LLM 評估教學 | EleutherAI LM Evaluation Harness
在上一篇文章中,我們探討了評估大型語言模型評估時應考慮的各項指標和細節。而這篇文章中,我們將深入探討如何具體操作去評估 LLM。這篇我們使用的工具框架是 EleutherAI 的 lm-evaluation-harness,以下會帶你一起實機操作。
LLM 評估教學 | EleutherAI LM Evaluation Harness

在 上一篇文章 中,我們探討了評估 LLM 時應考慮的各項指標和細節。而這篇文章中,我們將深入探討如何具體操作去評估 LLM。這篇我們使用的工具框架是 EleutherAI 的 lm-evaluation-harness ,這一工具不僅強大而且靈活,且已被多個組織參考進行後續開發,如 Hugging Face 在其 Open LLM Leaderboard 中便廣泛使用。
相信大家都看過 Hugging Face 的 Open LLM Leaderboard,該榜單提供了一個公開且透明的平台,來展示各個模型的性能表現。這榜單背後主要針對 6 個關鍵 benchmarks 進行評估,因此這篇也主要帶大家使用 lm-evaluation-harness 去評估這 6 大 benchmarks:
- AI2 Reasoning Challenge (ARC) — 25-shot: ARC 是一套小學科學問題集,旨在測試人工智能模型在科學推理方面的能力。
- HellaSwag — 10-shot: HellaSwag 是一個常識推理測試,對人類來說極其容易(大約95%的人能夠正確回答),但對於當前最先進的模型來說仍是一個挑戰。
- MMLU — 10-shot: MMLU測試旨在衡量文本模型在多任務準確性方面的表現。這個測試覆蓋了57項任務,包括小學數學、美國歷史、計算機科學、法律等。
- TruthfulQA — 0-shot: TruthfulQA是一個測量模型再現網絡上常見虛假信息傾向的測試。雖然在技術上,TruthfulQA 在 Harness 中是一個 6-shot 任務,因為即使在 0-shot 設定中,每個例子也會預加上 6 Q/A pairs。
- Winogrande — 5-shot: Winogrande 是一個大規模、具有對抗性且困難的 Winograd 基準測試,專注於常識推理。
- GSM8k — 5-shot: GSM8k 包含了多樣化的小學數學文字問題,旨在衡量模型解決多步驟數學推理問題的能力。
步驟1. Clone EleutherAI LM Evaluation Harness
到 lm-evaluation-harness 的 GitHub 將評估工具 clone 下來。
1
2
git clone https://github.com/EleutherAI/lm-evaluation-harness
cd lm-evaluation-harness
步驟2. 準備環境
