不可不知的 6 類 Clustering Algorithms
Clustering Algorithms | 聚類演算法 | K-means | Affinity Propagation | GMM | DBSCAN | BIRCH
不可不知的 6 類 Clustering Algorithms

在機器學習領域,Clustering Algorithms 因其在無監督學習場景中的實用性而廣受歡迎。 這些演算法旨在基於不同的相似性定義和方法學將資料點歸類為群集。 在我學習過程中做了一些筆記,主要將 Clustering Algorithms 分為六大類,以下跟大家介紹各類的概述及其細微差別。
1. 基於 “質心” 的聚類模型

k-means
基於質心的聚類的核心概念是圍繞著質心進行聚類 ,也就是一個中心資料點(不一定來自輸入資料集)進行聚類。 演算法如 KMeans、KMeans+ + 和KMedoids 以資料點與這些質心的接近程度為軸心,迭代調整群集以最小化群集內的方差,並最大化群集之間的方差,非常適合球狀或團狀的資料分佈。
成員
- KMeans : 透過最小化資料點與其各自群集質心之間的平方距離總和,將資料劃分為K個群集。 KMeans+ + : 在KMeans上的改進,它改進了質心初始化以獲得更好的收斂性。 KMedoids : 類似於KMeans,但使用實際資料點作為中心,使其對雜訊和異常值更加穩健。
應用場景:
- 市場區隔 : 基於顧客的購買歷史與行為數據,將顧客分為不同的市場區隔。
- 文件分類 : 將文件集合依文字內容的相似性分組。
優點:
- 易於實作 : KMeans 及其變種演算法邏輯簡單,容易理解與實作。
- 計算效率高 : 對於中等規模的資料集,這類演算法通常運作迅速,能夠在可接受的時間內得到結果。
缺點:
- 選擇K值 : KMeans 演算法需要預先指定K值(即聚類的數量),而在實際應用中,這個最佳 K 值往往是未知的,可能需要透過多次嘗試和評估來確定。
- 對初始質心敏感 : 尤其是 KMeans,演算法的結果可能對初始質心的選擇非常敏感,可能導致局部最佳解。
2. 基於 “連通性” 的聚類模型
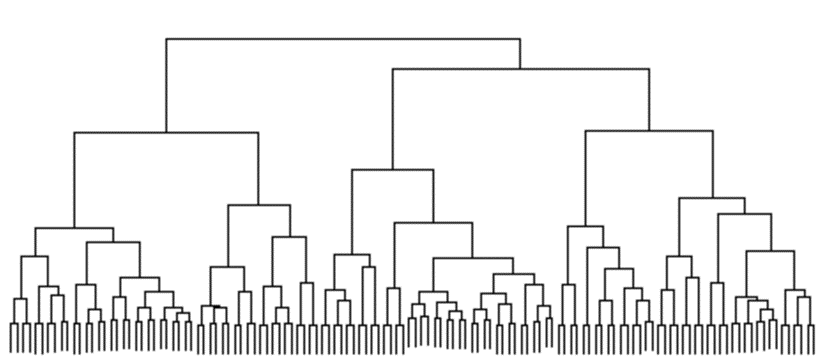
層次聚類
這種聚類類型,以層次聚類為例,基於資料點的距離連通性建立模型。 層次方法建構了樹狀圖,這是表示模式嵌套分組和相似性水準的樹狀結構。
成員
- 層次聚類 : 使用聚合(自下而上)或分裂(由上而下)方法,透過建立群集的層次結構來建立群集。
3. 基於 “密度” 的聚類模型
DBSCAN
與基於質心的方法相反,基於密度的聚類尋找被低密度區域分隔的高密度區域,將高密度區域連接成群集。 它能夠處理任意形狀的聚類,並且擅長排除噪聲點和識別異常值。
成員
- DBSCAN : 這是一種經典的密度聚類算法,將群集定義為高密度區域,由低密度區域分隔,並且能找到任意形狀的群集。
- OPTICS : DBSCAN 的擴展,能夠處理不同密度的資料,提供了一個聚類排序,從而在不同的尺度上展示數據的聚類結構。
- HDBSCAN : 一種較新的演算法,透過將 DBSCAN 單一距離測量轉化為層次聚類演算法,使其更適應不同密度的數據。
應用場景:
- 地理空間數據分析 : 能夠根據地理位置數據點的密集程度來識別人口密集區或者地貌特徵。
- 異常檢測 : 在各種應用場景中,如信用卡欺詐檢測或網絡安全中,用於識別不符合正常行為模式的異常點。
優點:
- 不需假設聚類形狀 : 能夠識別任意形狀的聚類,不像基於距離的算法那樣受限於球狀聚類。
- 免疫噪聲和異常值 : 相對於其他聚類方法,基於密度的算法能夠很好地識別並忽略噪聲和異常值。
缺點:
- 參數選擇 : DBSCAN和其變種算法對參數的設定非常敏感,如鄰域的大小和密度閾值,這可能影響聚類質量。
- 處理大規模數據集的計算復雜性 : 對於大型數據集,這些算法可能需要較長的計算時間,特別是在計算密度達到要求的區域時。
4. 基於 “圖” 的聚類模型

