 與 PRM 等,這些技術大部分也是 Test-Time Compute 應用的一環。而在 DeepSeek 的早期的研究階段,也嘗試使用過這些技術來訓練模型的推理能力,以下是在論文提到的兩個不成功的嘗試:
- Process Reward Model (PRM) :理論上能夠逐步評估每個推理過程的正確性,從而找到更好的解決方案,但他們發現難以對推理過程中每個細微步驟進行精確評估,因為一般推理問題中的中間步驟往往缺乏明確的標準,且容易導致模型依賴而出現 Reward hacking 現象。此外,這種方法在實際應用中需要大量人工標註,無法有效擴展。
- MCTS: 雖然該方法在棋類遊戲中取得了成功,但 LLM 的 token 生成的解空間呈指數級擴張,即使設置了節點延伸的最大限制,模型仍容易陷入局部最優解。因此,儘管 MCTS 在某些情境下能夠改善推理時的探索效率,但在實際大規模的 RL 訓練中,效果並不穩定。
根據 DeepSeek 學到的經驗我們可知,這些複雜的 Test-Time Compute 方法雖然在理論上充滿吸引力,但在實際應用中,往往會因計算資源巨大、過於複雜,或不易收斂等因素而未能達到預期效果。也正是因為如此,DeepSeek-R1 的構建並未採用上述方法,而是選擇了更直接的方式訓練模型的推理能力。
註:DeepSeek 還有許多創新技術,這邊便不贅述。
Test-time Compute 在小模型的效果
在前文中,我們已經看到 DeepSeek-R1 能夠通過蒸餾技術,將一個 671B 的大模型的推理技術交給更小的模型,而除了蒸餾技術外,也有許多研究證明,在數學與程式的 benchmark 中,單純擴展的 Test-time Compute,便能使小模型擁有打敗大模型的能力,如 Beeching et al. (2024) 在 HF 上的文章便提到,Llama-3.2 3B 在經過 256 次迭代後,其表現竟可以超越了參數量超過 20 倍的 Llama-3.1 70B 模型;DeepMind 的研究 ( Snell et al., 2024 ) 也指出PaLM 2-S small 模型在推理時加入額外算力,其表現可以超過參數量大 14 倍的模型; Brown et al. (2024) 採用 Repeated Sampling 策略,讓模型對同一問題產生多個答案再挑選最佳,結果顯示一個中型模型單次推理只能解出 15.9% 的問題,但允許其嘗試 250 次後,解題率飆升至 56%,超越了當時單次推理的最高分數 43%。
{:target="_blank"} 小模型 Llama-3.2 1B 與 3B 在不同迭代次數下對比 Llama-3.1 70B 的表現](/assets/73c870be4b10/1*R22Ymhk78o0Dxc2plwCDdQ.png)
Beeching et al. (2024) 小模型 Llama-3.2 1B 與 3B 在不同迭代次數下對比 Llama-3.1 70B 的表現
以上研究皆顯示,擴展 Test-time Compute 讓小模型擁有更多「思考」,可以有效地激發小模型的潛力,甚至讓其在某些領域超越大模型。那麼這樣的效果讓我們不禁開始思考:這是否意味著,為了獲得更優的模型,我們應始終讓模型「思考」更多,而不是用更大規模、更多數據去 pre-training 模型呢?