推薦使用 conda 建立一個環境,你可以在 pyproject.toml 中找到要求的版本 python ≥ 3.8,與其將會安裝的 packages。
1
2
3
conda create -n LLM_evaluate python=3.8
conda activate LLM_evaluate
pip install -e .
步驟3. 工具介紹
lm-evaluation-harness 支援許多模型種類與商業模型,包含 HuggingFace Hub 上託管的模型,OpenAI、Anthropic 的 API,也有支援 Llama.cpp 或 vLLM 的接口,因此不論你是要評估已開放使用的 LLM 或個人 fine-tuning 後的 LLM,都可以使用這個工具。
該工具的參數非常多,可以參考其 Docs ,以下介紹幾個常用的:
- — model :選擇要評估的模型類型,如
hf,gguf,vllm,openai等。 - — model_args :模型的位置與參數,可用 huggingface 的倉庫名稱或本地的
./xxxxx等。這個參數可以接受1個以上,用,分隔即可。 - — tasks :決定哪些任務要評估,一樣可以接受一個以上。列表可以使用
lm-eval — tasks list查看。 - — device :使用的 GPU,要一個以上請使用
accelerate launcher或參數tensor_parallel_size - — batch_size :
auto代表自動選擇batch大小 - — output_path :結果儲存位置。
- — use_cache :緩存之前運行的結果,可以避免相同情境重複執行。
- — log_samples : 把評估的過程記錄下來,包括全部的 Prompt 和 ans。
步驟4. 開始評估
如上面提到 lm-evaluation-harness 支援許多模型種類,因此以下會針對幾個常見的例子示範,其他的使用可以以此類推:
- HuggingFace 託管的模型評估
- 本地 HF 模型
- 使用 llama.cpp 的模型
評估的 benchmarks 皆選用 HuggingFace 的 6 種指標,你可以使用以下指令查看 lm-evaluation-harness 支援的所有 task:
1
lm-eval --tasks list
4.1 對 HuggingFace 託管的模型評估
如果你想對 HuggingFace Hub (例如 GPT-J-6B或你自己的模型) 託管的模型進行評估,你可以使用以下指令:
1
2
3
4
5
6
7
lm_eval --model hf \
--model_args pretrained=EleutherAI/gpt-j-6B \
--tasks arc_challenge, hellaswag, mmlu, triviaqa, winogrande, gsm8k \
--device cuda:0 \
--batch_size auto \