親和力傳播
這種演算法將數據點視為圖中的節點,通過節點間的相似度或距離來構建邊,進而在這個圖中識別出聚類結構。這類算法特別適合於揭示數據中的非線性結構,並能夠有效地處理高維數據。
成員
- 親和力傳播 : 這個算法通過在數據點之間傳遞信息來識別聚類中心,因此不需要確定或估計聚類的數量。
- 譜聚類 : 通過數據的相似度矩陣來進行維度降低,然後在降維後的空間進行聚類,這樣做對於識別複雜結構的聚類特別有效。
應用場景:
- 社交網絡分析 : 在社交網絡中,基於圖的聚類方法可以識別出社群結構或者潛在的利益小組。
- 生物信息學 : 在蛋白質互動網絡中,可以用來發現功能相關的蛋白質群組。
優點:
- 靈活性 : 基於圖的方法在處理任意形狀的聚類時非常有彈性,可以揭示數據中隱藏的非線性結構。
- 適應性: 對於不同尺度和密度的數據,這些方法能夠通過調整相似度函數來適應。
缺點:
- 計算複雜度 : 對於大規模數據集,基於圖的聚類方法可能需要大量的計算資源,特別是在構建和處理圖時。
- 參數選擇 : 這些方法對參數的選擇很敏感,例如選擇合適的相似度閾值或鄰域大小對於最終的聚類結果有很大的影響。
5. 基於 “分布” 的聚類模型

GMM
有別於其他基於距離或密度的聚類方法,基於分佈的聚類方法採用機率模型來描述資料分佈。 這種方法假設資料點是由多個機率分佈產生的,每個分佈對應一個群集。 透過估計這些分佈的參數,演算法能夠確定資料點屬於哪個分佈,從而實現聚類。 這種模型的優勢在於能夠處理不同形狀和大小的群集,並且能夠給出資料點屬於每個群集的機率,這對於某些應用來說非常有用。
成員
- 高斯混合模型(GMMs) : 聚類中最常見的演算法。 它假設所有的數據點都是由有限數量的高斯分佈混合產生的。 每個高斯分佈對應一個群集,並由其平均值和協方差定義。 透過使用最大似然估計或期望最大化(EM)演算法,可以估計出這些分佈的參數。 GMM不僅可以辨識出群集的中心,還能夠評估每個點屬於各個群集的不確定性,這是GMM的一個重要特性。
應用場景:
- 影像處理 : 在影像分割中,可以將像素點分配到不同的顏色組成的群集中。
- 生物資訊 : 在基因表現資料分析中,能夠幫助辨識出有相似表現模式的基因群集。
- 財務分析 : 在風險管理和市場區隔中,可以用來識別不同的客戶行為模式或投資組合的風險分佈。
優點:
- 彈性 : 能夠表示出群集的橢圓形狀,相較於 KMeans 這種核心聚類只能找出球形群集的演算法更有彈性。
- 軟聚類 : 提供的是每個資料點屬於每個群集的機率,這種「軟聚類」方法允許資料點被分配到多個群集中,這在許多現實世界的應用中是有意義的 。
缺點:
- 計算成本 : 由於需要估計每個組分的協方差矩陣,GMM在高維度資料上的計算成本可能非常高。
- 選擇組分數量 : 在實際應用中,如何確定混合組分的數量往往是一個挑戰,通常需要依賴模型選擇準則,如貝葉斯資訊準則(BIC)。
6. 基於 “壓縮” 的聚類模型

BIRCH
這類型的聚類模型關注於資料的降維和空間壓縮。 主要的核心思想是:高維度資料可以在低維度空間中以更簡潔的形式表示,而這個過程可以揭示資料的內在結構。 聚類過程在降維後的空間中進行,這有助於提高計算效率,同時可能發現在原始高維空間中不明顯的資料聚類結構。
成員
- BIRCH : 這種方法是為大規模資料集設計的一種聚類演算法,並能有效處理雜訊和異常值。。它以增量和動態的方式聚類輸入的多維度度量資料點,嘗試在可用資源(即記憶體和時間限制)條件下產生最佳品質的聚類結果。
應用場景:
- 大數據分析 : 在處理包含數百萬甚至數十億個資料點的資料集時,BIRCH 演算法能夠快速有效地辨識出資料的聚類結構。
- 影像壓縮 : 在影像處理中,可以使用 BIRCH 演算法對像素進行聚類,以實現影像的壓縮和簡化。
優點:
- 擴展性 : BIRCH 能夠處理非常大的資料集,同時保持較低的記憶體消耗。
- 可處理雜訊 : 由於其預處理步驟,BIRCH 能夠在最終聚類前識別並處理雜訊和異常值。
缺點:
- 對參數敏感 : BIRCH 中的閾值參數對最終的聚類結果有重要影響,不恰當的參數設定可能導致聚類效果不佳。
-
高維度資料的限制 : 雖然可以處理大規模數據,但其效果在高維度資料上可能會降低,因為高維空間中的距離度量變得不那麼可靠。