Test-time Compute 的限制
我認為現階段是 互補而非完全替代 ,雖然擴展 Test-time Compute 顯著提升了小模型的表現,但研究指出它無法完全取代大規模 pre-training。 Snell et al. (2024) 發現到,對於極具挑戰性的難題,小模型即使用大量推理步驟改進答案,效果仍非常有限;此時只有增加模型參數,並投入更多 Train-Time compute 才能帶來明顯提升。換而言之, Test-time Compute 的前提是模型對任務有「非零的起點」 — — 若模型對某類問題毫無頭緒,再多的推理嘗試也難以產生正確結果。
Brown et al. (2024) 也觀察到,當任務形式並不能自動驗證時(如非數學與程式任務),多數投票這種選擇策略的效能,會在超過數百次重複後產生停滯,無法隨著更多 Test-time Compute 而持續提高。這些結果凸顯了 Train-Time compute 與 Test-time Compute 各有其不可替代的作用 — — Train-Time compute 塑造了模型的基礎知識與能力,而 Test-time Compute 則在此基礎上進行延伸和強化。
未來方向
2024 至今年,RLM 開始一個接一個出現,因此顯而易見,今後還會出現大量 RLM 以及與擴展 Test-time Compute 有關的新研究,根據現在的論文與研究,我整理了幾個未來可能發展的方向:
- 混合式訓練與 RLM 普及 :由上文我們可以看出,Test-time Compute 可以讓模型的能力在原有的基礎上更上一層樓,因此未來有望看到更多將 Train-Time compute 與 Test-time Compute 結合的混合策略,在資源有限的情況下最大程度的提升模型表現,並且 RLM 也會成為 LLM 的趨勢之一。
- 動態調整推理計算: 畢竟並非所有問題都需要千字長的推理;簡單問題只需較短的思考,而複雜問題才需更深度的計算。有研究在嘗試讓模型學會決定應該啟用多少推理步驟,也就是讓模型先判斷題目難度,再選擇是否需要深度「思考」,避免資源浪費。有鑒於此,未來 RLM 的 API 可能會提供「推理預算」參數,或模型會根據難度動態調整推理步數,確保使用者只在必要時付出較高的運算費用。
- 兼顧「快思」與「慢想」 :乍看與上面那一點有點像,不過這邊探討的是普通 LLM 與 RLM 的整合,未來應可建立兩階層模型系統的思路:能快速回答簡單查詢的LLM,以及面對困難問題時才啟用深度推理的 RLM。
- 推理階段的「訓練」與自我提升 :更前瞻的研究試圖模糊 Train-Time compute 與 Test-time Compute 的界線,探討 Test-Time Training ,即模型在推理階段可以繼續針對該問題做小幅度的即時微調。也就是說,模型在部署之後權重仍有機會根據當下題目的特殊需求改變,類似考試時先臨時背誦資料再回答。不過目前這個領域尚不成熟。
參考文獻
Beeching, Edward, and Tunstall, Lewis, and Rush, Sasha, “Scaling test-time compute with open models.”, 2024.
Brown, B., Juravsky, J., Ehrlich, R., Clark, R., Le, Q.V., R’e, C., & Mirhoseini, A. (2024) . Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. ArXiv, abs/2407.21787 .
Besta, M., Barth, J., Schreiber, E., Kubíček, A., Catarino, A.C., Gerstenberger, R., Nyczyk, P., Iff, P., Li, Y., Houliston, S., Sternal, T., Copik, M., Kwa’sniewski, G., Muller, J., Flis, L., Eberhard, H., Niewiadomski, H., & Hoefler, T. (2025) . Reasoning Language Models: A Blueprint.
DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z.F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., Hao, G., Chen, G., Li, G., Zhang, H., Bao, H., Xu, H., Wang, H., Ding, H., Xin, H., Gao, H., Qu, H., Li, H., Guo, J., Li, J., Wang, J., Chen, J., Yuan, J., Qiu, J., Li, J., Cai, J., Ni, J., Liang, J., Chen, J., Dong, K., Hu, K., Gao, K., Guan, K., Huang, K., Yu, K., Wang, L., Zhang, L., Zhao, L., Wang, L., Zhang, L., Xu, L., Xia, L., Zhang, M., Zhang, M., Tang, M., Li, M., Wang, M., Li, M., Tian, N., Huang, P., Zhang, P., Wang, Q., Chen, Q., Du, Q., Ge, R., Zhang, R., Pan, R., Wang, R., Chen, R.J., Jin, R.L., Chen, R., Lu, S., Zhou, S., Chen, S., Ye, S., Wang, S., Yu, S., Zhou, S., Pan, S., Li, S.S., Zhou, S., Wu, S., Yun, T., Pei, T., Sun, T., Wang, T., Zeng, W., Zhao, W., Liu, W., Liang, W., Gao, W., Yu, W., Zhang, W., Xiao, W.L., An, W., Liu, X., Wang, X., Chen, X., Nie, X., Cheng, X., Liu, X., Xie, X., Liu, X., Yang, X., Li, X., Su, X., Lin, X., Li, X.Q., Jin, X., Shen, X., Chen, X., Sun, X., Wang, X., Song, X., Zhou, X., Wang, X., Shan, X., Li, Y.K., Wang, Y.Q., Wei, Y.X., Zhang, Y., Xu, Y., Li, Y., Zhao, Y., Sun, Y., Wang, Y., Yu, Y., Zhang, Y., Shi, Y., Xiong, Y., He, Y., Piao, Y., Wang, Y., Tan, Y., Ma, Y., Liu, Y., Guo, Y., Ou, Y., Wang, Y., Gong, Y., Zou, Y., He, Y., Xiong, Y., Luo, Y., You, Y., Liu, Y., Zhou, Y., Zhu, Y.X., Huang, Y., Li, Y., Zheng, Y., Zhu, Y., Ma, Y., Tang, Y., Zha, Y., Yan, Y., Ren, Z., Ren, Z., Sha, Z., Fu, Z., Xu, Z., Xie, Z., Zhang, Z., Hao, Z., Ma, Z., Yan, Z., Wu, Z., Gu, Z., Zhu, Z., Liu, Z., Li, Z., Xie, Z., Song, Z., Pan, Z., Huang, Z., Xu, Z., Zhang, Z., & Zhang, Z. (2025) . DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. ArXiv, abs/2501.12948 .
Jones, A. (2021) . Scaling Scaling Laws with Board Games. ArXiv, abs/2104.03113 .
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., & Iwasawa, Y. (2022) . Large Language Models are Zero-Shot Reasoners. ArXiv, abs/2205.11916 .
OpenAI. (2024) . Learning to reason with llms . https://openai.com/index/learning-to-reason-with-llms/
Plaat, A., Wong, A., Verberne, S., Broekens, J., Stein, N.V., & Back, T.H. (2024) . Reasoning with Large Language Models, a Survey. ArXiv, abs/2407.11511 .
Qin, Y., Li, X., Zou, H., Liu, Y., Xia, S., Huang, Z., Ye, Y., Yuan, W., Liu, H., Li, Y., & Liu, P. (2024) . O1 Replication Journey: A Strategic Progress Report — Part 1. ArXiv, abs/2410.18982 .
Raschka, S. (2025) . Understanding reasoning in LLMs . Sebastian Raschka’s Newsletter. https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
Snell, C., Lee, J., Xu, K., & Kumar, A. (2024) . Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. ArXiv, abs/2408.03314 .
Se, K., & Vert, A. (2025, February 6) . What is test-time compute and how to scale it? [Community Article] . Retrieved from https://huggingface.co/blog/Kseniase/testtimecompute
Wang, B., Min, S., Deng, X., Shen, J., Wu, Y., Zettlemoyer, L., & Sun, H. (2022) . Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters. Annual Meeting of the Association for Computational Linguistics .
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E.H., Xia, F., Le, Q., & Zhou, D. (2022) . Chain of Thought Prompting Elicits Reasoning in Large Language Models. ArXiv, abs/2201.11903 .
Wang, J., Fang, M., Wan, Z., Wen, M., Zhu, J., Liu, A., Gong, Z., Song, Y., Chen, L., Ni, L.M., Yang, L., Wen, Y., & Zhang, W. (2024) . OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models. ArXiv, abs/2410.09671 .
Wang, J. (2025) . A Tutorial on LLM Reasoning: Relevant Methods behind ChatGPT o1.
Zhang, D., Zhoubian, S., Yue, Y., Dong, Y., & Tang, J. (2024) . ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search. ArXiv, abs/2406.03816 .
Zhang, D., Wu, J., Lei, J., Che, T., Li, J., Xie, T., Huang, X., Zhang, S., Pavone, M., Li, Y., Ouyang, W., & Zhou, D. (2024) . LLaMA-Berry: Pairwise Optimization for O1-like Olympiad-Level Mathematical Reasoning. ArXiv, abs/2410.02884 .