--output_path ./eval_out/hf \
--use_cache ./eval_cache/hf
4.2 對本地 HF 模型評估
如果你的 hf model 儲存在電腦中,則可以使用以下:
1
2
3
4
5
6
7
lm_eval --model hf \
--model_args pretrained=./model_name \
--tasks arc_challenge, hellaswag, mmlu, triviaqa, winogrande, gsm8k \
--device cuda:0 \
--batch_size auto \
--output_path ./eval_out/local_hf \
--use_cache ./eval_cache/local_hf
4.3 對使用 llama.cpp 的模型評估
如果你一直都是使用 llama.cpp 的 gguf ,那麼我們需要先將 API 開起來,之前 llama.cpp 的 教學 中有提到,可以使用 llama.cpp 內建的 ./server 快速架設 HTPP API,但這目前在 lm-evaluation-harness 不支援,因此我們需要使用 llama-cpp-python 來架設 API,主要有3步驟:
I. 切換環境 (可以另開一個tab進行)
1
conda activate llamaCpp
II. 安裝 llama-cpp-python
1
pip install 'llama-cpp-python[server]'
III. 啟動 server
1
python3 -m llama_cpp.server --model models_name.gguf
這樣便成功啟用 llama-cpp-python 幫你架設 API,URL 在 http://localhost:8000 與原始 llama.cpp 的 http://localhost:8080 不一樣,可以注意一下。
之後就可以使用以下指令進行評估:
1
2
3
4
5
6
7
8
lm_eval \
--model gguf \
--model_args base_url=http://localhost:8000 \
--tasks arc_challenge, hellaswag, mmlu, triviaqa, winogrande, gsm8k \
--device cuda:0 \
--batch_size auto \
--output_path ./eval_out/llamacpp \
--use_cache ./eval_cache/llamacpp
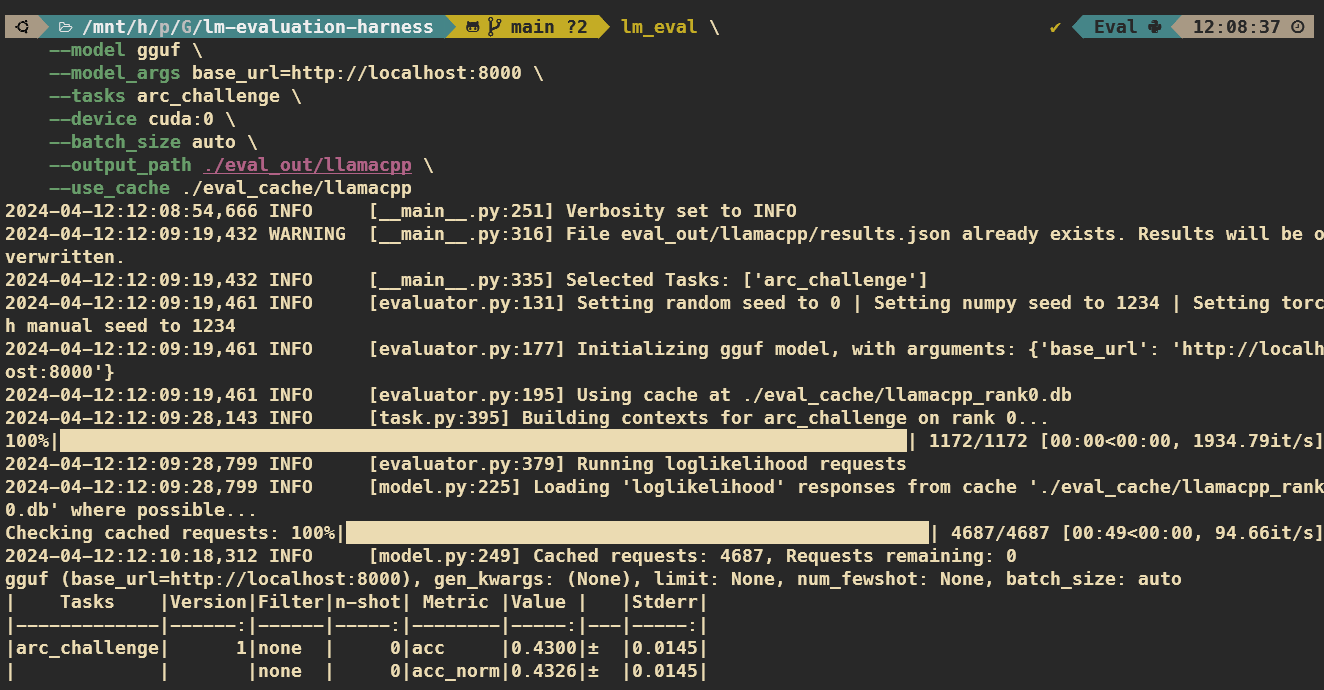
實機畫面
步驟5. 使用 Weights & Biases 紀錄結果
lm-evaluation-harness 支援使用 Weights & Biases(W&B),W&B 是一個機器學習實驗追蹤、視覺化和管理的平台。它被廣泛用於記錄機器學習模型的訓練過程,用於比較不同模型的性能,在這邊則是讓你可以很好的追蹤評估結果。
要使用 W&B 只需要加入 wandb_args 參數即可, project 輸入你在 W&B 中的專案名稱。
1
2
3
4
5
6
7
8
9
10
lm_eval \
--model gguf \
--model_args base_url=http://localhost:8000 \
--tasks arc_challenge, hellaswag, mmlu, triviaqa, winogrande, gsm8k \
--device cuda:0 \
--batch_size auto \
--output_path ./eval_out/llamacpp \
--use_cache ./eval_cache/llamacpp \
--wandb_args project=llm_eval_benchmark \
--log_samples
接下來 W&B 會提供我們三個選項:
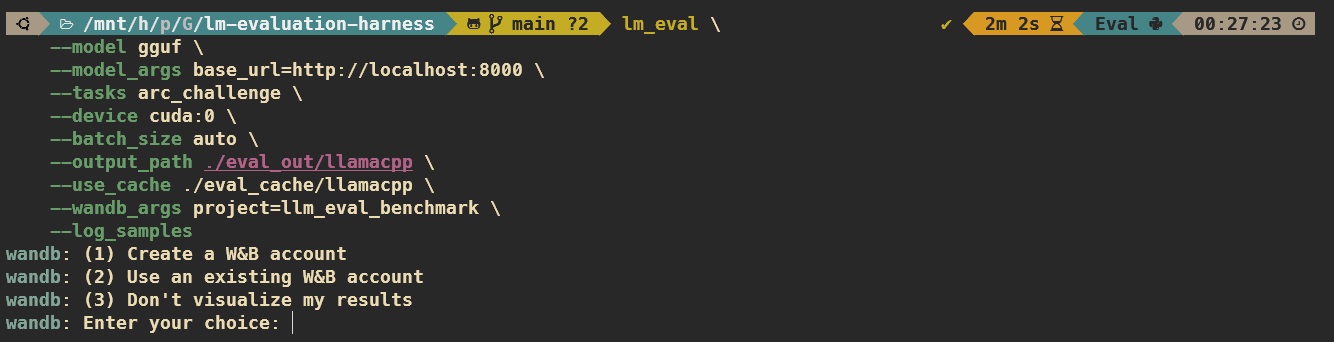
1. Create a W&B account: 如果你沒有 W&B 帳戶,選擇這個選項會引導你到 W&B官網 註冊,接遮辦好後就可以拿到 API KEY,再回來輸入即可。

2. Use an existing W&B account: 如果你已經有 W&B 帳戶,那麼跟著指示走就可以拿到你的 API KEY,假設你在 (1) Create a W&B account 找不到 API KEY 的話,可以用這邊的引導拿到。

3. Don’t visualize my results: 如果你不想註冊登入,你還是可以正常使用 W&B 紀錄結果,結果會儲存在 local,只是不能用網站的視覺化功能察看。
備註:你的 API KEY 會保存在 ~/.netrc 中,下次使用就不需要再選 3 個選項,但如果你想換帳戶的話,可以把文件刪掉重來。
輸入完 API KEY 後系統就會自動開始評估,等評估完後,你的結果會直接同步到 W&B。
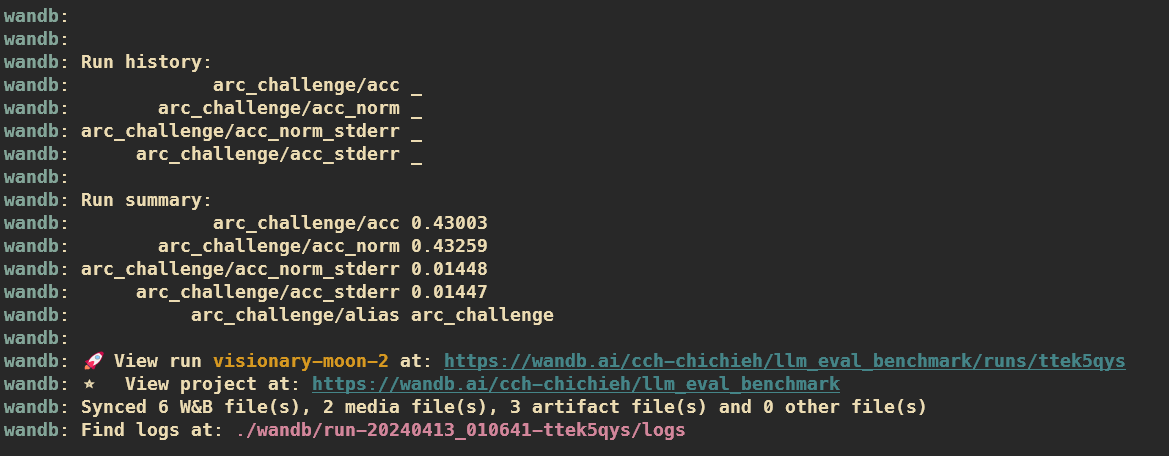
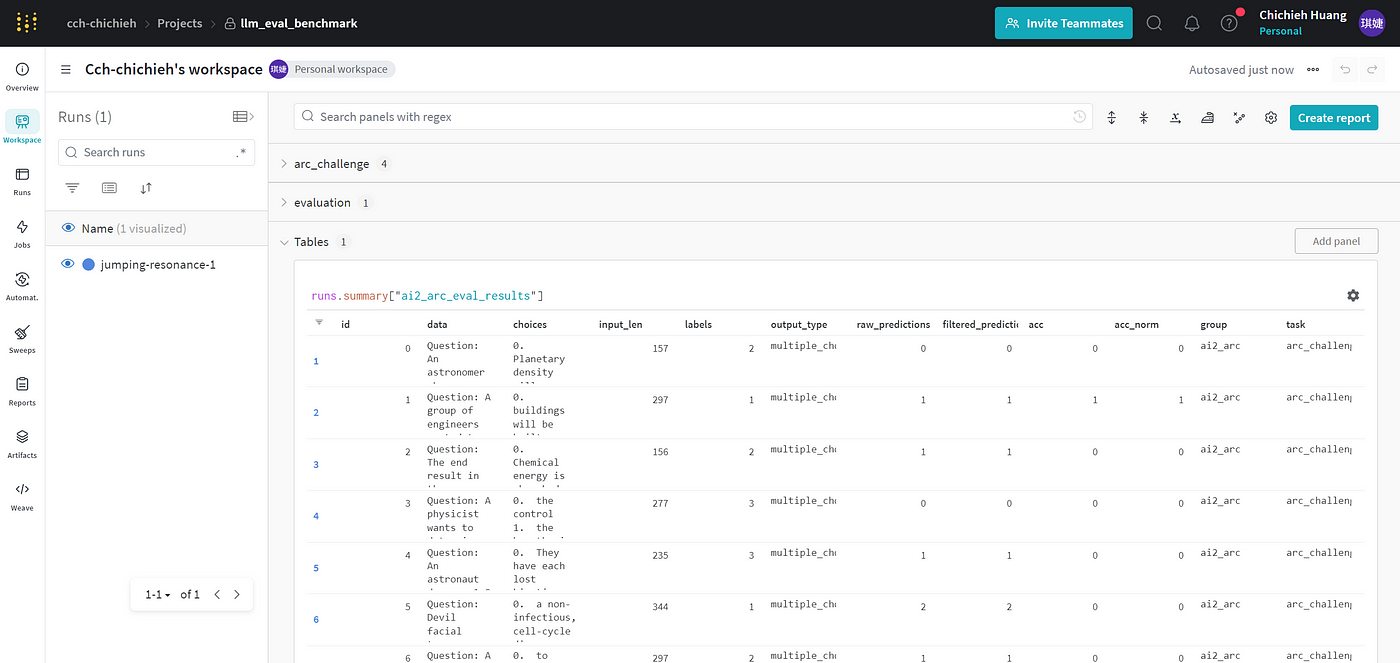
接著你可以用上面的連結進到你的 W&B Project 中,結果已經視覺化呈現在網站上。
結論
lm-evaluation-harness 是一個很好用的工具,提供了一個強大且靈活的平台,可以評估各種不同的模型,非常適合一般使用者進行實驗和研究,希望透過這篇教學能讓你快速評估你的模型。
另外,除了 lm-evaluation-harness 外,市面上還有許多其他專門為 LLM 評估設計的框架,例如 LangChain 的 LangSmith、confidence-ai 的 DeepEval、TruEra 等。這些工具和框架各有千秋,你可以根據自己的具體需求和模型特性選擇最適合的評估工具。
